第12回講義資料
交互作用
スライド
セットアップ
本日の実習用データ(LMSからダウンロード可能)と必要なパッケージ({tidyverse}、{summarytools}、{marginaleffects})を読み込む。ただし、{marginaleffects}がインストールされていない場合は、コンソール上にinstall.packages("marginaleffects")を入力し、インストールしておくこと。
交互作用とは
以下の図のように主な説明変数(\(X\))と応答変数(\(Y\))の関係において、\(X\)が\(Y\)に与える影響がその他の変数(\(Z\))の影響を受ける場合を考えてみよう。
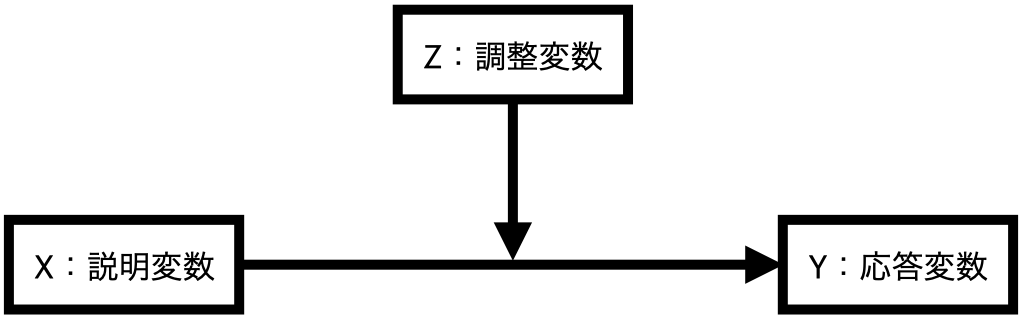
これは\(X\)が\(Y\)に与える影響は一定ではないことを意味する(= \(X\)が\(Y\)に与える影響は\(Z\)に依存する)。ここで、\(Z\)は調整変数 (moderation variable; moderator)と呼ばれる。調整変数はダミー変数でも、連続変数でも可能だ。
この交互作用を実際の回帰式として表すと以下のようになる。
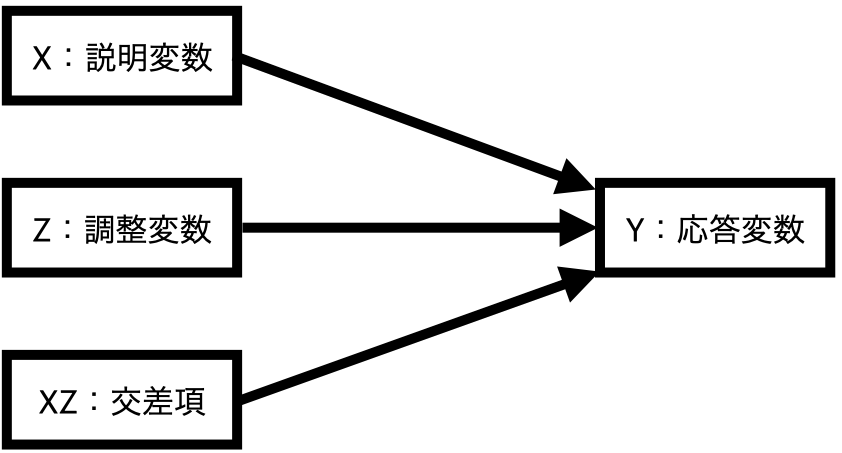
\[ \hat{Y} = \alpha + \beta_1 X + \beta_2 Z + \beta_3 X \cdot Z \tag{1}\]
ここで説明変数に調整変数をかけた変数(\(X \cdot Z\))は交差項 (interaction term)と呼ばれる。これまでの(重)回帰分析では変数\(X\)が\(Y\)に与える効果は\(\beta_1\)であると解説したが、回帰式に交差項が含まれている場合は解釈に注意が必要だ。なぜなら回帰式において\(X\)は\(\beta_3\)にも登場するからである。これは 式 1 を変形してみると分かりやすい。
\[ \hat{Y} = \alpha + (\beta_1 + \beta_3 Z) X + \beta_2 Z \tag{2}\]
式 2 によると、変数\(X\)が\(Y\)に与える効果、つまり\(X\)の傾き係数は\(\beta_1\)でなく、\(\beta_1 + \beta_3 Z\)だということが分かる。交互作用を仮定したモデルに解釈はやや面倒ではないが、難しい数式が登場するわけではない。ここでは調整変数がダミー変数の場合と連続変数の場合の例を紹介する。
まず、調整変数\(Z\)が0、または1の値のみをとるダミー変数の場合(\(Z \in \{0, 1\}\))だ。回帰分析の結果、以下のような1次関数が得られたとしよう。
\[ \begin{align} \hat{Y} & = 3 + 2 X + 1 Z + 3 X \cdot Z \\ & = 3 + (2 + 3Z) X + 1 Z \end{align} \tag{3}\]
解釈する場合は\(Z = 0\)の場合と\(Z = 1\)の場合に分けて解釈する。まず、\(Z = 0\)の場合、\(\hat{Y} = 3 + (2 + 3\cdot0) X + 1 Z = 3 + 2X + 1Z\)となり、\(X\)が\(Y\)に与える影響は2となる。一方、\(Z = 1\)の場合は\(\hat{Y} = 3 + (2 + 3\cdot1) X + 1 Z = 3 + 5X + 1Z\)となり、\(X\)が\(Y\)に与える影響は5となる。これを可視化すると以下のようになる。
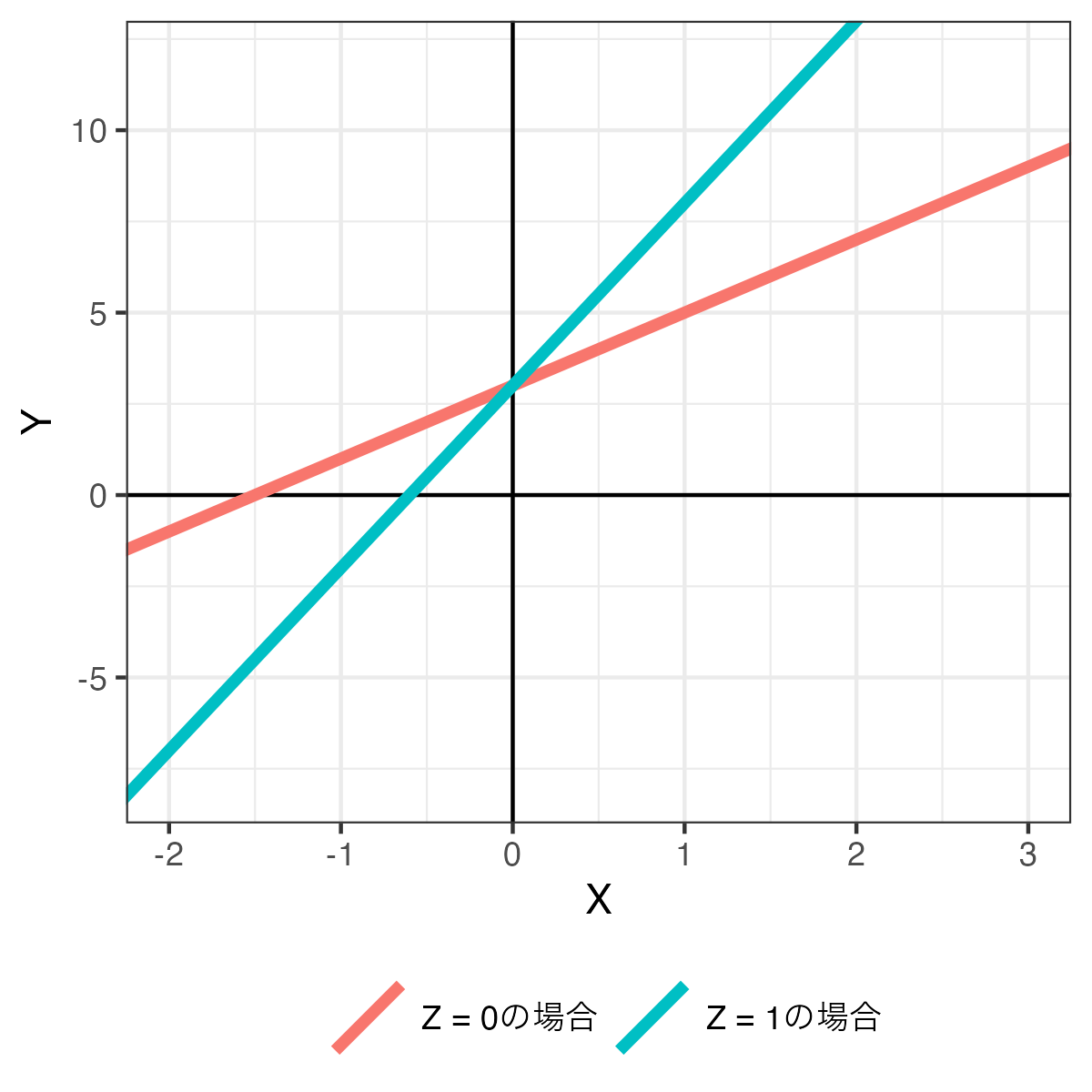
調整変数\(Z\)が0になると傾きが2の回帰直線(赤)が、1になると傾きが5の回帰直線(青)が得られる。
続いて、調整変数\(Z\)が無数の値をとる連続変数の場合を考えてみよう。回帰分析の結果、以下のような1次関数が得られたとしよう。
\[ \begin{align} \hat{Y} & = 2 + 3 X + 2 Z - 1 X \cdot Z \\ & = 2 + (3 - 1Z) X + 2 Z \end{align} \tag{4}\]
ここで\(Z = -1\)の場合、\(\hat{Y} = 2 + (3 - 1\cdot(-1)) X + 2 Z = 3 + 4X + 1Z\)となり、\(X\)が\(Y\)に与える影響は4となる。また、\(Z = 2\)の場合は\(\hat{Y} = 2 + (3 - 1\cdot2) X + 2 Z = 3 + 1X + 1Z\)となり、\(X\)が\(Y\)に与える影響は1となる。\(Z\)が3.5の場合は\(\hat{Y} = 2 + (3 - 1\cdot3.5) X + 2 Z = 3 - 0.5X + 1Z\)となり、\(X\)が\(Y\)に与える影響は-0.5となる。これを可視化すると以下のようになる。
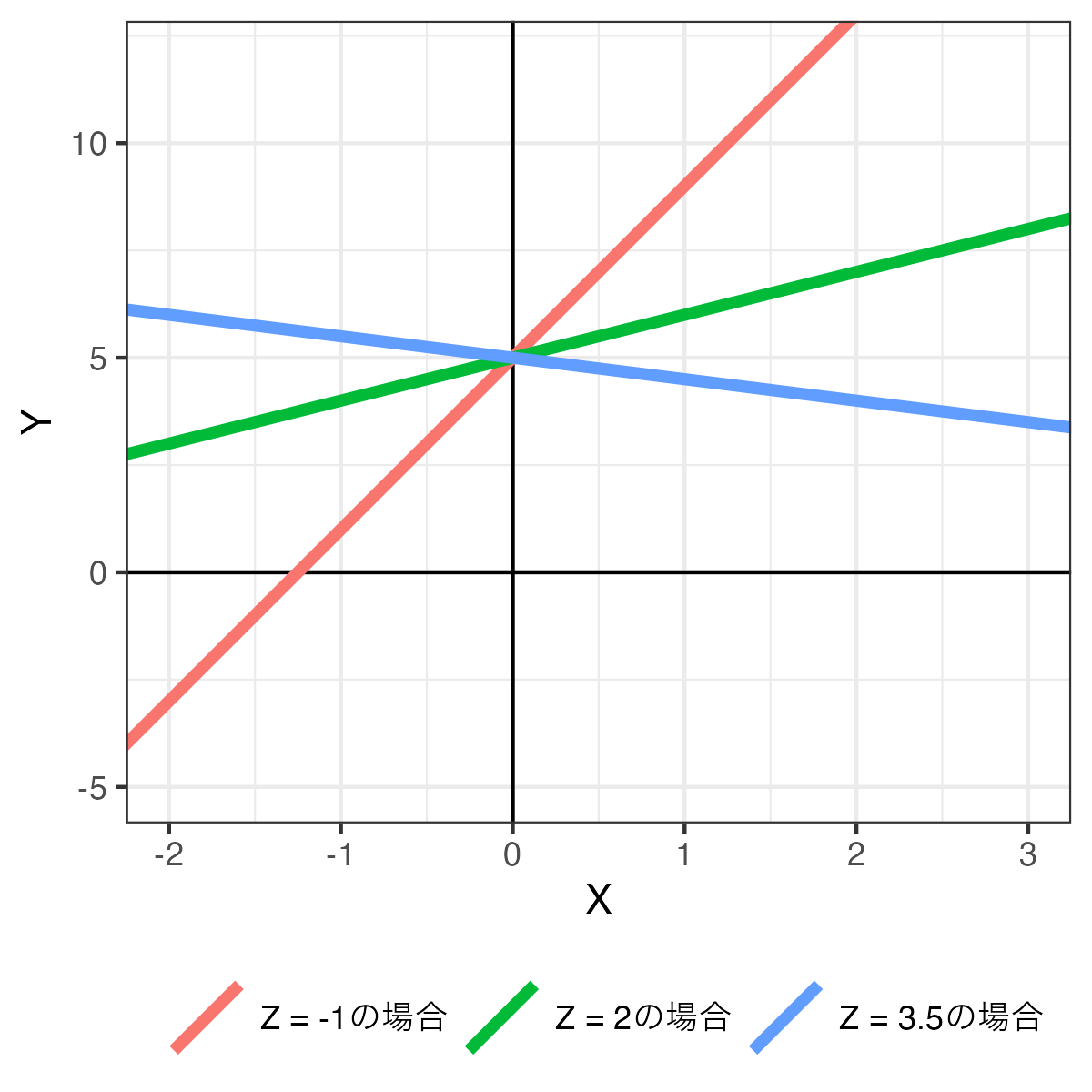
ただし、調整変数が連続変数の場合は、-1、2、3.5以外の値を取ることもできる。\(Z\)が取り得るすべての値に対して回帰直線を計算することは出来ないため、いくつかの代表的な値に絞って計算する必要があろう。
推定
それでは実際に推定してみよう。まず、実習データの中身を確認してみる。
# A tibble: 3,000 × 6
TempKyosan Female Age Satisfaction Interest Ideology
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 20 1 69 4 4 9
2 20 1 47 1 1 7
3 0 1 37 3 3 11
4 0 0 51 4 3 11
5 20 0 38 2 3 7
6 0 0 71 5 4 11
7 10 0 47 3 3 9
8 0 0 71 4 4 11
9 25 0 75 3 4 9
10 40 1 66 2 3 6
# ℹ 2,990 more rows各変数の説明は以下の通りだ。
| 変数 | 説明 | 備考 |
|---|---|---|
TempKyosan |
日本共産党に対する感情温度 | 高いほど好感 |
Female |
女性ダミー | 0: 男性 / 1: 女性 |
Age |
回答者の年齢 | |
Satisfaction |
政治満足度 | 高いほど満足 |
Interest |
回答者の政治関心 | 高いほど関心あり |
Ideology |
回答者のイデオロギー | 高いほど保守的 |
データ分析の前にjes_dfの記述統計量を確認する。今回のデータはすべて連続変数扱いとなるため、前処理は不要だ。性別は名目変数であるが、既にダミー変数に変換済みである。ダミー変数の記述統計量は連続変数と同じ扱いで問題ないため、データをそのまま{summarytools}パッケージのdescr()関数に渡せば良い。
Code 03
Descriptive Statistics
jes_df
N: 3000
Mean Std.Dev Min Max N.Valid
------------------ ------- --------- ------- -------- ---------
TempKyosan 26.88 24.95 0.00 100.00 3000.00
Female 0.50 0.50 0.00 1.00 3000.00
Age 47.34 15.63 18.00 75.00 3000.00
Satisfaction 2.45 1.08 1.00 5.00 3000.00
Interest 2.74 0.83 1.00 4.00 3000.00
Ideology 6.34 2.10 1.00 11.00 3000.00このデータを用い、以下の問いに答えるとする。
政治満足度が共産党に対する感情温度に与える影響を調べたい。ただし、この影響は一定ではなく、性別や年齢によって異なるかも知れない。政治満足度が共産党に対する感情温度に与える影響の不均一性を調べるためにはどうすれば良いだろうか。仮説検定に使用する有意水準は5%とする(\(\alpha = 0.05\))。
この問いにおける応答変数は「共産党に対する感情温度(TempKyosan)」、主な説明変数は「政治満足度(Satisfaction)」だ。ただし、政治満足度が共産感情温度に与える影響は性別(Female)や年齢(Age)に依存する可能性がある。調整変数が2つであるため、ここでは2つのモデルを作成する。
モデル1
| 種類 | 変数 | 変数名 |
|---|---|---|
| 主な説明変数 | 政治満足度 | Satisfaction |
| 応答変数 | 共産党に対する感情温度 | TempKoysan |
| 調整変数 | 女性ダミー | Female |
| 統制変数 | 政治関心、イデオロギー、年齢 | Interest、Ideology、Age |
モデル2
| 種類 | 変数 | 変数名 |
|---|---|---|
| 主な説明変数 | 政治満足度 | Satisfaction |
| 応答変数 | 共産党に対する感情温度 | TempKoysan |
| 調整変数 | 年齢 | Age |
| 統制変数 | 政治関心、イデオロギー、女性ダミー | Interest、Ideology、Female |
モデル1は政治満足度(= 説明変数)が共産党に対する感情温度(= 応答変数)に与える影響は性別(= 調整変数)に依存することを意味し、以下のような図として表現できる。
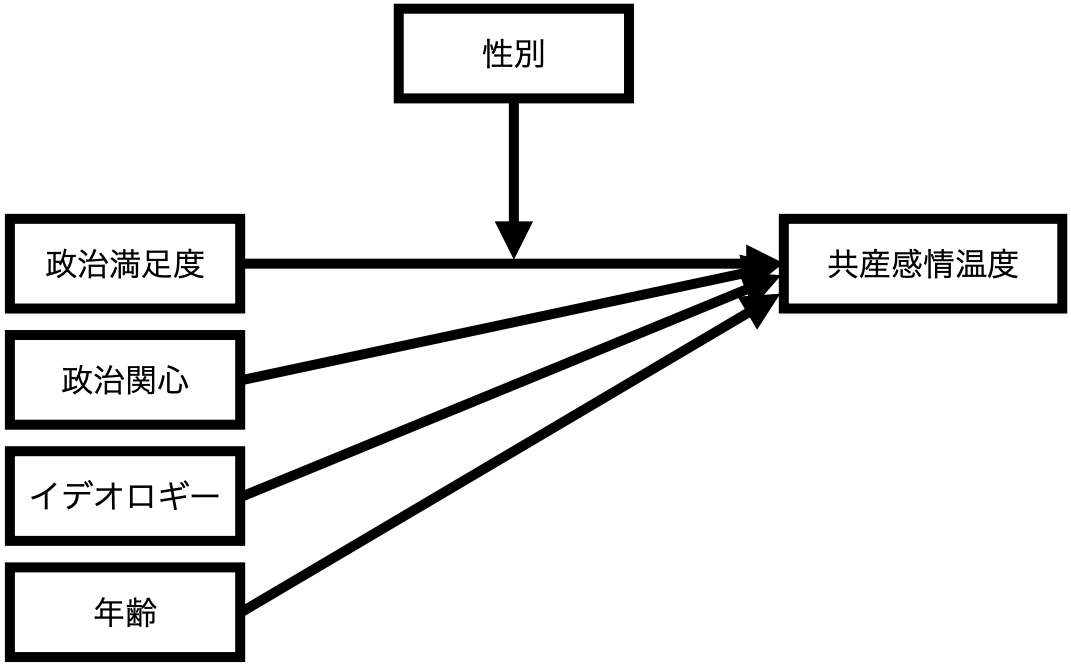
これを回帰式にする場合、 式 5 のような1次関数になる(以下の図参照)。
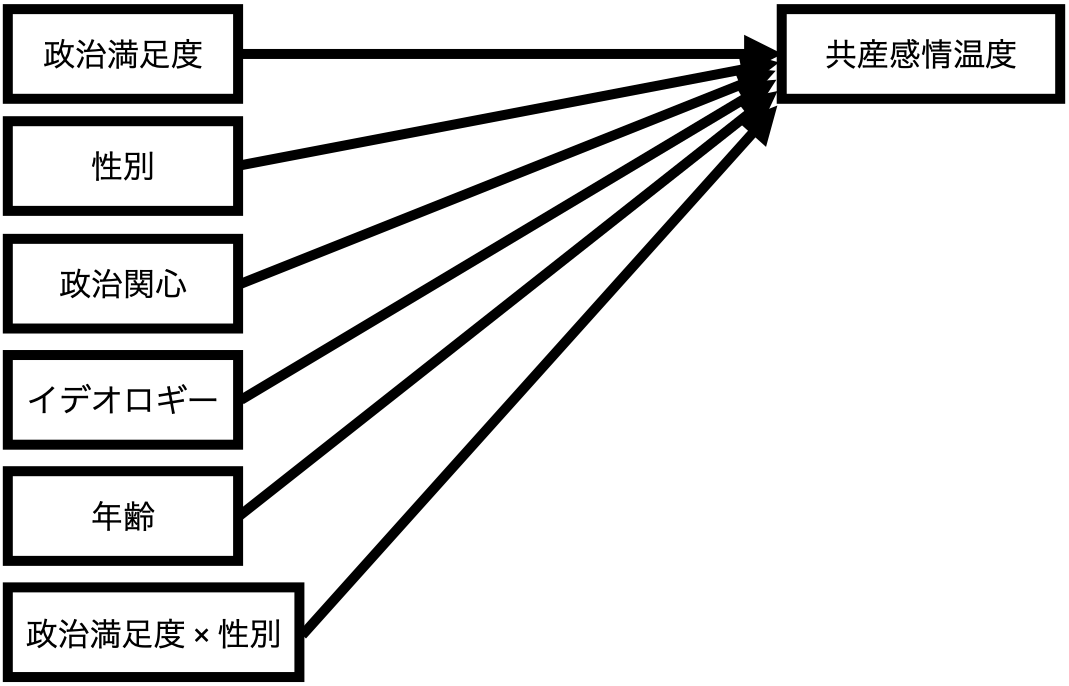
\[ \widehat{\mbox{TempKyosan}} = \alpha + \beta_1 \mbox{Satisfaction} + \beta_2 \mbox{Female} + \beta_3 \mbox{Interest} + \beta_4 \mbox{Ideology} + \beta_5 \mbox{Age} + \beta_6 (\mbox{Satisfaction} \cdot \mbox{Female}) \tag{5}\]
つづいて、モデル2は政治満足度(= 説明変数)が共産党に対する感情温度(= 応答変数)に与える影響は年齢(= 調整変数)に依存することを意味し以下のような図として表現できる。
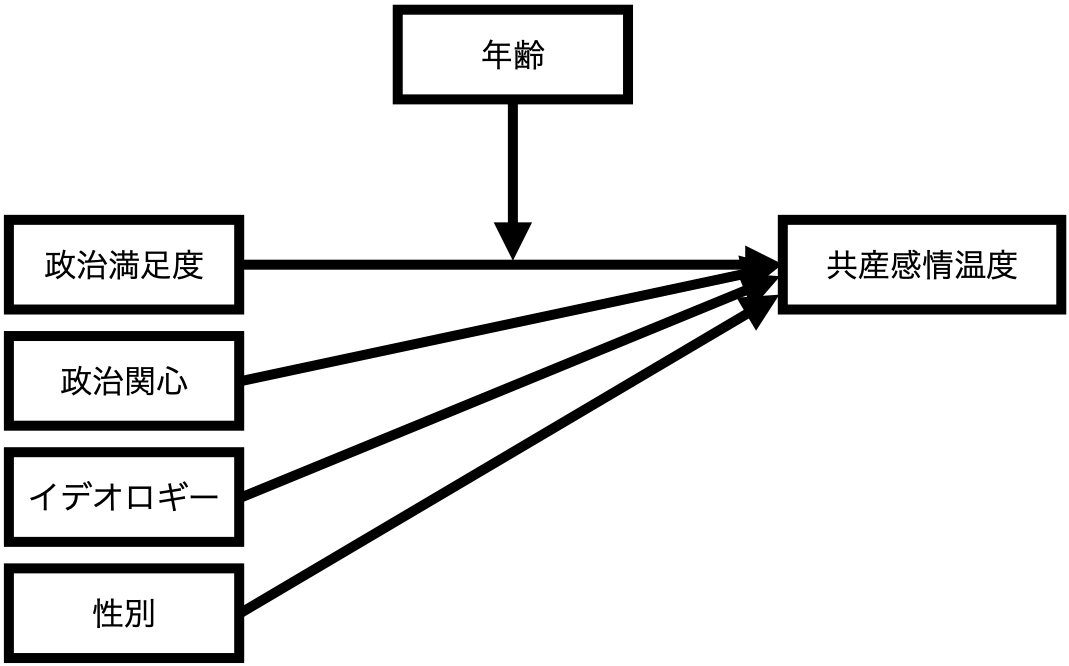
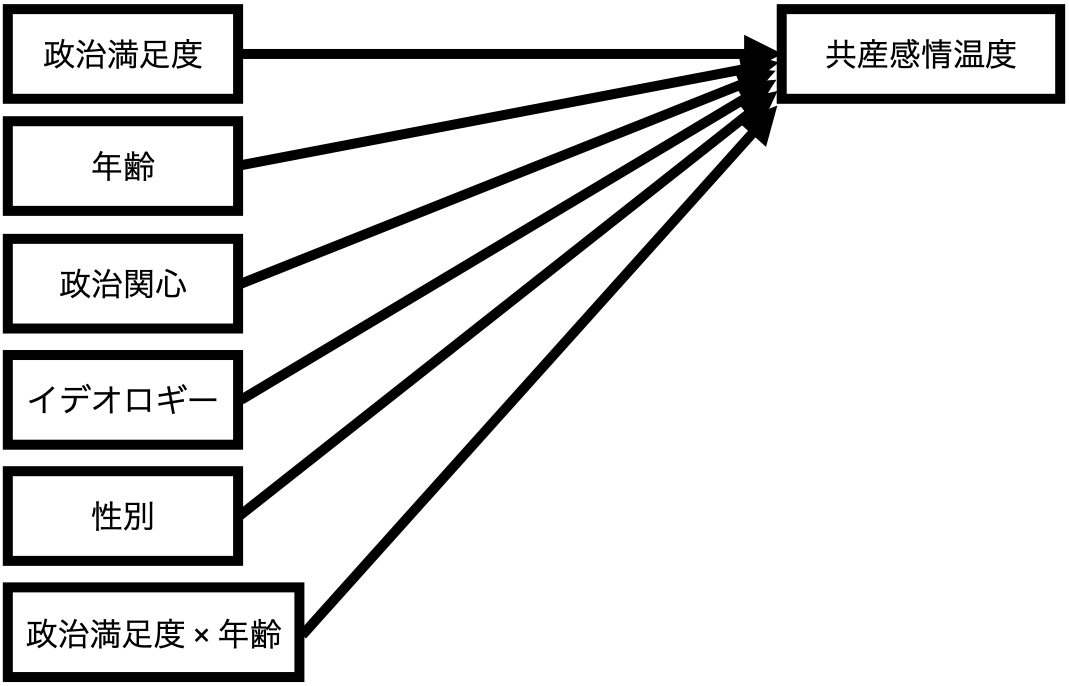
これを回帰式にする場合、 式 6 のような1次関数になる(以下の図参照)。
\[ \widehat{\mbox{TempKyosan}} = \alpha + \beta_1 \mbox{Satisfaction} + \beta_2 \mbox{Age} + \beta_3 \mbox{Interest} + \beta_4 \mbox{Ideology} + \beta_5 \mbox{Female} + \beta_6 (\mbox{Satisfaction} \cdot \mbox{Age}) \tag{6}\]
推定にはこれまでと同様、lm()関数を使用する。注意するところは第1引数である回帰式(formula)であり、交互作用が存在すると考えられる2つの変数を+でなく、*でつなぐだけだ。ここでA * Bの意味はA\(\times\)bだけでなく、A、B、A\(\times\)Bが同時に投入することを意味する。
モデル1と2をそれぞれfit1、fit2に格納する。
2つのモデルの推定結果を横に並べるために{modelsummary}とmodelsummary()関数を使用する。2つのモデルオブジェクトはlist()関数でまとめることを忘れずに。
| (1) | (2) | |
|---|---|---|
| (Intercept) | 49.275 | 28.250 |
| (<0.001) | (<0.001) | |
| Satisfaction | -4.732 | 3.308 |
| (<0.001) | (0.015) | |
| Female | 2.752 | 5.061 |
| (0.208) | (<0.001) | |
| Interest | 0.217 | -0.118 |
| (0.703) | (0.836) | |
| Ideology | -1.887 | -1.690 |
| (<0.001) | (<0.001) | |
| Age | -0.040 | 0.357 |
| (0.178) | (<0.001) | |
| Satisfaction × Female | 0.902 | |
| (0.270) | ||
| Satisfaction × Age | -0.157 | |
| (<0.001) | ||
| Num.Obs. | 3000 | 3000 |
| R2 | 0.086 | 0.096 |
| R2 Adj. | 0.084 | 0.094 |
| AIC | 27560.1 | 27526.4 |
| BIC | 27608.1 | 27574.4 |
| Log.Lik. | -13772.027 | -13755.176 |
| F | 46.763 | 52.927 |
| RMSE | 23.85 | 23.72 |
モデル1の解釈
モデル1(fit1)から得られた回帰式は以下の通りである。
共産に対する感情温度の予測値 = 49.28 - 4.73 \(\times\) 政治満足度 + 2.75 \(\times\) 女性ダミー + 0.22 \(\times\) 政治関心 - 1.89 \(\times\) イデオロギー - 0.04 \(\times\) 年齢 + 0.90 \(\times\) 政治満足度 \(\times\) 女性ダミー
これを政治満足度でまとめると、
共産に対する感情温度の予測値 = 49.28 - (4.73 - 0.90 \(\times\) 女性ダミー) \(\times\) 政治満足度 + 2.75 \(\times\) 女性ダミー + 0.22 \(\times\) 政治関心 - 1.89 \(\times\) イデオロギー - 0.04 \(\times\) 年齢
になる。つまり、政治満足度が共産感情温度に与える影響は「-(4.73 - 0.90 \(\times\) 女性ダミーの値)」だ。女性ダミーが取り得る値は0(男性)か1(女性)しかないので、ここでは2つのケースにおける政治満足度が共産感情温度に与える影響を計算してみよう。
まず、男性の場合(Femaleの値 = 0)、政治満足度が共産感情温度に与える影響は約-4.73(= -(4.73 - 0.90 \(\times\) 0) )である。これは男性の場合、政治満足度が上がると共産感情温度が下がることを意味し、具体的には「男性の場合、政治満足度が1単位上がると、共産に対する感情温度は約4.73度下がる」と解釈できる。また、女性の場合(Femaleの値 = 1)、政治満足度が共産感情温度に与える影響は約-3.83(= -(4.73 - 0.90 \(\times\) 1) )である。これもまた、女性の場合、政治満足度が上がると共産感情温度が下がることを意味し、具体的には「女性の場合、政治満足度が1単位上がると、共産に対する感情温度は約3.83度下がる」と解釈できる。
以上の結果を可視化してみよう。まず、{marginaleffects}パッケージのpredictions()関数で予測値を計算する。今回はSatisfactionとFemaleが取りうるすべての組み合わせに応じて予測値を計算する必要がある。つまり、datagrid()内には主な説明変数(Satisfaction)だけでなく、調整変数(Female)の値も指定する必要がある。
Code 06
Satisfaction Female Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 % Interest Ideology Age
1 0 31.3 1.048 29.85 <0.001 647.8 29.22 33.3 2.74 6.34 47.3
1 1 34.9 1.057 33.05 <0.001 793.3 32.85 37.0 2.74 6.34 47.3
2 0 26.5 0.685 38.75 <0.001 Inf 25.20 27.9 2.74 6.34 47.3
2 1 31.1 0.668 46.55 <0.001 Inf 29.78 32.4 2.74 6.34 47.3
3 0 21.8 0.686 31.78 <0.001 733.8 20.46 23.2 2.74 6.34 47.3
3 1 27.3 0.723 37.72 <0.001 Inf 25.85 28.7 2.74 6.34 47.3
4 0 17.1 1.050 16.26 <0.001 195.1 15.02 19.1 2.74 6.34 47.3
4 1 23.4 1.160 20.20 <0.001 299.1 21.16 25.7 2.74 6.34 47.3
5 0 12.3 1.538 8.03 <0.001 49.8 9.33 15.4 2.74 6.34 47.3
5 1 19.6 1.707 11.48 <0.001 99.0 16.26 22.9 2.74 6.34 47.3
Type: response
Columns: rowid, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high, Interest, Ideology, Age, Satisfaction, Female, TempKyosan 続いて、fit1_predのFemale列を修正しよう。0/1だと読者側から見れば読みにくいので、Female列の値が1であれば「女性」、その他の場合は「男性」にリコーディングしよう。
Estimate Std. Error z Pr(>|z|) S CI low CI high
31.3 1.048 29.85 <0.001 647.8 29.22 33.3
34.9 1.057 33.05 <0.001 793.3 32.85 37.0
26.5 0.685 38.75 <0.001 Inf 25.20 27.9
31.1 0.668 46.55 <0.001 Inf 29.78 32.4
21.8 0.686 31.78 <0.001 733.8 20.46 23.2
27.3 0.723 37.72 <0.001 Inf 25.85 28.7
17.1 1.050 16.26 <0.001 195.1 15.02 19.1
23.4 1.160 20.20 <0.001 299.1 21.16 25.7
12.3 1.538 8.03 <0.001 49.8 9.33 15.4
19.6 1.707 11.48 <0.001 99.0 16.26 22.9
Columns: rowid, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high, Interest, Ideology, Age, Satisfaction, Female, TempKyosan これまで普通に表示されていたFemale列が見えなくなった。これは{marginaleffects}の仕様上の問題だが、print()関数の中にstyle = "data.frame"を指定すると問題なく表示される。
rowid estimate std.error statistic p.value s.value conf.low conf.high Interest Ideology
1 1 31.26953 1.0476813 29.846411 9.772659e-196 647.80916 29.216108 33.32294 2.736333 6.340667
2 2 34.92279 1.0566914 33.049183 1.598219e-239 793.26435 32.851710 36.99386 2.736333 6.340667
3 3 26.53784 0.6849277 38.745466 0.000000e+00 Inf 25.195410 27.88028 2.736333 6.340667
4 4 31.09269 0.6679048 46.552569 0.000000e+00 Inf 29.783616 32.40176 2.736333 6.340667
5 5 21.80616 0.6861641 31.779807 1.230741e-221 733.84658 20.461305 23.15102 2.736333 6.340667
6 6 27.26258 0.7226681 37.724905 0.000000e+00 Inf 25.846181 28.67899 2.736333 6.340667
7 7 17.07448 1.0501055 16.259777 1.904310e-59 195.06449 15.016312 19.13265 2.736333 6.340667
8 8 23.43248 1.1597646 20.204515 8.934294e-91 299.13610 21.159385 25.70558 2.736333 6.340667
9 9 12.34280 1.5377994 8.026273 1.004781e-15 49.82204 9.328767 15.35683 2.736333 6.340667
10 10 19.60238 1.7071942 11.482220 1.620642e-30 98.96128 16.256341 22.94842 2.736333 6.340667
Age Satisfaction Female TempKyosan
1 47.34 1 男性 20
2 47.34 1 女性 20
3 47.34 2 男性 20
4 47.34 2 女性 20
5 47.34 3 男性 20
6 47.34 3 女性 20
7 47.34 4 男性 20
8 47.34 4 女性 20
9 47.34 5 男性 20
10 47.34 5 女性 20 問題なくFemale列がリコーディングされていることが分かる。それではこのfit1_predを利用し、可視化してみよう。ここではpoint-rangeプロットを作成し、性別に応じてpoint-rangeの色分けを行う。また、性別ごとのpoint-rangeを横方向にずらすためにaes()の外側にposition = position_dodge2(0.5)を追加する。この0.5の数値が小さいほど2つのpoint-rangeはより近くなる。
Code 09
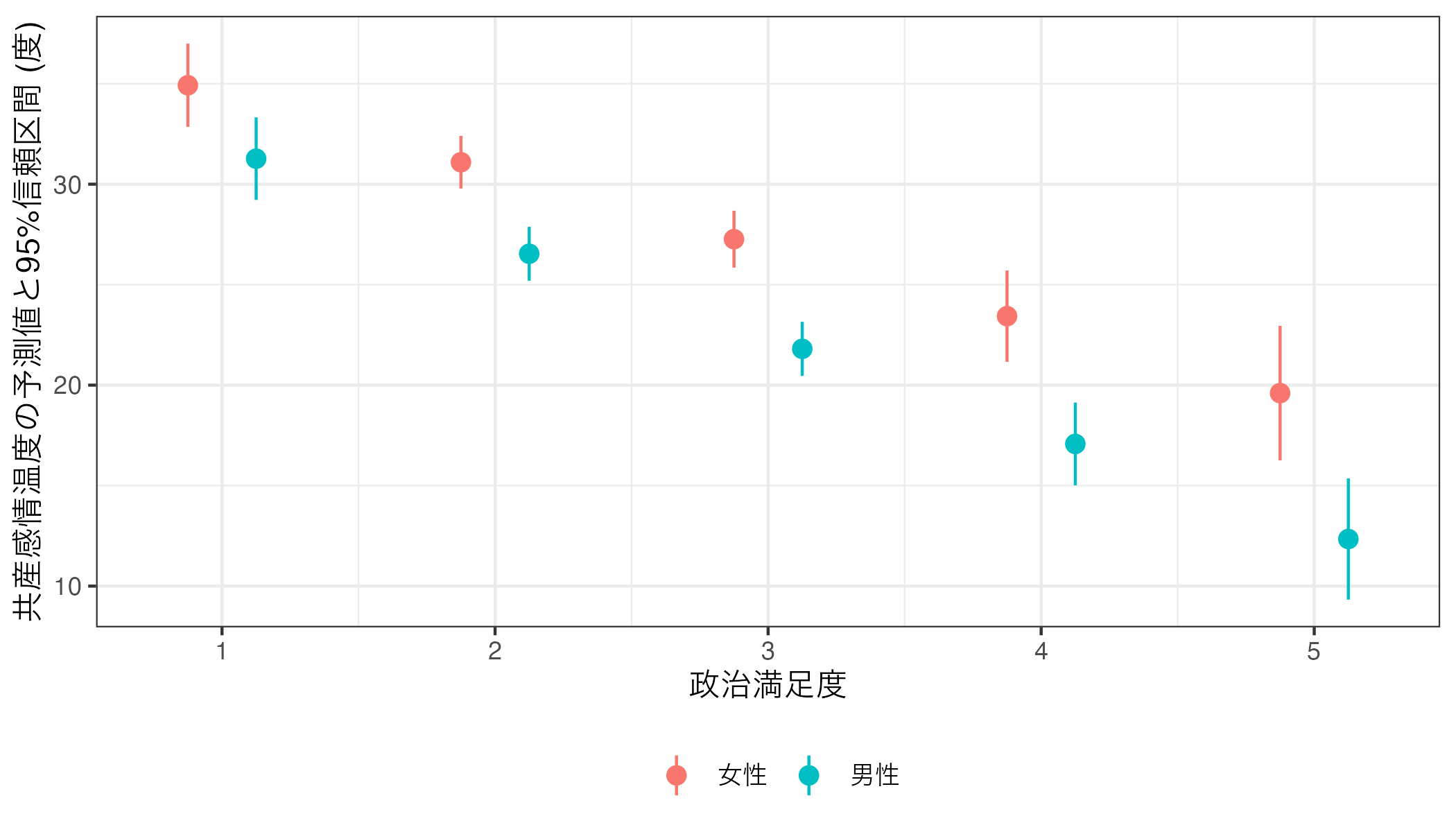
もう一つの可視化方法はリボンと折れ線グラフの組み合わせである。リボンの色塗りはfillでマッピングし、リボンが重なる可能性を考慮しaes()の外側にalpha引数を追加して透明度を調整しよう。宋のおすすめは0.3だ。
Code 10
fit1_pred |>
ggplot(aes(x = Satisfaction)) +
geom_ribbon(aes(y = estimate, ymin = conf.low, ymax = conf.high, fill = Female),
alpha = 0.3) +
geom_line(aes(y = estimate, color = Female), linewidth = 1) +
labs(x = "政治満足度", y = "共産感情温度の予測値と95%信頼区間 (度)",
fill = "", color = "") +
theme_bw() +
theme(legend.position = "bottom")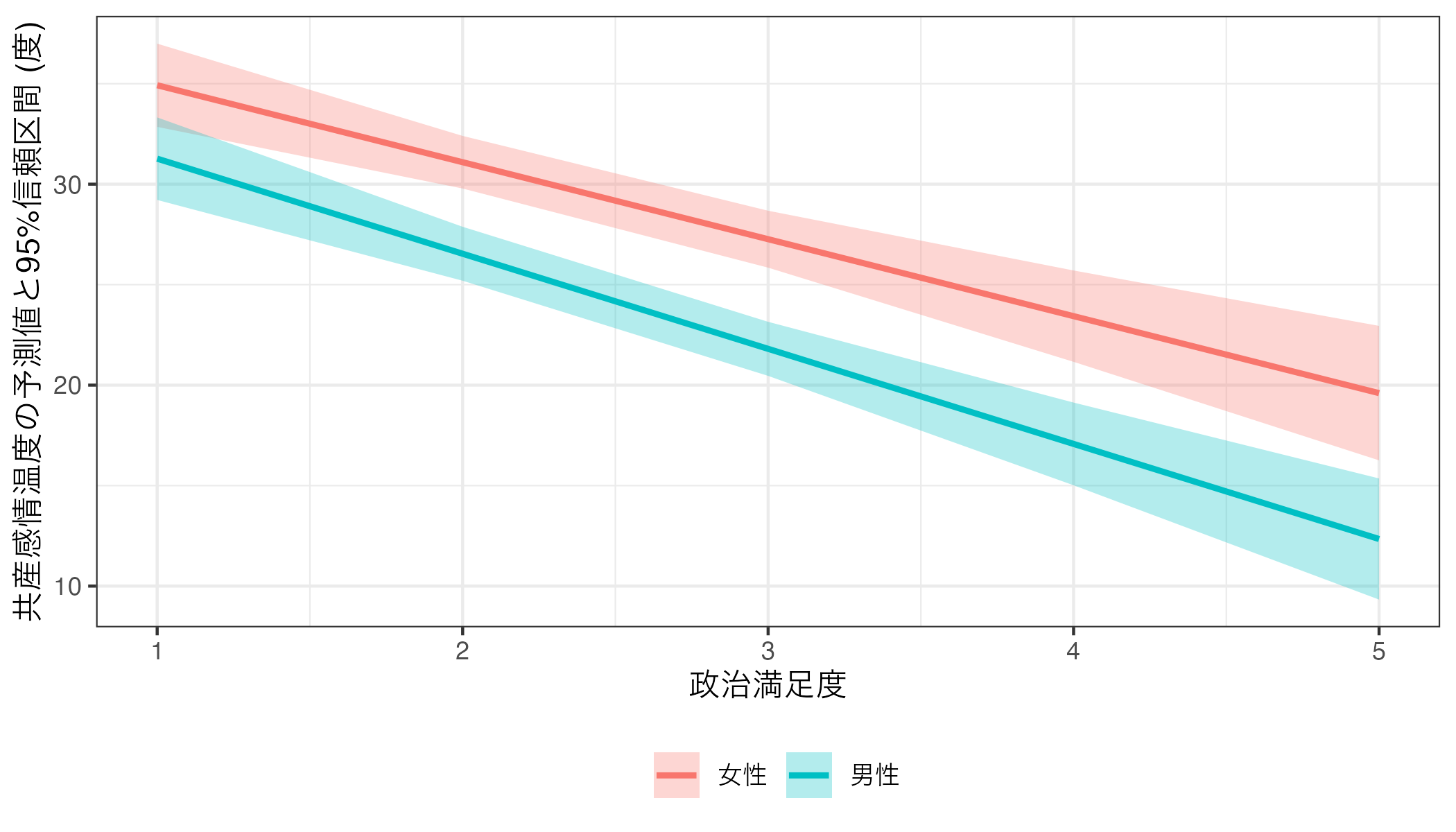
Point-rangeプロットにするか、リボン+折れ線の組み合わせにするかは好みの問題なので自分からみて読みやすいと思う図にしよう。
モデル2の解釈
モデル2(fit2)に対しても同じことが言える。まずは回帰式をまとめてみよう。
共産に対する感情温度の予測値 = 28.25 + 3.31 \(\times\) 政治満足度 + 0.36 \(\times\) 年齢 - 0.12 \(\times\) 政治関心 - 1.69 \(\times\) イデオロギー + 5.06 \(\times\) 女性ダミー - 0.16 \(\times\) 政治満足度 \(\times\) 年齢
これを政治満足度でまとめると、
共産に対する感情温度の予測値 = 28.25 + (3.31 - 0.16 \(\times\) 年齢) \(\times\) 政治満足度 + 0.36 \(\times\) 年齢 - 0.12 \(\times\) 政治関心 - 1.69 \(\times\) イデオロギー + 5.06 \(\times\) 女性ダミー
になる。つまり、政治満足度が共産感情温度に与える影響は「(3.31 - 0.16 \(\times\) 年齢の値)」だ。年齢は18、19、20、…など様々な値を取り得る。これら全てに対して計算することは効率的ではないため、ここでは年齢が20歳、40歳、60歳の場合に絞って政治満足度が共産感情温度に与える影響を計算してみよう。
まず、20歳の場合(Ageの値 = 20)、政治満足度が共産感情温度に与える影響は約0.11(= 3.31 - 0.16 \(\times\) 20)である(小数点7桁まで計算すると約0.1724813)。これは「20歳の場合、政治満足度が1単位上がると、共産に対する感情温度は約0.11度上がる」ことを意味する。つづいて、40歳の場合(Ageの値 = 40)、政治満足度が共産感情温度に与える影響は約-3.09(= 3.31 - 0.16 \(\times\) 40)である(小数点7桁まで計算すると約-2.962879)。これは「40歳の場合、政治満足度が1単位上がると、共産に対する感情温度は約3.09度下がる」ことを意味する。最後に60歳の場合(Ageの値 = 60)、政治満足度が共産感情温度に与える影響は約-6.29(= 3.31 - 0.16 \(\times\) 60)だ(小数点7桁まで計算すると約-6.098239)。これは「60歳の場合、政治満足度が1単位上がると、共産に対する感情温度は約6.29度下がる」ことを意味する。
以上の結果を回帰直線で示したものが以下の図である。fit2の調整変数は連続変数であるためすべての年齢に応じた回帰直線を出すのはあまりにも非効率的である。したがって、ここでは20、40、60歳の場合の回帰直線を可視化してみよう。今回は一連の作業をすべてパイプ演算子(|>)で繋ぎ、一つのコードにまとめてみた。
Code 11
fit2 |>
predictions(newdata = datagrid(Satisfaction = 1:5,
Age = c(20, 40, 60))) |>
mutate(Age = recode(Age,
"20" = "20歳",
"40" = "40歳",
"60" = "60歳")) |>
ggplot(aes(Satisfaction)) +
geom_ribbon(aes(ymin = conf.low, ymax = conf.high, fill = Age),
alpha = 0.3) +
geom_line(aes(y = estimate, color = Age), linewidth = 1) +
labs(x = "政治満足度", y = "共産感情温度の予測値 (度)", fill = "年齢", color = "年齢") +
theme_bw() +
theme(legend.position = "bottom")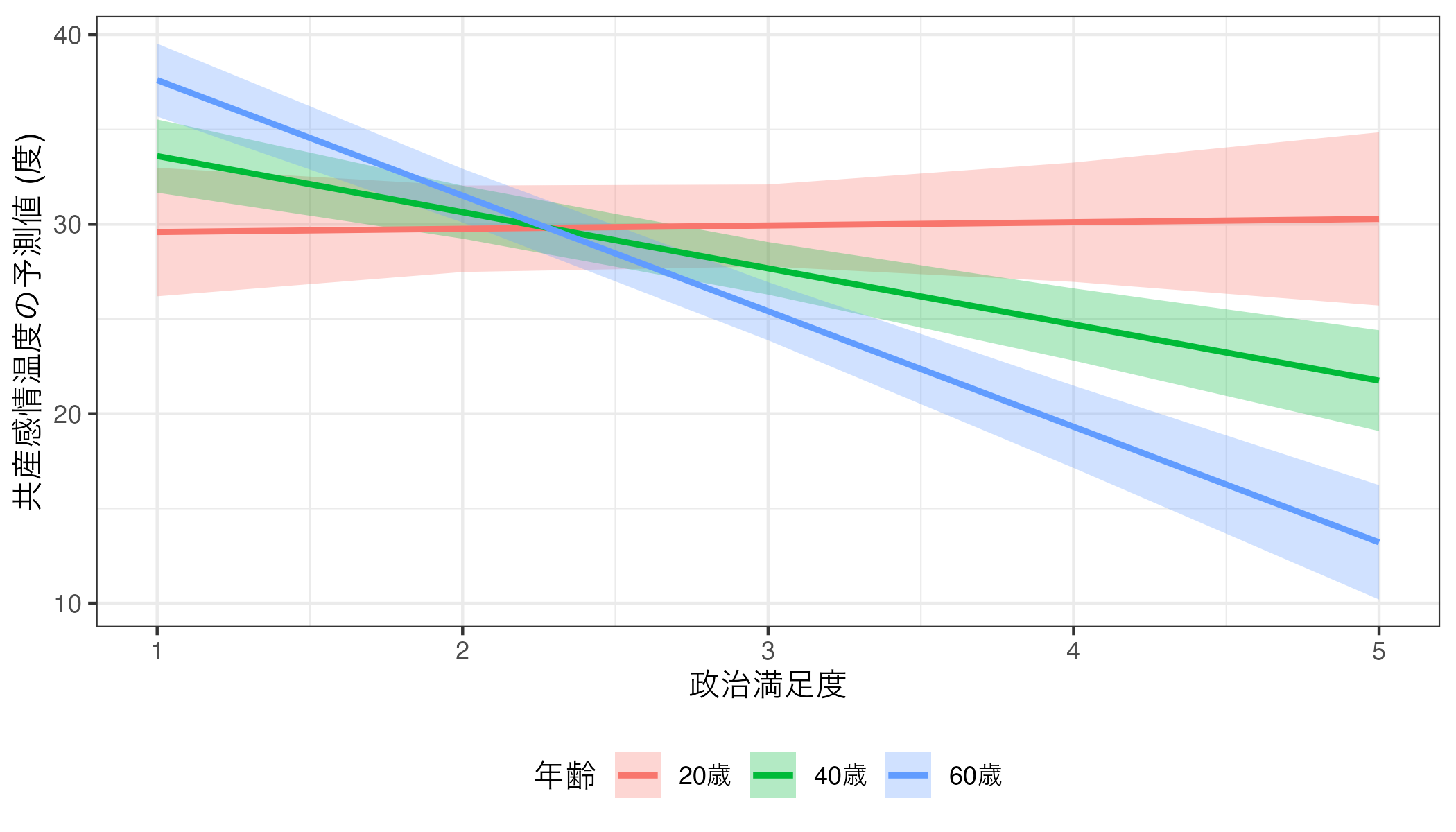
限界効果の話
交互作用とは説明変数\(X\)が応答変数\(Y\)に与える影響が調整変数\(Z\)の値に依存することを意味する。この場合、「説明変数\(X\)が応答変数\(Y\)に与える影響」の統計的有意性はどうだろうか。\(X\)が\(Y\)に与える影響の統計的有意性を検定する際に用いられる検定統計量は「\(X\)の係数 / \(X\)の標準誤差」である。しかし、ここでの\(X\)の係数(と標準誤差)は\(Z\)の値によって変わる。これは\(Z\)の値によって\(X \rightarrow Y\)の統計的有意性は変わることを意味する。
したがって、\(Z\)の値ごとに、\(X\)が\(Y\)に与える影響(= 限界効果; marginal effects)を計算するだけでなく、95%信頼区間 or \(p\)値も示す必要がある。95%信頼区間内に0が含まれないことは、\(p < 0.05\)を意味するため、統計的に有意な関連があると判断する。
限界効果の計算方法については解説済みである。しかし、統計的有意性に関しては説明がやや難しくなるため、これはRパッケージにお任せするとしよう。もし、数学的な背景に関心のある履修者はBrambor (2006)を参照されたい。
今回使用するパッケージ&関数は、冒頭で読み込んだ{marginaleffect}パッケージのslopes()関数だ。これは回帰モデルの限界効果と統計的有意性検定までやってくれる大変便利なパッケージである。使い方は以下の通り。
fit1の場合、Femaleの値が0と1の場合のSatisfactonの限界効果を求めることになる。したがって、回帰オブジェクト名はfit1、variablesの実引数は"Satisfaction"("で囲む)、datagrid()の中身はFemale = 0:1またはFemale = c(0, 1)だ。計算結果をfit1_ameに格納し、中身を確認する。
Code 12
Female Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
0 -4.73 0.561 -8.43 <0.001 54.7 -5.83 -3.63
1 -3.83 0.611 -6.27 <0.001 31.3 -5.03 -2.63
Term: Satisfaction
Type: response
Columns: rowid, term, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high, Female, predicted_lo, predicted_hi, predicted, Satisfaction, Interest, Ideology, Age, TempKyosan 非常に多くの情報が出力されるが、ここで興味のある列はFemaleの値(Female列)と、Satisfactionの限界効果(Estiamte列)、\(p\)値(Pr(>|z|)列)、95%信頼区間(2.5%列と97.5%列)である。それでは、select()関数でfit1_ameからこれらの列のみ出力してみよう。
前回の講義では、predictions()関数から得られた推定結果のオブジェクトを出力すると表示される列名と実際の列名は異なることを説明したが、slopes()も同様である。実際の列名を見たい場合はprint()関数を使用し、style = "data.frame"引数を追加しよう。
rowid term estimate std.error statistic p.value s.value conf.low conf.high Female
1 1 Satisfaction -4.731682 0.5613086 -8.429734 3.464517e-17 54.68012 -5.831826 -3.631537 0
2 2 Satisfaction -3.830102 0.6111603 -6.266935 3.682234e-10 31.33870 -5.027954 -2.632250 1
predicted_lo predicted_hi predicted Satisfaction Interest Ideology Age TempKyosan
1 24.41427 24.41237 24.41332 2.449 2.736333 6.340667 47.34 20
2 29.37374 29.37220 29.37297 2.449 2.736333 6.340667 47.34 20 限界効果の解釈に話を戻そう。限界効果はestiamte列に表示されており、Female = 0の場合のSatisfactionの限界効果は約-4.732、Female = 1の場合のそれは約-3.830である。また、いずれも\(p\)値が0.05を下回ることから統計的に有意な関係であることがわかる。つまり、性別と関係なく、政治満足度は共産感情温度に負の影響を与えることが分かる。
これらの結果を表でまとめると以下のようになる。表で\(p\)値を報告する場合、\(p\)値が非常に小さいケースがある(たとえば、\(p\) = 0.0000000235)。この場合、「\(p\) = 0.000」と表記せず、「\(p\) < 0.001」と表記すること。\(p\)値がぴったり0になることは実質的にあり得ない。
| 性別 | 平均限界効果 | p値 |
95%信頼区間
|
|
|---|---|---|---|---|
| 下限 | 上限 | |||
| 男性 | −4.732 | < 0.001 | −5.832 | −3.632 |
| 女性 | −3.830 | < 0.001 | −5.028 | −2.632 |
続いて、fit2の場合のAgeの値が18、19、20、…、75の場合のSatisfactionの限界効果を求めるてみよう。回帰オブジェクト名はfit2、variablesの実引数は"Satisfaction"("で囲む)、datagrid()の中身はAge = 18:75だ(18から75まで公差1の等差数列)。
Code 14
Age Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
18 0.4860 0.912 0.5327 0.594 0.8 -1.30 2.27
19 0.3292 0.890 0.3700 0.711 0.5 -1.41 2.07
20 0.1725 0.867 0.1990 0.842 0.2 -1.53 1.87
21 0.0157 0.842 0.0187 0.985 0.0 -1.63 1.67
22 -0.1411 0.820 -0.1721 0.863 0.2 -1.75 1.47
--- 48 rows omitted. See ?avg_slopes and ?print.marginaleffects ---
71 -7.8227 0.724 -10.8088 <0.001 88.0 -9.24 -6.40
72 -7.9795 0.745 -10.7044 <0.001 86.4 -9.44 -6.52
73 -8.1362 0.768 -10.5922 <0.001 84.7 -9.64 -6.63
74 -8.2930 0.790 -10.4909 <0.001 83.1 -9.84 -6.74
75 -8.4498 0.812 -10.4048 <0.001 81.8 -10.04 -6.86
Term: Satisfaction
Type: response
Columns: rowid, term, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high, Age, predicted_lo, predicted_hi, predicted, Satisfaction, Interest, Ideology, Female, TempKyosan いくつか気になる点がある。普通にfit2_ameのみ入力して出力すると、最初の5行と最後の5行のみが出力され、48行分が省略される。もし、すべての行を出力したい場合は、print()関数を使用し、topn = Inf引数を追加すれば良い。
Age Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
18 0.4860 0.912 0.5327 0.59428 0.8 -1.30 2.274
19 0.3292 0.890 0.3700 0.71138 0.5 -1.41 2.073
20 0.1725 0.867 0.1990 0.84225 0.2 -1.53 1.871
21 0.0157 0.842 0.0187 0.98511 0.0 -1.63 1.666
22 -0.1411 0.820 -0.1721 0.86337 0.2 -1.75 1.465
23 -0.2978 0.798 -0.3731 0.70908 0.5 -1.86 1.267
24 -0.4546 0.776 -0.5859 0.55791 0.8 -1.98 1.066
25 -0.6114 0.752 -0.8130 0.41623 1.3 -2.09 0.863
26 -0.7681 0.730 -1.0521 0.29277 1.8 -2.20 0.663
27 -0.9249 0.709 -1.3054 0.19177 2.4 -2.31 0.464
28 -1.0817 0.689 -1.5699 0.11643 3.1 -2.43 0.269
29 -1.2384 0.668 -1.8536 0.06379 4.0 -2.55 0.071
30 -1.3952 0.646 -2.1600 0.03078 5.0 -2.66 -0.129
31 -1.5520 0.626 -2.4791 0.01317 6.2 -2.78 -0.325
32 -1.7087 0.608 -2.8114 0.00493 7.7 -2.90 -0.518
33 -1.8655 0.589 -3.1665 0.00154 9.3 -3.02 -0.711
34 -2.0223 0.570 -3.5505 < 0.001 11.3 -3.14 -0.906
35 -2.1790 0.552 -3.9493 < 0.001 13.6 -3.26 -1.098
36 -2.3358 0.536 -4.3603 < 0.001 16.2 -3.39 -1.286
37 -2.4926 0.520 -4.7979 < 0.001 19.3 -3.51 -1.474
38 -2.6493 0.503 -5.2656 < 0.001 22.8 -3.64 -1.663
39 -2.8061 0.489 -5.7370 < 0.001 26.6 -3.76 -1.847
40 -2.9629 0.476 -6.2267 < 0.001 31.0 -3.90 -2.030
41 -3.1196 0.465 -6.7148 < 0.001 35.6 -4.03 -2.209
42 -3.2764 0.453 -7.2263 < 0.001 40.9 -4.17 -2.388
43 -3.4332 0.443 -7.7508 < 0.001 46.6 -4.30 -2.565
44 -3.5900 0.435 -8.2580 < 0.001 52.6 -4.44 -2.738
45 -3.7467 0.429 -8.7380 < 0.001 58.5 -4.59 -2.906
46 -3.9035 0.424 -9.2162 < 0.001 64.8 -4.73 -3.073
47 -4.0603 0.419 -9.6828 < 0.001 71.2 -4.88 -3.238
48 -4.2170 0.417 -10.1021 < 0.001 77.3 -5.04 -3.399
49 -4.3738 0.418 -10.4752 < 0.001 82.9 -5.19 -3.555
50 -4.5306 0.419 -10.8155 < 0.001 88.2 -5.35 -3.710
51 -4.6873 0.422 -11.1132 < 0.001 92.9 -5.51 -3.861
52 -4.8441 0.427 -11.3577 < 0.001 96.9 -5.68 -4.008
53 -5.0009 0.433 -11.5521 < 0.001 100.1 -5.85 -4.152
54 -5.1576 0.441 -11.7059 < 0.001 102.7 -6.02 -4.294
55 -5.3144 0.450 -11.8168 < 0.001 104.6 -6.20 -4.433
56 -5.4712 0.460 -11.8826 < 0.001 105.8 -6.37 -4.569
57 -5.6279 0.472 -11.9195 < 0.001 106.4 -6.55 -4.703
58 -5.7847 0.485 -11.9316 < 0.001 106.6 -6.73 -4.834
59 -5.9415 0.499 -11.9073 < 0.001 106.2 -6.92 -4.963
60 -6.0982 0.514 -11.8529 < 0.001 105.2 -7.11 -5.090
61 -6.2550 0.530 -11.7923 < 0.001 104.2 -7.29 -5.215
62 -6.4118 0.546 -11.7371 < 0.001 103.3 -7.48 -5.341
63 -6.5685 0.564 -11.6535 < 0.001 101.8 -7.67 -5.464
64 -6.7253 0.583 -11.5369 < 0.001 99.9 -7.87 -5.583
65 -6.8821 0.602 -11.4399 < 0.001 98.3 -8.06 -5.703
66 -7.0388 0.621 -11.3331 < 0.001 96.5 -8.26 -5.822
67 -7.1956 0.640 -11.2493 < 0.001 95.1 -8.45 -5.942
68 -7.3524 0.660 -11.1396 < 0.001 93.3 -8.65 -6.059
69 -7.5092 0.682 -11.0153 < 0.001 91.3 -8.85 -6.173
70 -7.6659 0.703 -10.9031 < 0.001 89.5 -9.04 -6.288
71 -7.8227 0.724 -10.8088 < 0.001 88.0 -9.24 -6.404
72 -7.9795 0.745 -10.7044 < 0.001 86.4 -9.44 -6.518
73 -8.1362 0.768 -10.5922 < 0.001 84.7 -9.64 -6.631
74 -8.2930 0.790 -10.4909 < 0.001 83.1 -9.84 -6.744
75 -8.4498 0.812 -10.4048 < 0.001 81.8 -10.04 -6.858
Term: Satisfaction
Type: response
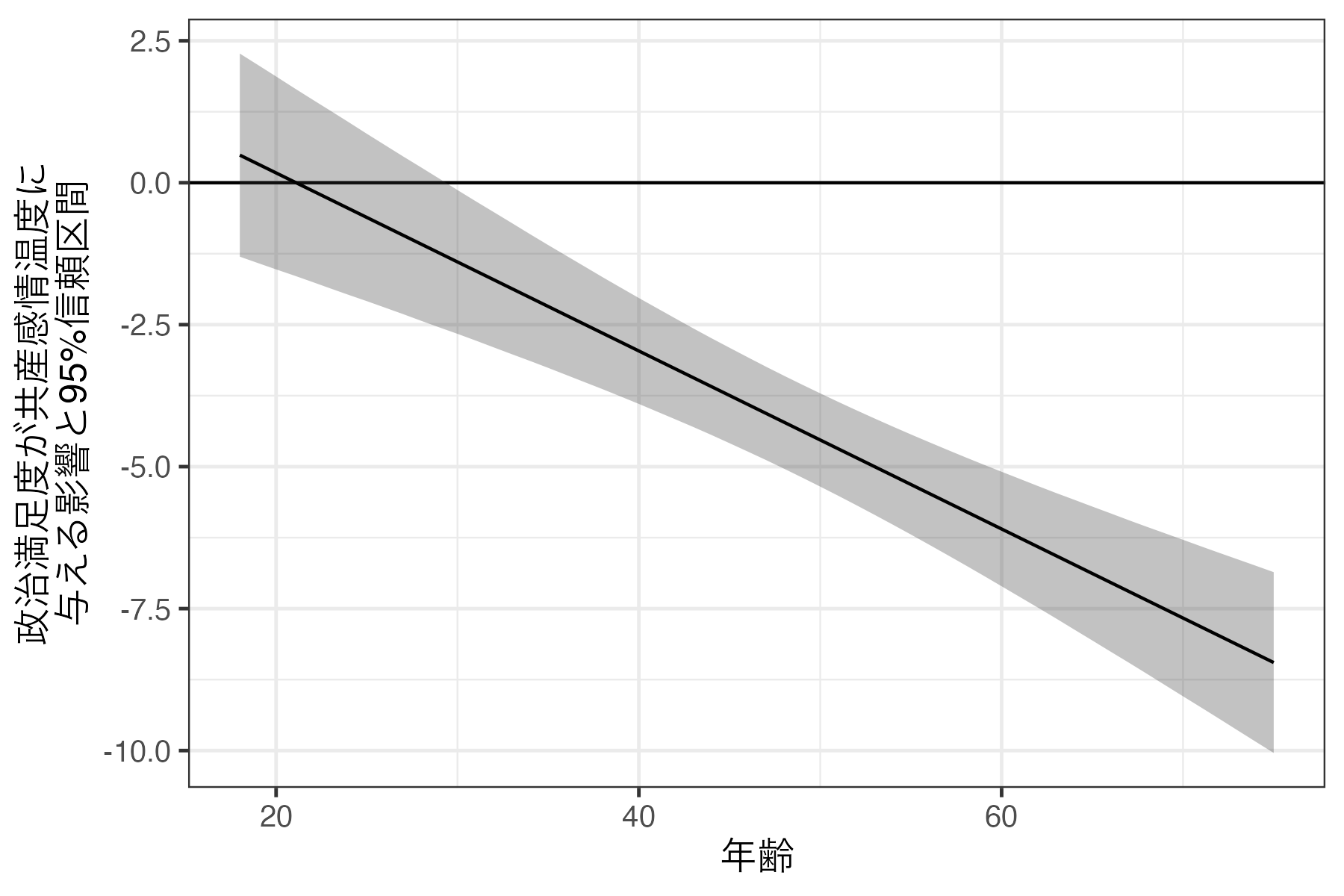
Columns: rowid, term, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high, Age, predicted_lo, predicted_hi, predicted, Satisfaction, Interest, Ideology, Female, TempKyosan 18〜29歳の場合、政治満足度が共産感情温度に与える影響は確認できない(つまり、\(p \geq 0.05\))。一方、回答者の年齢が30歳以上の場合、政治満足度は共産感情温度に負の影響を与えるが確認できる(つまり、\(p < 0.05\))。ちなみに、<2e-16と表示されるのは0に極めて近いことを意味し、表で示す際は< 0.001とかで表記するのが一般的だ。
交互作用を含む回帰モデルの場合、調整変数ごとの予測値の図と限界効果のグラフを示すのが一般的である。予測値のグラフ同様、限界効果(estimate列)と信頼区間の上限と下限(それぞれconf.lowとconf.high)を示すだけで良い。
まずfit1における政治満足度の限界効果(fit1_ame)を可視化してみよう。調整変数(Female)は2つの値(0と1)しかとらないので、point-rangeプロットが適切だろう。
Code 16
- 1
- y = 0の水平線を追加する。
- 2
- 目盛りを0と1のみとし、それぞれ「男性」、「女性」のラベルを付ける。
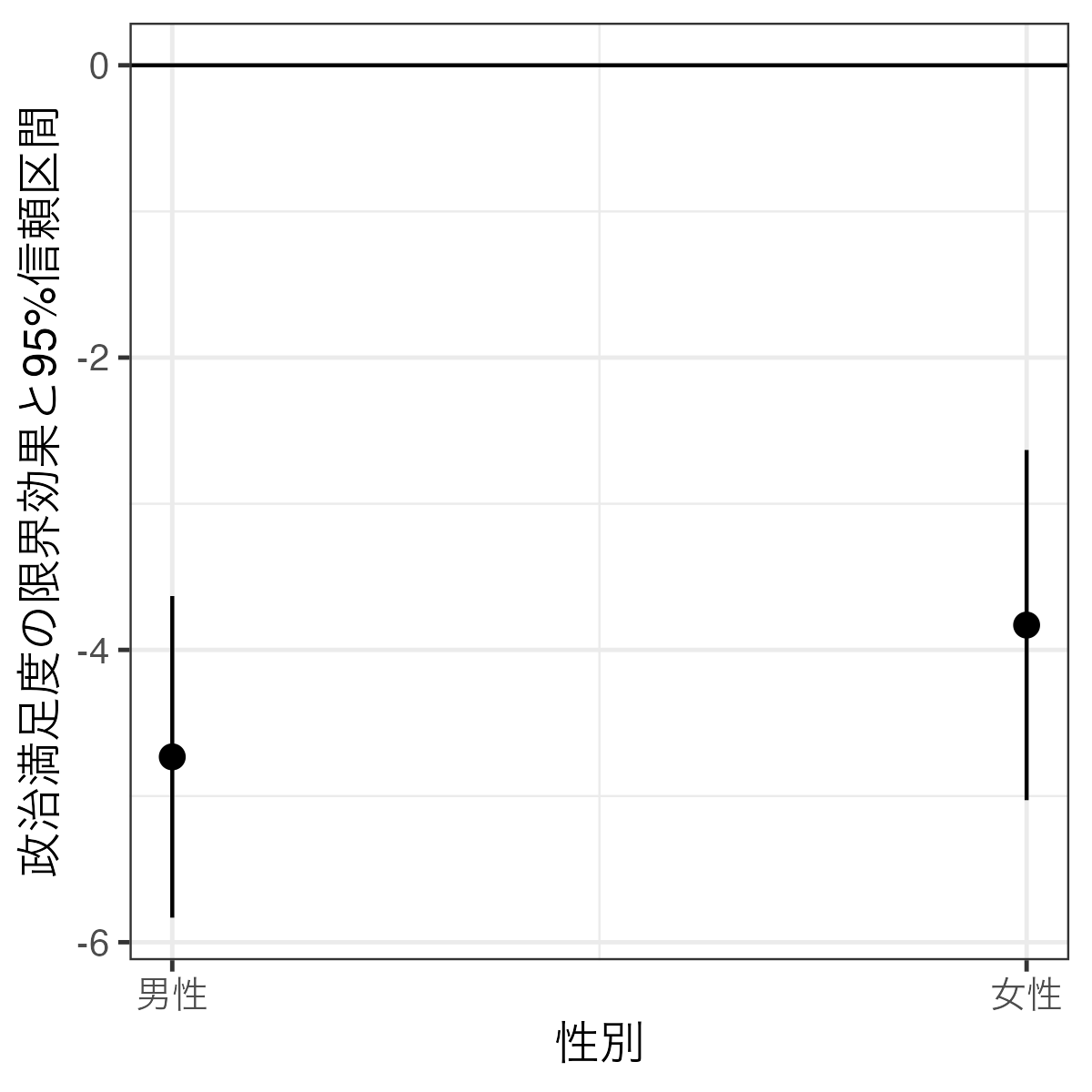
男性でも女性でも95%信頼区間内に0が含まれておらず、どちらも統計的に有意な負の限界効果である。これは「性別と関係なく政治満足度が高まると共産党に感情温度は下がる」ことを意味する。もうちょっと具体的に解釈すると「男性の場合、政治満足度が1単位上がると共産党に対する感情温度は約4.73度低くなり、女性の場合は3.83度低くなる」ということになる。
続いて、fit2における政治満足度の限界効果(fit2_ame)も確認してみよう。ここでは調整変数が取りうる値が多すぎるので、95%信頼区間を垂直線でなく、リボンとする。また縦軸を「政治満足度の平均限界効果」でなく、「政治満足度が共産感情温度に与える影響」にすることで、交互作用の知識のない読者にとって解釈しやすくした(途中の\nは改行を意味する)。
Code 17
29歳までは95%信頼区間に0が含まれている。30歳からは限界効果が負となり、統計的に有意な関係を示している。これは「30歳以上の有権者のみにおいて、政治満足度が高まると共産党に対する感情温度は下がる」ことを意味する。一方、「30歳未満の有権者の場合、政治満足度が共産党に対する感情温度に影響を与えるとは言えない」とも解釈できる。ここで更に詳しく解釈すると「30歳の有権者の場合、政治満足度が1度上がると、共産党に対する感情温度が約-1.40度下がり、60歳は約6.10度下がる」とも言えよう(何歳を解釈の基準にするかは好みによる)。