セットアップ
まずは実習に使用する2つのパッケージ({tidyverse}と{summarytools})とデータ(Gacha.csv)を読み込む。Gacha.csvはLMSから入手可能である。プロジェクトフォルダー内にDataフォルダーを作成し、そこにGacha.csvがアップロードした場合、パスは"Data/Gacha.csv"となる。
RStudioの右上に「Project: (None)」と表示されている場合は、プロジェクト機能を使用していないことを意味する。プロジェクト名が表示されていることを確認すること。
# pacman::p_load(tidyverse, summarytools) でもOK library (tidyverse)library (summarytools)# Gacha.csvがDataフォルダー内にあれば以下のコードでOK # dataフォルダーならDataをdataに置換 <- read_csv ("Data/Gacha.csv" )
# A tibble: 4,227 × 4
player trial stone_type result
<dbl> <dbl> <chr> <chr>
1 1 1 paid N
2 1 2 free N
3 1 3 free N
4 1 4 free R
5 1 5 paid R
6 1 6 free R
7 1 7 free R
8 1 8 free R
9 1 9 free R
10 1 10 paid N
# ℹ 4,217 more rows
データは4772行4列で構成されており、各変数(列)の詳細は以下の通りである。
まずは、各変数の記述統計から確認してみよう。
|> descr (stats = c ("mean" , "sd" , "min" , "max" , "n.valid" ),transpose = TRUE , order = "p" )
Descriptive Statistics
gacha_df
N: 4227
Mean Std.Dev Min Max N.Valid
------------ -------- --------- ------ -------- ---------
player 5.50 2.86 1.00 10.00 4227.00
trial 212.05 122.39 1.00 445.00 4227.00
考えてみれば、stone_typeとresultは数値型ではないため、記述統計量が計算できない。今回の場合、stone_type変数は使わないため、問題ないものの、resultはダミー変数に変換する必要があろう。ダミー変数については「ミクロ政治データ分析実習」の第10回 と本講義の第4回 を参照すること。
<- gacha_df |> mutate (result_N = if_else (result == "N" , 1 , 0 ),result_R = if_else (result == "R" , 1 , 0 ),result_SR = if_else (result == "SR" , 1 , 0 ),result_SSR = if_else (result == "SSR" , 1 , 0 ))
# A tibble: 4,227 × 8
player trial stone_type result result_N result_R result_SR result_SSR
<dbl> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 1 1 paid N 1 0 0 0
2 1 2 free N 1 0 0 0
3 1 3 free N 1 0 0 0
4 1 4 free R 0 1 0 0
5 1 5 paid R 0 1 0 0
6 1 6 free R 0 1 0 0
7 1 7 free R 0 1 0 0
8 1 8 free R 0 1 0 0
9 1 9 free R 0 1 0 0
10 1 10 paid N 1 0 0 0
# ℹ 4,217 more rows
ちなみに{fastDummies}パッケージのdummy_cols()(または、dummy_columns())を使っても同じ結果が得られる。好きな方法を使えば良い。また、dummy_cols()関数から作成されたダミー変数の変数名は元の変数名_値となる。
# 上記のコードは以下のように書くこともできる。 # ignore_na = TRUE を指定しない場合、欠損値か否かを示すダミー変数も生成される。 library (fastDummies)<- gacha_df |> dummy_cols (select_columns = "result" , ignore_na = TRUE )
# A tibble: 4,227 × 8
player trial stone_type result result_N result_R result_SR result_SSR
<dbl> <dbl> <chr> <chr> <int> <int> <int> <int>
1 1 1 paid N 1 0 0 0
2 1 2 free N 1 0 0 0
3 1 3 free N 1 0 0 0
4 1 4 free R 0 1 0 0
5 1 5 paid R 0 1 0 0
6 1 6 free R 0 1 0 0
7 1 7 free R 0 1 0 0
8 1 8 free R 0 1 0 0
9 1 9 free R 0 1 0 0
10 1 10 paid N 1 0 0 0
# ℹ 4,217 more rows
それでは、もう一度記述統計量を出してみよう。また、プレイヤーのIDは数値ではあるものの、数値としての意味を持たない名目変数である。こちらは不要であるので、gacha_dfをdescr()関数を渡す前にplayer列を除外しておこう。
|> select (- player) |> descr (stats = c ("mean" , "sd" , "min" , "max" , "n.valid" ),transpose = TRUE , order = "p" )
Descriptive Statistics
Mean Std.Dev Min Max N.Valid
---------------- -------- --------- ------ -------- ---------
trial 212.05 122.39 1.00 445.00 4227.00
result_N 0.57 0.49 0.00 1.00 4227.00
result_R 0.25 0.43 0.00 1.00 4227.00
result_SR 0.15 0.36 0.00 1.00 4227.00
result_SSR 0.03 0.16 0.00 1.00 4227.00
場合によっては、ガチャの結果を度数分布表としてまとめる必要があるかも知れない。この場合、table()にガチャ結果が格納されたベクトルを指定すれば出力される。表形式データ構造(data.frame / tibble)から特定の列のみを抽出するときには$を使用する。
N R SR SSR
2417 1050 642 118
統計的仮説検定
仮説の設定
今回の実習で大事なのはSSRが出る確率が3%か否かである。公式サイトが主張する3%が帰無仮説であり、\(\mu_0 = 0.03\) と表記する。一方、手元のデータにおけるSSRの出現割合は\(\bar{x}\) と表記し、これはresult_SSR列の平均値を出すことで計算できる。
mean (gacha_df$ result_SSR)
手元のデータにおけるSSRの出現割合は約2.79%である。3%よりは低いが、これは誤差の範囲かも知れないし、開発元が嘘をついているかも知れない。ただし、自分がSSRキャラを引けない時はだいたい開発元が悪いことに決まっている。したがって、ここでの仮説は以下の通りである。
仮説: SSRキャラクターの本当の出現確率(=母平均\(\mu\) )は3%(=0.03)ではない(\(\mu \neq 0.03\) )。
\(\mu\) と\(\mu_0\) は区別する必要がある。今回の例だと\(\mu\) は開発元がシステムに設定したSSRの出現確率であり、\(\mu_0\) は開発元が公開しているSSRの出現確率である。開発元はSSRの出現確率が3%であると主張している(\(\mu_0 = 0.03\) )。一方、\(\mu\) は本当の出現確率である。つまり、開発元の情報が正しければ\(\mu = \mu_0\) となる。そして、私たちの主張は\(\mu \neq \mu_0\) である。したがって、仮説は\(\mu \neq 0.03\) となる。
ただし、一般的な統計的仮説検定の場合、仮説を直接検証することはできない。統計的仮説検定には2つの仮説が必要だ。1つ目は帰無仮説 (null hypothesis)である。これは否定されることによって別の仮説が支持されるような仮説 を意味し、統計的仮説検定は帰無仮説を検定することを意味する。この帰無仮説が間違っていることを示すのが統計的仮説検定だ。我々が論破したい仮説とも言えよう。帰無仮説は\(H_0\) とも表記され、今回は「SSRキャラクターの本当の出現確率は5%である(\(H_0: \mu = 0.03\) )」、つまり開発元の主張である。
もう一つの仮説は対立仮説 (alternative hypothesis)である。これは帰無仮説が否定されることによって妥当性が高まる仮説 である。統計的仮説検定とは帰無仮説を検定し、帰無仮説を否定することで対立仮説の妥当性が高いことを示す一連の過程である。対立仮説は\(H_a\) とも表記され、ここでは「SSRキャラクターの本当の出現確率は5%ではない(\(H_a: \mu \neq 0.03\) )」が対立仮説である。
有意水準の設定
開発元の主張だとSSRの確率は3%、手元のデータだと2.79%である。差は約0.21%ポイントである。手元のデータ上、SSRの出現割合がぴったり3%になることは、ほぼないと考えられる。つまり、考えてみれば2.79%というのは誤差の範囲かも知れないことだ。一方、手元のデータ上のSSR割合が1%であれば、明らかにおかしいだろう。ならば我々は「どんな時に帰無仮説を棄却するか」について考える必要があり、これが有意水準の設定である。
帰無仮説が正しい(\(\mu = \mu_0 = 0.03\) )としても、標本から得られる統計量\(\bar{x}\) は\(\mu_0\) と一致しない可能性が十分あり得る。ただし、本当に\(\mu = 0.03\) なら標本内のSSRの割合はぴったり3%でなくても、3%から大きく離れた値は得られないはずだ。どれくらいかけ離れていれば帰無仮説は間違っていると言えるだろうか。まずは、出現しうる統計量をすべて並べてみよう。ガチャを4772回引いた場合の得られる結果(すべてSSR〜すべてSSR以外)を並べ、帰無仮説が仮定する母数 (\(\mu_0 = 0.3\) )からA%分離れている場合、「帰無仮説から十分に離れている」と判断し、このA%が「有意水準 (significance level)」だ。つまり、有意水準とは「帰無仮説が正しいにもかかわらず、誤って帰無仮説を棄却してしまう確率」を意味する。この有意水準は通常、\(\alpha\) と表記し、有意水準が5%なら\(\alpha = 0.05\) である。ちなみに、社会科学では\(\alpha = 0.05\) を採用するケースが多い。
前回の講義では標本平均を変形した\(T\) 統計量を紹介した。\(T\) 統計量は\(T = \frac{\bar{x} - \mu}{\text{SE}}\) であり、自由度\(n-1\) の\(t\) 分布に従う。つまり、帰無仮説が正しければ(\(\mu = \mu_0\) )、 \(T = \frac{\bar{x} - \mu_0}{\text{SE}}\) も\(t\) 分布に従うと考えられる。\(t\) 分布の中心は0であるため、もし、標本から得られた統計量(標本平均\(\bar{x}\) )が0.03(\(\bar{x} = \mu_0 = \mu\) )なら、\(T\) 統計量は0となり、帰無仮説の妥当性は高いと判断される。一方、\(\bar{x}\) が0.03から離れるほど、\(T\) 統計量も0から離れるようになるだろう。どれくらい離れている場合、「帰無仮説は怪しいぞ」と言えるだろうか。つまり、「帰無仮説が正しいと仮定した場合、こんなことが起こる確率はA%未満だ!」を語る場合、どれくらいのA%であれば、帰無仮説は間違っていると主張できるだろう。いや、その前にこのA%はどのように計算されるのあか。
たとえば、データから得られた\(T\) 統計量の値が1.96だとしよう。以下のグラフは自由度4771の\(t\) 分布である。先ほど投票したA%は、下の図における網掛けの領域の面積である(確率分布の面積は必ず1)。もし、\(T\) 統計量が0に近い場合は網掛けの面積が広がるだろう。つまり、帰無仮説が間違っているとはなかなか言えなくなる。一方、\(T\) 統計量が0から離れるほど、網掛けの面積は小さくなり、帰無仮説が間違っていることを自身を持って言えよう。
検定統計量
いきなり\(T\) 統計量が登場した戸惑っているかも知れない。普通に考えれば、「単純に3%と2.79%間の比較で良いのでは?」と思うかも知れないが、これには理由がある。ととえば、20回ガチャを回してSSRが1回も出なかったとしよう。つまり、出現割合が0%であり、\(\mu_0\) と\(\bar{x}\) の差は0.03である。しかし、これを見て開発元が嘘をついていると主張することは難しいだろう。一方、1万回回して、100回SSRが出たら(\(\bar{x} = 0.01\) )どうだろう。この場合は差は0.02であるが、明らかにおかしい。つまり、単純に平均値の差分だけ では開発元が嘘をついているかどうかを判断することは難しい。より適切な指標が必要だ。それが検定統計量 である。平均値に関する統計的仮説検定の場合、検定統計量として標本平均(\(\bar{x}\) )よりも\(T\) 統計量を使用する。ちなみに仮説検定には様々な種類があり、検定手法に応じて用いられる統計量も変わってくる。\(z\) 統計量や\(\chi^2\) 統計量、\(F\) 統計量など様々な統計量があるが、今後、必要に応じて解説する。
\(T\) 統計量の計算方法は前回の講義にて解説したが、以下と通りである。一つ注意すべきところは\(\bar{x}\) から\(\mu_0\) を引く点である。
\[
t = \frac{\bar{x} - \mu}{\text{SE}} = \frac{\bar{x} - \mu_0}{\text{SE}} = \frac{\bar{x} - \mu_0}{\frac{u}{\sqrt{n}}}
\]
実際に\(T\) 統計量を計算してみよう。\(T\) 統計量を計算するためには、result_SSRの平均値、標本不偏分散の平方根(\(u\) )、サンプルサイズ(\(n\) )が必要であり、標本不偏分散の平方根とケース数を使って標準誤差を計算する。
# 標本平均 <- mean (gacha_df$ result_SSR, na.rm = TRUE )
# サンプルサイズ <- sum (! is.na (gacha_df$ result_SSR))
# 標準誤差 <- sd (gacha_df$ result_SSR, na.rm = TRUE ) / sqrt (n)
# T統計量 <- (x_bar - 0.03 ) / se
\(T\) 統計量は\(-\infty \sim \infty\) の値を取るが、今回得られた\(t\) の絶対値(\(|t|\) )よりも極端な値をとる確率を計算することで、我々の仮説の尤もらしさが分かる。そしてこの確率は\(p\) 値と呼ばれる。ちなにみ、なぜ絶対値を使う理由は対立仮説は「\(\mu_0\) ではない(\(\mu_0 \neq 0\) )」であるため、\(\mu_0\) から負の方向に離れる可能性も、正の方向に離れる可能性もあるからだ。
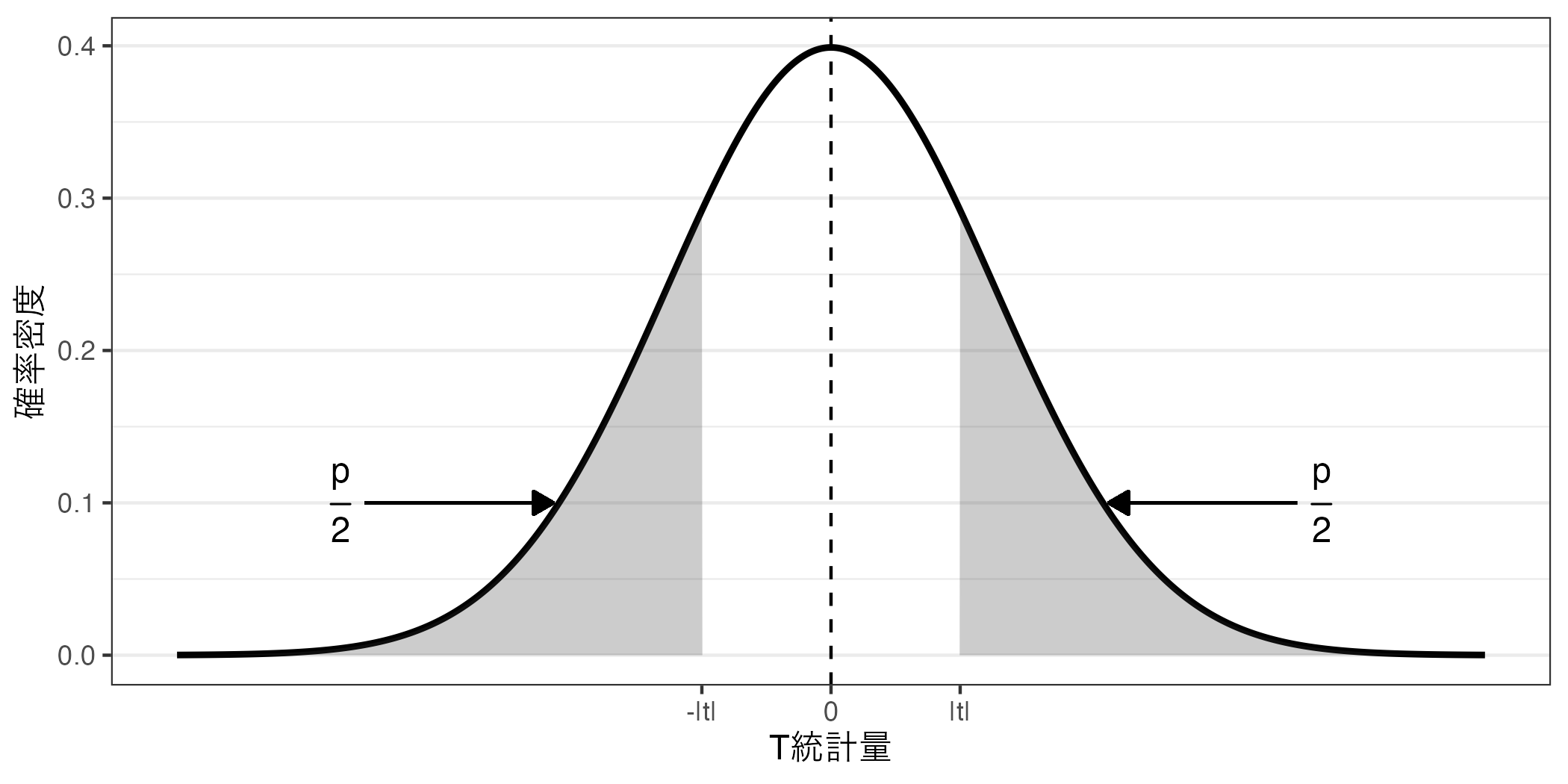
\(p\) 値 具体的に\(p\) 値の意味について考えてみよう。\(p\) 値とは帰無仮説が正しいと仮定した場合、手元のデータから得られた\(|t|\) 以上の\(|t|\) が得られる確率である。これを図として示すと以下のようになる。以下の図で網掛けの領域の面積が\(p\) 値であり、0以上、1以下の値を取る。
もし、手元のデータから得られた\(|t|\) 統計量が大きい場合は、以下のように、\(p\) 値が小さくなる。
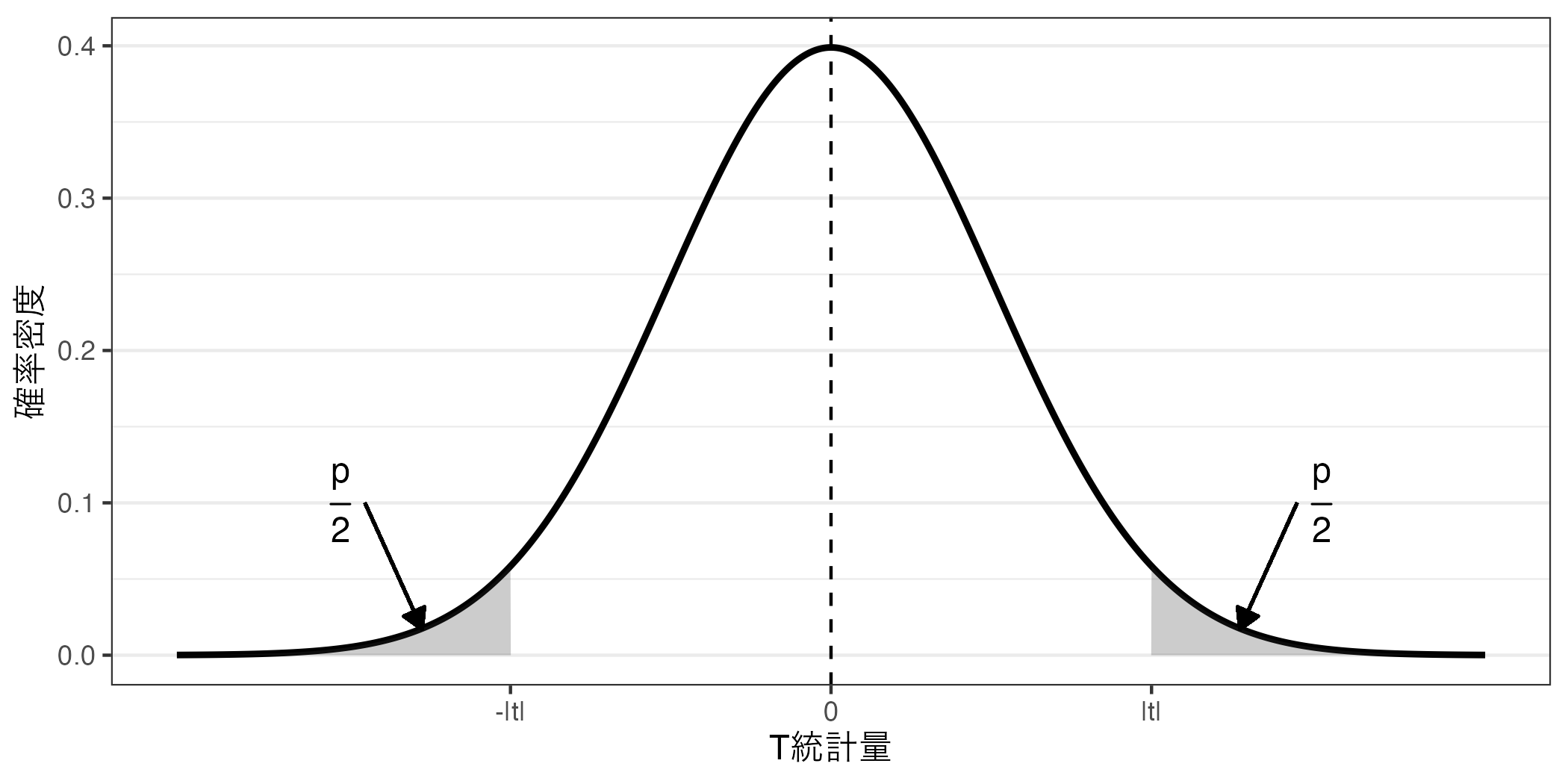
一方、\(|t|\) が小さい、つまり\(t\) が0に近い場合は\(p\) 値が大きくなる。
ここから分かるのは、検定統計量が0から離れる(\(|t|\) が大きい)ほど、\(p\) 値が小さくなるということだ。そして、帰無仮説を棄却するためには\(|t|\) が十分に大きい必要があり、これは\(p\) 値が小さいほど帰無仮説を棄却しやすいことを意味する。この\(p\) 値がどれおほど小さければ帰無仮説が棄却できるかに関する基準が有意水準\(\alpha\) であり、社会科学では一般的に\(\alpha = 0.05\) を採用する。
それではもう一度に\(p\) 値ついてまとめてみよう。\(p\) 値とは、帰無仮説が正しいとき、検定統計量(今回は\(T\) )が手元のデータから得られた検定統計量(今回は\(t\) )以上に、分布の中心からかけ離れた値を取る確率 を意味する。つまり、帰無仮説の下でのサンプルから得られた検定統計量(\(t\) )の異常性を表す指標であり、\(p\) 値が小さいほど、今回得られた\(t\) は異常な値であることを意味する。そして、今回の\(t\) が異常なのは「帰無仮説が正しい」という仮定の下での判断であるため、\(p\) 値が十分に小さい場合は、今回得られた\(t\) 統計量は異常である、つまり帰無仮説が間違っていると判断することができる。
検定統計量が\(T\) 統計量の場合の\(p\) 値はpt()関数で計算することができ、今回の\(p\) 値は0.411である。
# pt()の第一引数は「tの絶対値にマイナスをかけた値」にする # dfは自由度(n - 1) # 最終的には2をかける pt (- 1 * abs (- 0.8224918 ), df = 4771 ) * 2
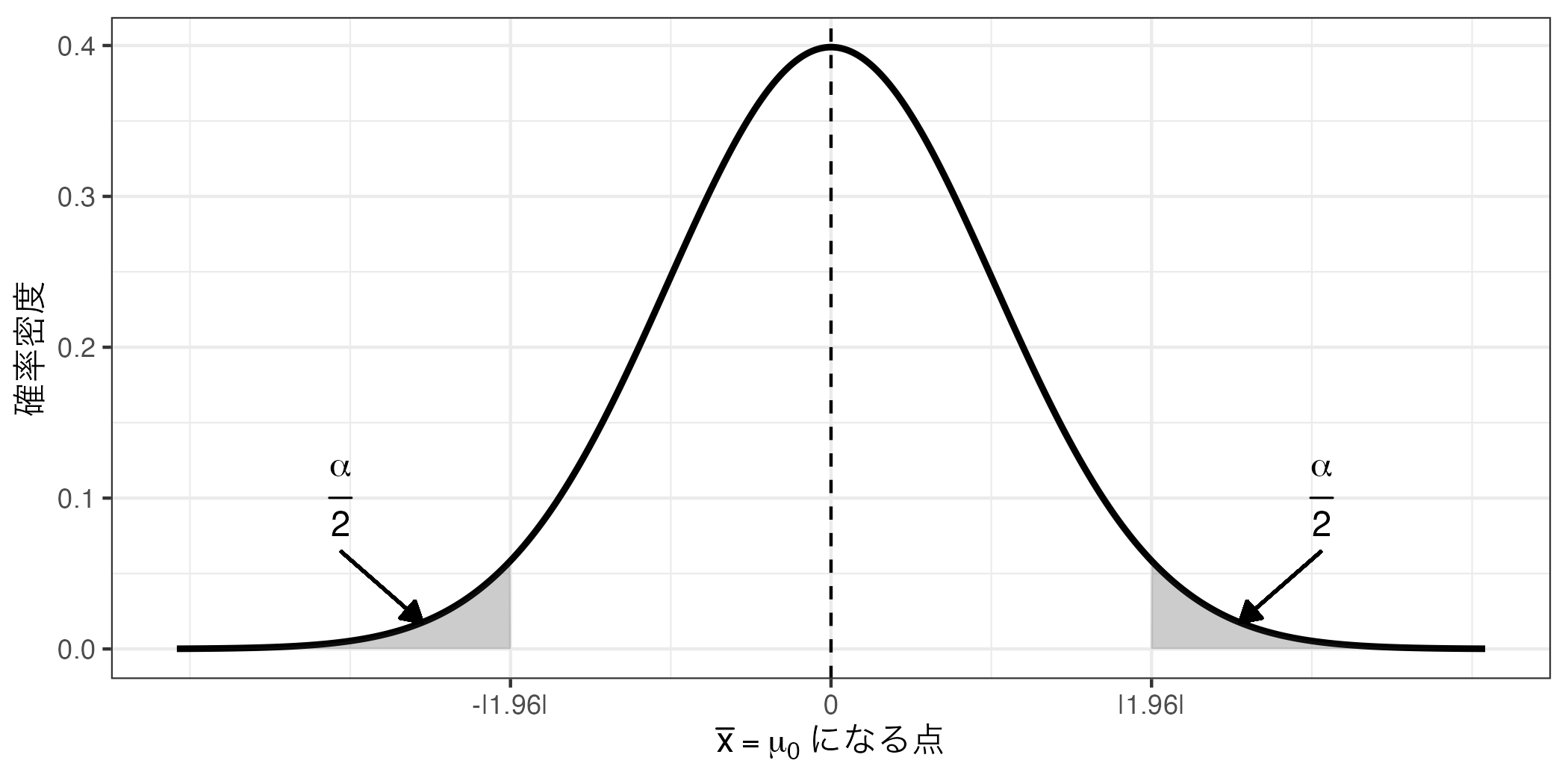
\(p\) 値に関する誤解 後ほど説明するが\(p\) 値は統計的仮説検定において非常に便利な指標であるものの、よく誤解される概念である。とりわけ「\(p\) 値 = 帰無仮説が棄却される確率」と誤解する人が多いが、これは完全に間違いである。しかし、このような説明をする人も少なからずいる。最近はYouTube等で大変分かりやすい動画が散見されるが、それらが正しい知識を伝えているとは限らない。宋の個人的な立場としては、「少なくともYouTube等で統計的仮説検定に関する講座は見ない」ことを推奨する。研究者(含む大学教員)が運営するならまだ良いかも知れないが、得体の知らないYouTuberには注意しよう。これから示す2つの画像は某学習系YouTuberの動画の一部だ。
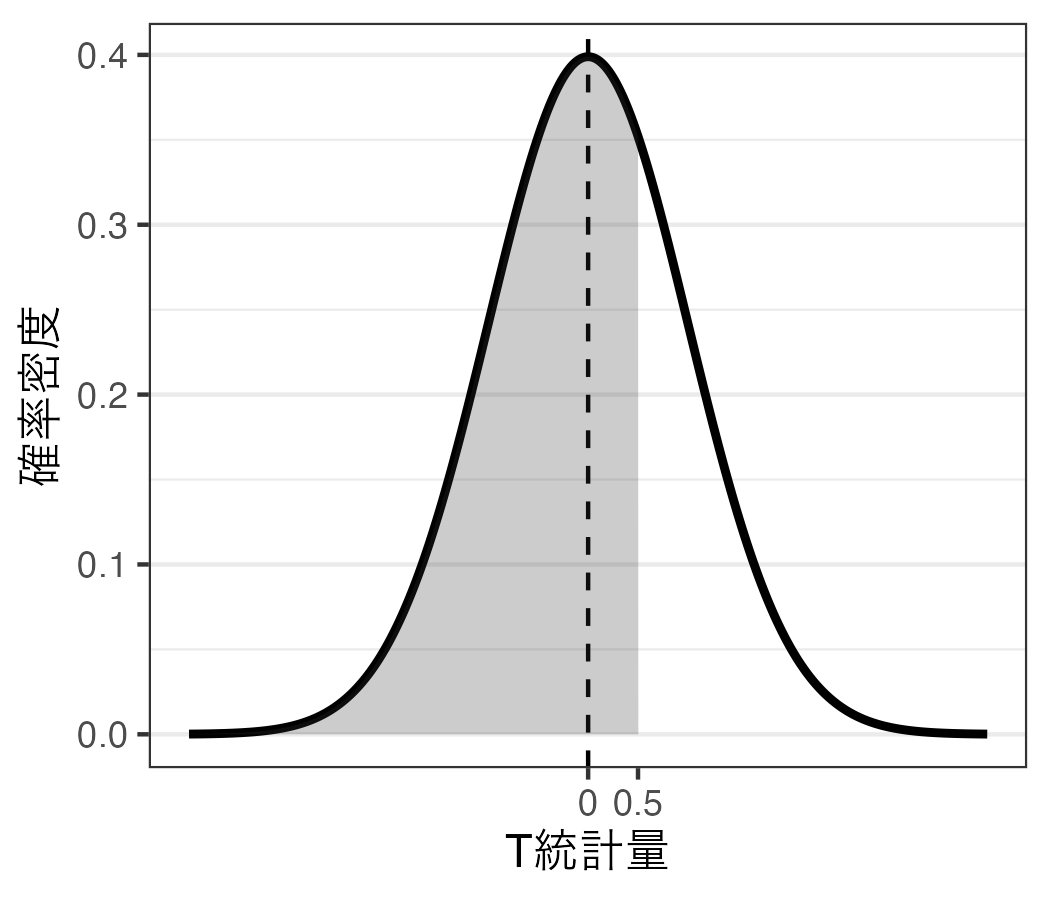
図 1 のような説明は大変分かりやすい。ただし、間違った内容だ。正確に言えば、「帰無仮説が正しい確率は常に0%」である。ならば疑問を持つ人もいるだろう。「帰無仮説が正しい確率が0%なら、対立仮説が正しい確率は100%なのではないか」と。問題はそう単純ではない。帰無仮説が正しいということは\(T\) 統計量がぴったり 0であることを意味する。しかし、(\(t\) 分布や正規分布など)連続確率分布においてある統計量が特定の値を取る確率は常に0である。その意味で以下の 図 2 も間違った内容である。
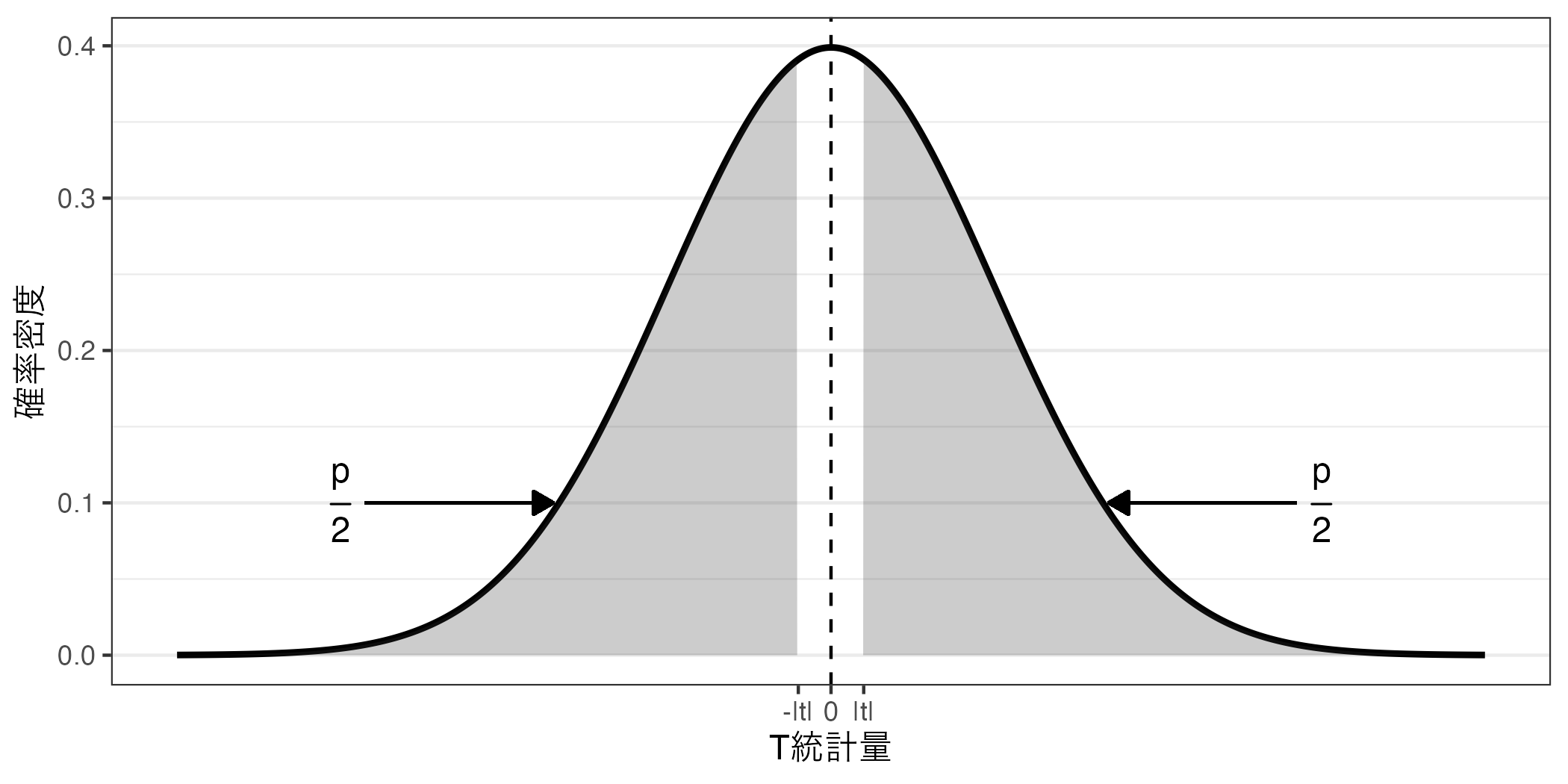
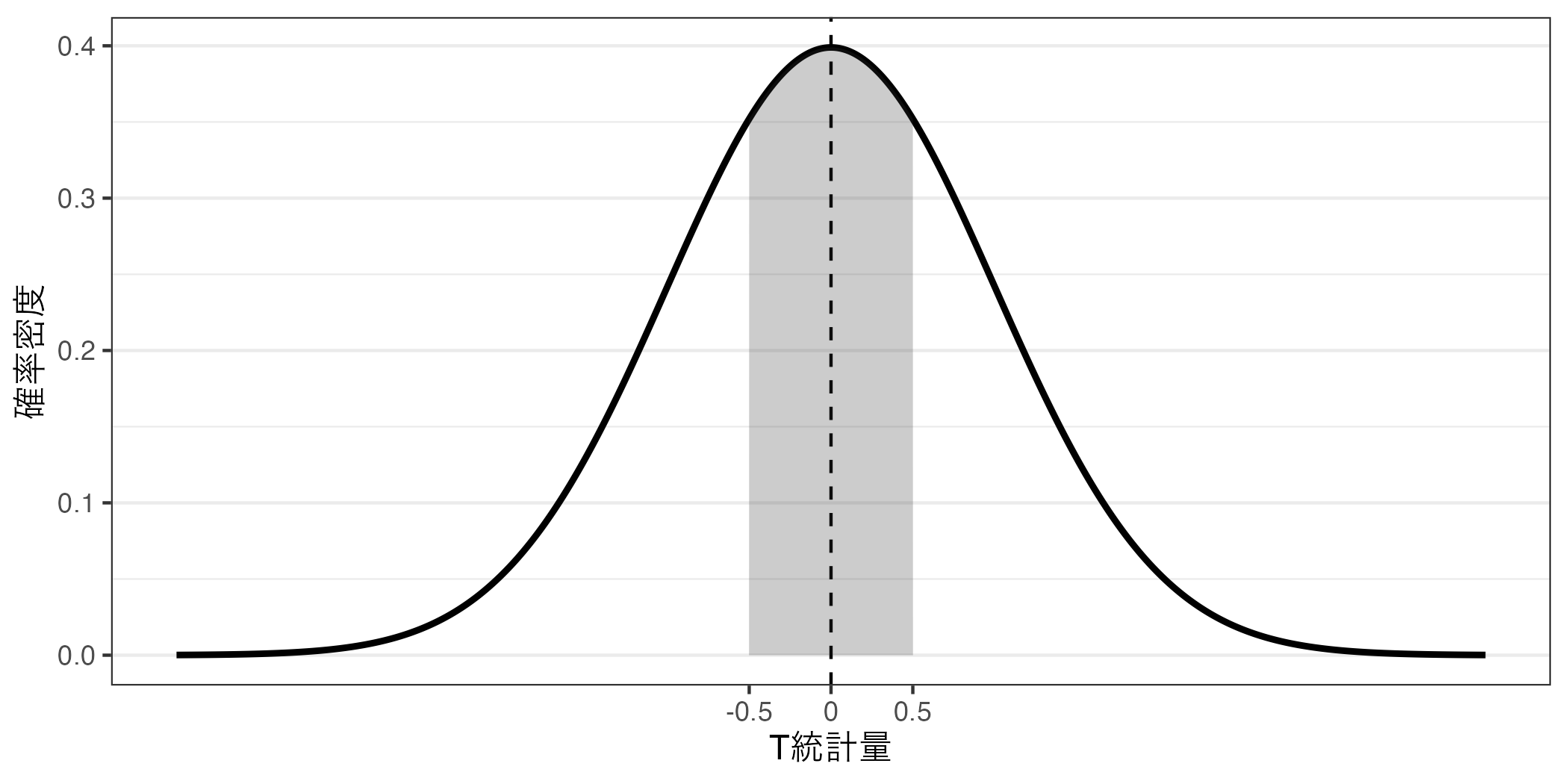
「今回得られた\(t\) 統計量がX.XXXである確率」も常に0%だ。積分の知識が少しでもあれば、これは当たり前であろう。たとえば、\(t\) 分布において\(T\) 統計量が-0.5以上、0.5以下の値を取る確率を計算したいとしよう。以下の図の網掛けの領域の面積が「\(T\) 統計量が-0.5以上、0.5以下の値を取る確率」だ。
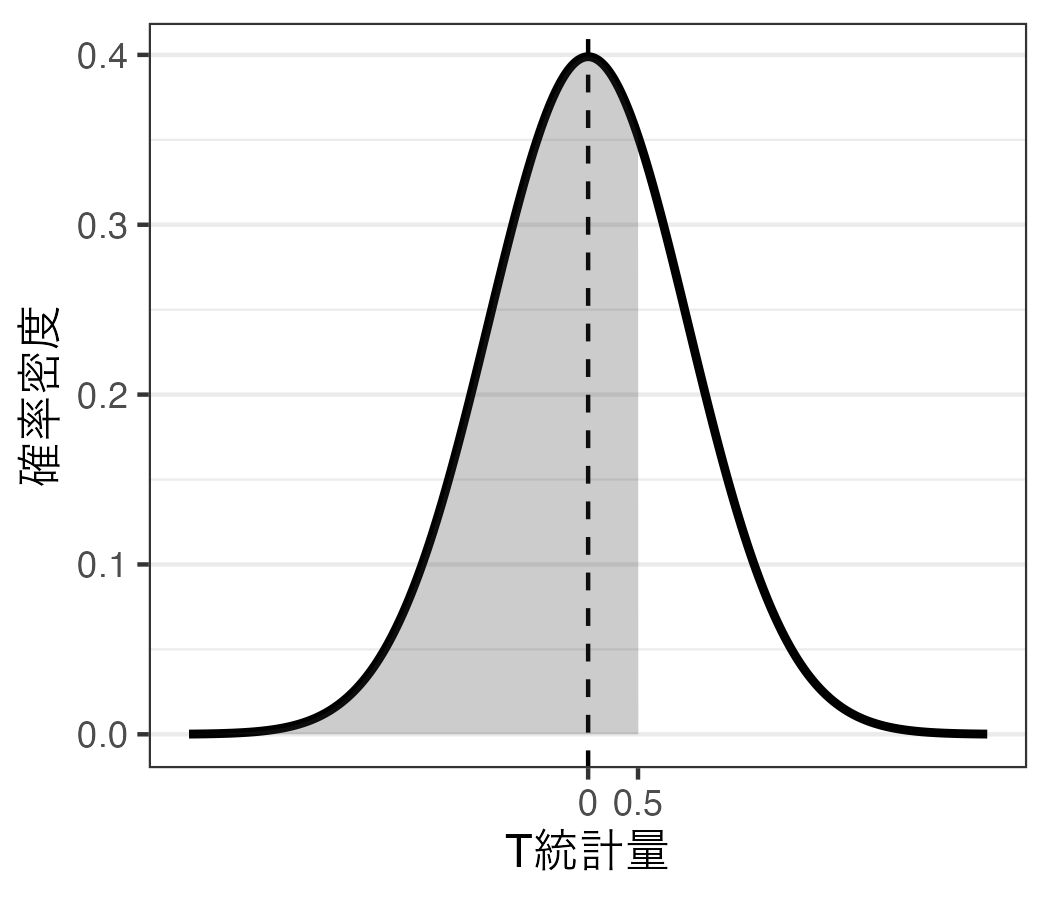
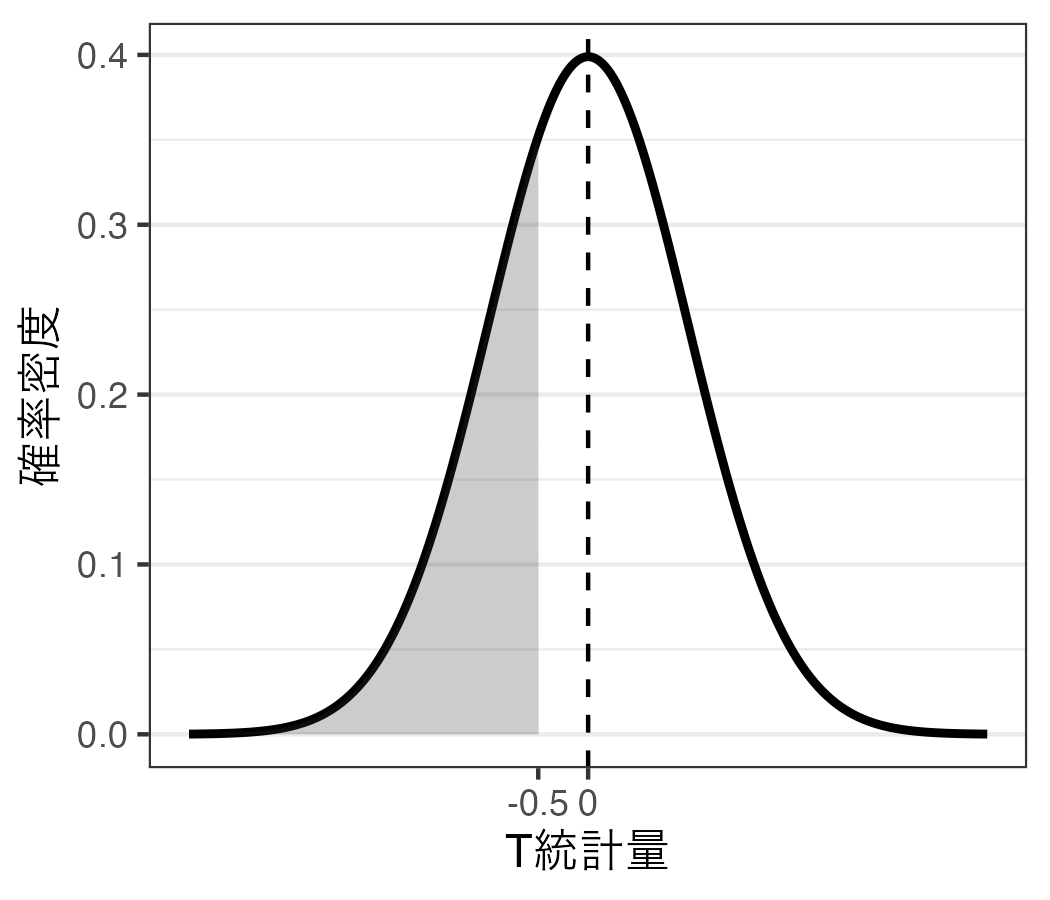
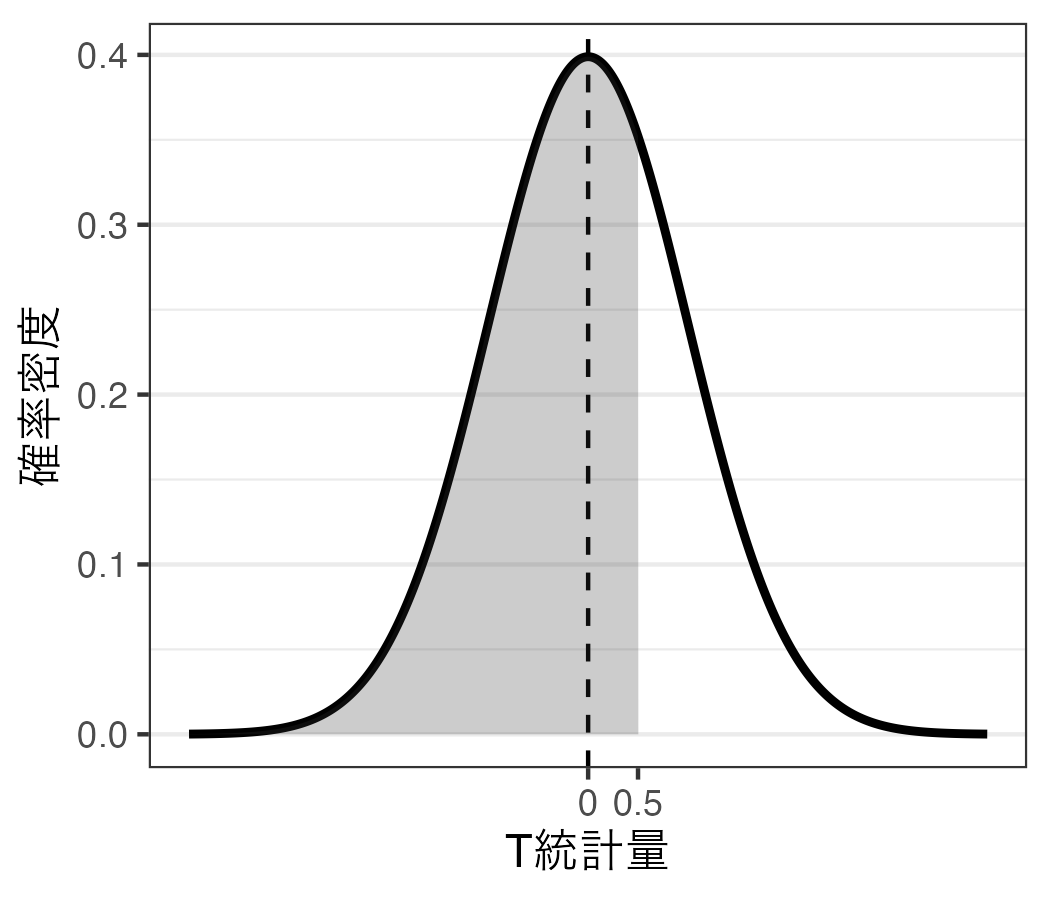
これを面積を計算するためには積分をするわけだが、簡単にいうと、まずは\(T\) 統計量が0.5以下 である確率(つまり、\(T \leq\) 0.5の面積)を求める(以下の図の左)。つづいて、\(T\) 統計量が-0.5以下 である確率(つまり、\(T \leq\) -0.5の面積)を求める(以下の図の右)。この2つの領域の差分が「\(T\) 統計量が-0.5以上、0.5以下の値を取る確率」となる。
ならば、\(T\) 統計量がぴったり0.5の確率はいくらだろう。これは言い換えると「\(T\) 統計量が0.5以上、0.5以下」であることを意味する。つまり、以下の2つの図の面積の差分を求めることになる。
当然ながらこの2つの面積は全く同じである。つまり、差分は0であり、統計量が特定の値を取る確率は常に0%である。これは\(p\) 値を「\(t\) 値がそうなる確率」と解釈することは間違いであることを意味し、したがって\(p\) 値を「帰無仮説が正しい確率(= \(T\) 値が0である確率)」と解釈することも間違いとなる。
棄却域の設定
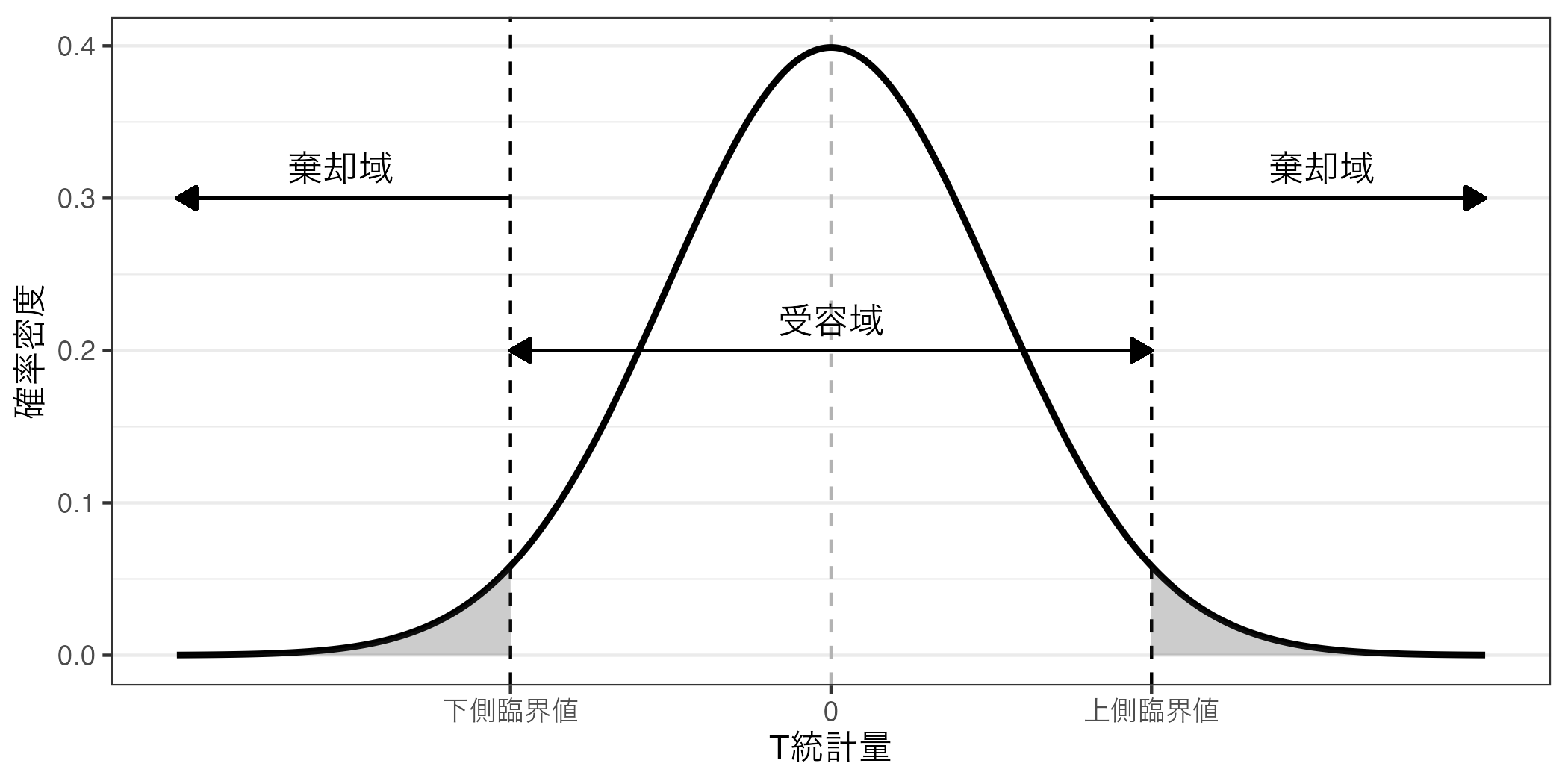
帰無仮説の棄却有無を判断するためには、つづいて「検定統計量がこの領域に入ると帰無仮説は棄却される」における「領域」を決める必要がある。これは言い換えると\(p\) 値が有意水準(\(\alpha\) )より小さくなるような境界線を意味し、臨界値 (critical value)とも呼ばれる。今回使用する\(t\) 分布の場合、左右対称であり、下側臨界値 (\(C_L\) )と上側臨界値 (\(C_U\) )が存在する(\(\chi^2\) 分布のように臨界値が一つのみ存在する確率分布もある)。
\(t\) 分布における臨界値の計算にはqt()関数を使用する。
# 下側臨界値: 第一引数には「有意水準 / 2」 qt (0.025 , df = 4771 ) # 有意水準が5% (0.05)の場合の下側臨界値
# 上側臨界値: 第一引数には「1 - (有意水準 / 2)」 qt (0.975 , df = 4771 ) # 有意水準が5% (0.05)の場合の上側臨界値
ここから得られた2つの値は臨界値であり、この2つの値の間の領域が受容域 (acceptance region)である。小さい方を\(C_L\) 、大きい方を\(C_U\) とした場合、受容域は[\(C_L\) , \(C_U\) ]となる。検定統計量が受容域に含まれると、帰無仮説を受容する。一方、受容域外の領域のことを棄却域 (rejection region)と呼び、(\(\infty\) , \(C_L\) )と(\(C_U\) , \(\infty\) )と行った2つの領域が存在する。検定統計量が棄却域に含まれると、帰無仮説を棄却し、対立仮説を支持する。
受容域と棄却域の関係を示したのが以下の図である。
帰無仮説の棄却と受容
ここまで出来たら帰無仮説が棄却できるかどうかの判断ができるようになる。帰無仮説の棄却有無を判断する以下の2つの方法がある。
方法1: 検定統計量と棄却域を比較する。
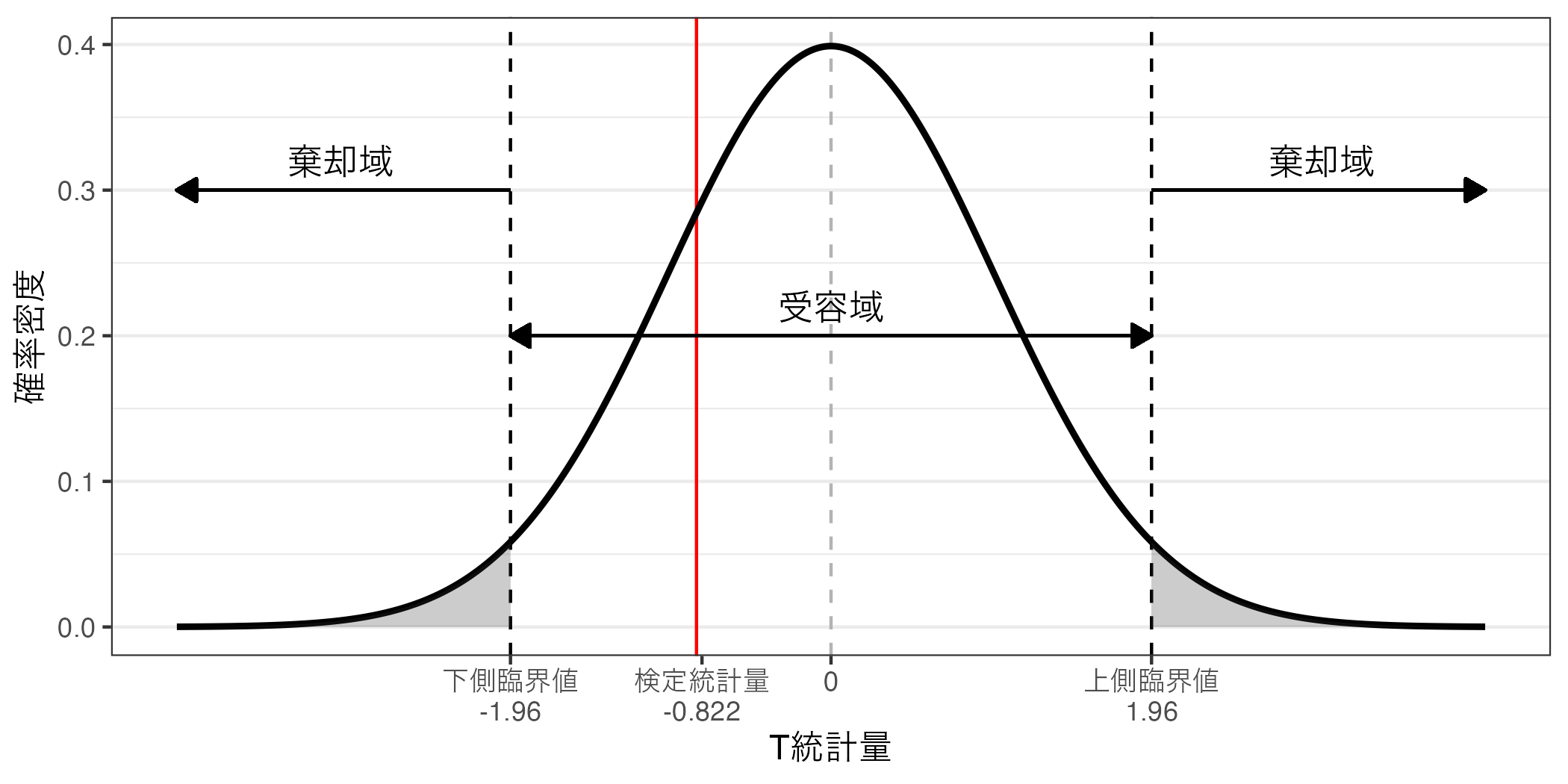
基本的な考え方としては手元のデータから得られた検定統計量が棄却域に含まれていれば帰無仮説を棄却し、対立仮説を支持 するという考え方である。もし、検定統計量が受容域に含まれている場合は帰無仮説を受容 する。今回のデータの場合、検定統計量は\(T\) 統計量であり、\(t = -0.822\) である。棄却域は(\(\infty\) , -1.960)、(1.960, \(\infty\) )である。言い換えると帰無仮説の棄却ができない受容域は[-1.960, 1.960]であり、今回の\(t\) は受容域に含まれる。したがって、帰無仮説は棄却できない。
方法2: \(p\) 値と有意水準(\(\alpha\) )を比較する。
こちらが最も簡単な方法でありながら、一般的な方法である。\(p\) 値の計算が必要だから面倒かも知れないが、Rの場合、\(p\) 値が自動的に計算されて出力されるケースがほとんどである。したがって、表示された\(p\) 値と自分があらかじめ決めておいた\(\alpha\) を比較し、\(p < \alpha\) なら帰無仮説を棄却する(= 対立仮説を支持する)。一方、\(p \geq \alpha\) なら帰無仮説を受容すると判断する。社会科学では\(\alpha = 0.05\) が一般的であるため、\(p < 0.05\) なら帰無仮説が棄却されたと判断することができる。\(p < \alpha\) の場合、検定統計量の絶対値は必ず棄却域内に位置し、\(p \geq \alpha\) なら受容域内に位置する。
今回得られた\(p\) 値は0.411であり、0.05以上である。つまり、検定統計量の絶対値\(|t|\) は受容域にする。したがって、帰無仮説は棄却されず受容される。
有意水準(\(\alpha\) )を大きく設定すると、帰無仮説は棄却されやすくなる(=対立仮説が支持されやすくなる)。つまり、自分の主張が支持されやすくなることを意味する。したがって、\(\alpha\) は検定統計量を求める前に予め決めておく必要がある。自分の仮説が支持されるように分析後に\(\alpha\) を決めることは研究倫理に反する。よほどの理由がない限り\(\alpha = 0.05\) に設定しておくのが無難であろう。
いずれの方法でも同じ結論が得られる。この帰無仮説が棄却される(=対立仮説が支持される)、帰無仮説が受容されるということは具体的に何を意味するだろうか。帰無仮説が正しい場合、\(\bar{x}\) と\(\mu_0\) の差は0であるため、\(|t| = 0\) となる。ただし、後述するが、「帰無仮説が正しい」ことは検証できない 。帰無仮説が棄却できなかった(=受容された)場合、「現時点では対立仮説が正しいとは言えない」だけであり、帰無仮説が正しいことを意味するものではない。一方、帰無仮説が棄却された場合は、対立仮説が支持されたと解釈し、\(\bar{x}\) と\(\mu_0\) の間に統計的 に有意味な差が存在することを意味する。
結論の提示
これまでの例の仮説は以下の通りである。
帰無仮説 (\(H_0\) ):SSRキャラクターの本当の出現確率は3%である。対立仮説 (\(H_a\) ):SSRキャラクターの本当の出現確率は3%ではない。
統計的仮説検定(今回は\(t\) 検定)の結果、\(p\) 値は0.411であり、\(\alpha\) (= 0.05) 以上であるため、帰無仮説は棄却されない。したがって、「SSRキャラクターの出現確率は3%でないとは言えない 。」と解釈する。注意してほしいのは「帰無仮説は正しい」、つまり「SSRキャラクターの出現確率は3%である。」と解釈しては行けないことだ。つまり、今回の例で帰無仮説が棄却されず、受容されたということは「開発元の主張が間違っているとは言えない(= 対立仮説が正しいとは言えない)」状態であることを意味する。今回の分析結果に基づくと、開発元を訴えることは難しいかも知れない。
もし、\(p < \alpha\) なら帰無仮説は棄却され、「SSRキャラクターの本当の出現確率は3%ではない。」と結論づけることが可能。この場合は、弁護士と相談し、集団訴訟を準備しよう。
また、95%信頼区間の求め方は前回講義と同じである。統計的有意、つまり帰無仮説が棄却される場合、95%信頼区間に\(\mu_0\) が含まれず、受容される場合は含まれる。今回は\(\mu_0 = 0.05\) が95%信頼区間内に含まれていることが分かる。
+ qt (0.025 , df = 4771 ) * se # 95%信頼区間の下限
+ qt (0.975 , df = 4771 ) * se # 95%信頼区間の上限
統計的有意性の罠
統計的仮説検定において自分の主張が支持されるためには、帰無仮説を棄却し、対立仮説が支持される必要がある。これは言い換えれば大きい\(|t|\) 、つまり小さい\(p\) が自分にとって都合の良いことを意味する。したがって、人間であれば、\(p\) を小さくしたいという誘引を持つ。
ここで、\(t = \frac{\bar{x} - \mu_0}{\sqrt{\frac{u}{n}}}\) を考えると、\(|t|\) が大きくなる条件とは以下の3つである。
\(|\bar{x}|\) が大きい\(u\) が小さい\(n\) が大きい
この中で研究者が決めることができるのは\(n\) だけだろう。\(n\) が大きいほど、\(p\) 値が小さくなり、帰無仮説が棄却されやすくなる(\(n\) を4倍にすると\(p\) 値は約半分に)。しかし、ここでよく考えてもらいたい。統計的推論の対象はあくまでも「母集団」である。しかし、統計的有意性検定の場合、「標本」の大きさが仮説の支持有無に影響を与える。実はこの2つの違いをしっかりと理解しておくことは重要だ。
帰無仮説が棄却できない、つまり受容されたケースを刑事裁判に例えて考えてみよう。刑事裁判では「無罪推定の原則」が採用されている。これは被告が無罪であることを前提に、裁判を進める仕組み である。これを仮説検定に適用すると帰無仮説と対立仮説は以下の通りとなる。
\(H_0\) : 容疑者Xは罪を犯していない(= 容疑者Xは無実)。\(H_a\) : 容疑者Xは罪を犯した(= 容疑者Xは犯人)。
ここで検察側の立証によって\(H_0\) が棄却されると、Xは有罪となる。一方、検察側が立証できなかった場合はどうだろう。つまり、帰無仮説が棄却できず受容されてしまったケースである。この場合、Xは無罪判決 になるだけであり、実は罪を犯したかも知れない。もし容疑者Xの犯罪が完全犯罪なら、検察の立証はできないだろう。ならば、容疑者Xが犯罪を起こしたことはなかったことになるだろうか。違うだろう。実際に犯罪を犯したかどうかと、判決は別次元の話である。
この例は統計的仮説検定と非常に似ている。帰無仮説が棄却できなかったことは、帰無仮説が間違ったことを意味するものではない。単純に、現在の証拠(データ)だけで「対立仮説が正しいとは結論づけることは出来ない」程度の、非常に弱い結論となる。一方、帰無仮説が棄却されれば、対立仮説の正しいことを強く主張できる[^enzai]。むろん、罪を犯していないにも関わらず、罪を犯したと判定してしまう可能性もある。この冤罪をどこまで許容するかが実は有意水準\(\alpha\) であり、社会科学であれば5%、人の健康に関わる分野になると1%か0.1%を採用するケースが多い。
もう一つの例を紹介しよう。1億2千万人の日本人を母集団とし、以下のようか仮説を立てたとしよう。
\(H_0\) :男性と女性の間に身長差はない。\(H_a\) :男性と女性の間に身長差がある。
ここで、日本国民から男性と女性、それぞれ3人ずつ無作為抽出し(\(n = 6\) )、平均身長を比較した結果、男女の平均身長が同じだったとしよう。つまり、男女間には統計的に有意な 身長差がない。ならば、帰無仮説「男性と女性の間に身長差はない。」は正しい結論だろうか。それは違うだろう。我々は既に男女の身長差があることを知っている。今回の\(n = 6\) のサンプルにおいて差はなかったかも知れないが、母集団レベルでは男女間の身長差はあるに違いない。つまり、今回のサンプルではその差がたまたま 検証できなかったことに過ぎず、母集団においては身長の差がある可能性も十分にあり得る。例えば、3人でなく、300人を抽出して仮説検定を行えばどうだろうか。多分、統計的に有意な差が得られるだろう(\(n\) が大きくなるほど、\(SE\) が小さくなるため、\(|t|\) が大きくなり、\(p\) が小さくなる)。
このように統計的仮説検定において、「帰無仮説が正しい」という結論を下すことはできない。これは言い換えると、「差がない」とか「ゼロである」という仮説は統計的仮説検定の対象にはなりにくいことを意味する(ベイズ統計学であれば可能)。
関数の使用
t.test()関数 以上の内容が平均値の検定(\(t\) 検定)であり、Rではt.test()関数で簡単に実装することができる。第一引数は検定対象となる変数のベクトル、mu引数には帰無仮説上の母数(\(\mu_0\) )を指定する。
# 帰無仮説においてSSRの確率は3%であるため、mu = 0.03 t.test (gacha_df$ result_SSR, mu = 0.03 )
One Sample t-test
data: gacha_df$result_SSR
t = -0.82249, df = 4226, p-value = 0.4108
alternative hypothesis: true mean is not equal to 0.03
95 percent confidence interval:
0.02294775 0.03288381
sample estimates:
mean of x
0.02791578
得られた\(p\) 値、信頼区間全てが手計算(?)と同じであることが確認できる。
prop.test()関 実は、扱う変数が0と1のみの値を取る(二値変数 ; binary variable)場合、その平均値は比率として解釈することができる。このように母集団における比率(母比率)を検証するときにはt.test()(\(t\) 検定)でなく、prop.test()(母比率の検定)を使ったほうが適切だ。
たとえば、4227回のガチャからSSRが118回出現し、帰無仮説上の母比率を3%(0.03)と仮定した場合の母比率の検定は以下のように行う。
# x: SSRが得られた回数 # n: ガチャの回数 # p: 帰無仮説におけるSSRの出現確率 (0 ~ 1) prop.test (x = 118 , n = 4227 , p = 0.05 , correct = FALSE )
1-sample proportions test without continuity correction
data: 118 out of 4227, null probability 0.05
X-squared = 43.401, df = 1, p-value = 4.459e-11
alternative hypothesis: true p is not equal to 0.05
95 percent confidence interval:
0.02336217 0.03332666
sample estimates:
p
0.02791578
\(t\) 検定の結果と比較してみよう。
t.test (gacha_df$ result_SSR, mu = 0.05 )
One Sample t-test
data: gacha_df$result_SSR
t = -8.7151, df = 4226, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0.05
95 percent confidence interval:
0.02294775 0.03288381
sample estimates:
mean of x
0.02791578
2つの結果はかなり近いものであり、どれも帰無仮説が受容される。それでも\(p\) 値、95%信頼区間などがやや異なる。これら2つの違いは検定統計量の計算方法から由来する。
\(t\) 検定の場合、検定統計量\(T\) は
\[
T = \frac{\bar{x} - \mu_0}{\text{SE}}
\]
であり、母比率の検定に使う検定統計量\(Z\) も
\[
Z = \frac{\hat{p} - p_0}{\text{SE}}
\]
である。\(\hat{p}\) (\(p\) ハット)は標本における割合なので、\(T\) 統計量の計算式における\(\bar{x}\) と同じだ。また、\(p_0\) は帰無仮説上における母比率だから、\(T\) 統計量の計算式における\(\mu_0\) と同じだ。2つの式は同じように見えるが、実は標準誤差(SE)の求め方が異なる。\(t\) 検定の場合、母分散(\(\sigma^2\) )が未知なので、不偏推定量である標本不偏分散の平方根(\(u^2\) )を使用する。しかし、0と1のみで構成されている変数の標準偏差は、割合によって決まっている。つまり、母比率を想定することができれば、母標準偏差も自動的に決まる仕組みだ。一方、\(t\) 検定の場合、\(\mu_0\) だけで\(\sigma^2\) が決まるわけではないため、やむを得ず\(u^2\) を使っているわけである。
\(t\) 検定の標準誤差は、
\[
\text{SE}_t = \sqrt{\frac{u^2}{n}} = \frac{u}{\sqrt{n}}
\]
であるが、母比率の検定における標準誤差は
\[
\text{SE}_z = \sqrt{\frac{p_0 (1 - p_0)}{n}}
\]
だ。帰無仮説で\(p_0\) を決めた時点で、標準誤差も同時に決まる。したがって、母比率の検定に使用される検定統計量\(Z\) は
# p_hat: 0.02791578 # p_0: 0.03 # n: 4227 0.02791578 - 0.03 ) / sqrt ((0.03 * (1 - 0.03 )) / 4227 )
となる(二値変数の分散は\(p (1 - p )\) である)。そしてこの\(Z\) は平均0、標準偏差1の標準正規分布 (\(t\) 検定の場合は自由度\(n-1\) の\(t\) 分布)に従っていることが知られているため、pt()の正規分布版であるpnorm()を使用して\(p\) 値を計算することができる。
# meanとsdの既定値はそれぞれ0, 1であるため、 # 今回はpnorm(-0.7943524) * 2のみでもOK() pnorm (- 0.7943524 , mean = 0 , sd = 1 ) * 2
prop.test()から得られた\(p\) 値と一致することが分かる。prop.test()関数に使用される検定統計量は\(\chi^2\) (カイ二乗)だが、これは先ほど計算した\(Z\) 統計量を二乗したものであり、本質的には同じだ。
また、臨界値を計算するためにはqnorm()関数を使う。以下では仮説検定における有意水準 (\(\alpha\) )を0.05とした場合の例である。
# meanとsdの既定値はそれぞれ0, 1であるため、 # 今回はqnorm(0.025); qnorm(0.975)のみでOK qnorm (0.025 , mean = 0 , sd = 1 ) # 下側臨界値
qnorm (0.975 , mean = 0 , sd = 1 ) # 上側臨界値
受容域は[-1.96, 1.96]であり、今回得られた検定統計量\(Z\) は-0.77であるため、受容域に含まれる。したがって、帰無仮説は棄却されない。\(p\) 値から判断しても同様である。\(p = 0.441\) であり、予め設定した\(\alpha = 0.05\) 以上であるため、帰無仮説は棄却されず受容される。つまり、「ガチャからSSRが得られる確率は3%でないとは言えない」と結論づけることができる。
厳密には二値変数の場合は母比率の検定(prop.test())を、連続変数の場合は\(t\) 検定(t.test())が望ましい。しかし、サンプルサイズ(\(n\) )が大きほど、\(t\) 分布は標準正規分布に近似するので、ほぼ同じ結果が得られる。