単回帰分析
まず、今回の実習に必要なパッケージ({tidyverse}、{summarytools}、{modelsummary})を読み込み、実習用データを読み込む。単回帰分析の実習用データはBeer.csvであり、LMSからダウンロード可能だ。以下のコードはBeer.csvがプロジェクト内のDataフォルダー内にアップロードされている場合の例である。データの保存先がDataフォルダーではない場合、適宜フォルダー名を修正すること。読み込んだデータはbeer_dfという名のオブジェクトとして作業環境内に格納する。
データを読み込んだら、データの中身を出力する。
library(tidyverse)
library(summarytools)
library(modelsummary)
beer_df <- read_csv("Data/Beer.csv")
beer_df
# A tibble: 69 × 5
Year Month Temperature Icecream Beer
<dbl> <dbl> <dbl> <dbl> <dbl>
1 2016 1 6.1 464 452
2 2016 2 7.2 397 584
3 2016 3 10.1 493 750
4 2016 4 15.4 617 835
5 2016 5 20.2 890 794
6 2016 6 22.4 883 961
7 2016 7 25.4 1292 1025
8 2016 8 27.1 1387 1021
9 2016 9 24.4 843 748
10 2016 10 18.7 621 730
# ℹ 59 more rows
{summarytools}のdescr()関数を使って記述統計量を出力する。beer_dfは数値型変数のみで構成されているため、ダミー変数に変換する変数はなく、そのままdescr()に渡して良い。
beer_df |>
descr(stats = c("mean", "sd", "min", "max", "n.valid"),
transpose = TRUE, order = "p")
Descriptive Statistics
beer_df
N: 69
Mean Std.Dev Min Max N.Valid
----------------- --------- --------- --------- --------- ---------
Year 2018.39 1.67 2016.00 2021.00 69.00
Month 6.30 3.41 1.00 12.00 69.00
Temperature 16.58 7.48 4.70 29.10 69.00
Icecream 790.65 335.15 382.00 1658.00 60.00
Beer 698.19 222.40 227.00 1313.00 69.00
今回は気温(Temperature)とアサヒスーパードライの販売量(Beer)の関係を確認したい。この2つの変数は連続変数であるため、関係性を見る方法としてまず考えられるのが相関分析である。前回講義の内容を参照し、2つの変数の相関係数を統計的有意性検定を行ってみよう(\(\alpha = 0.05\)を使用)。
cor.test(beer_df$Temperature, beer_df$Beer)
Pearson's product-moment correlation
data: beer_df$Temperature and beer_df$Beer
t = 2.0899, df = 67, p-value = 0.04042
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.01137629 0.45729570
sample estimates:
cor
0.2473909
相関係数は約0.247であり、(社会科学としては)そこそこ強い正の相関関係だと考えられる。つまり、気温が高い月はビールもよく売れていることを意味する。また、この相関関係は\(p\)値が約0.040であることから統計的に有意な相関関係とも言えよう。しかし、もう一つ知りたいことがある。それは「気温が1度上がればビールはどれほどもっと売れるか」である。相関係数はこの問いに対する答えを提供しない。ここで回帰分析と出番である。回帰分析は変数間の関係が線形関数で説明できると仮定する(線形性の仮定)。\(x\)の変動による\(y\)の変動は\(y = \alpha + \beta \times x\)のような一次関数として表現することができ、ここでの\(x\)が気温、\(y\)がアサヒスーパードライの販売量である。回帰分析はこの一次関数の切片(\(\alpha\))と傾き(\(\beta\))を推定する手法である。
線形回帰分析の場合、切片と傾き以外にももう一つ推定対象があり、それは誤差項の分散(\(\sigma\))である。また、切片と傾きは\(\alpha\)、\(\beta\)でなく、\(\beta_0\)、\(\beta_1\)と表記するケースもある。
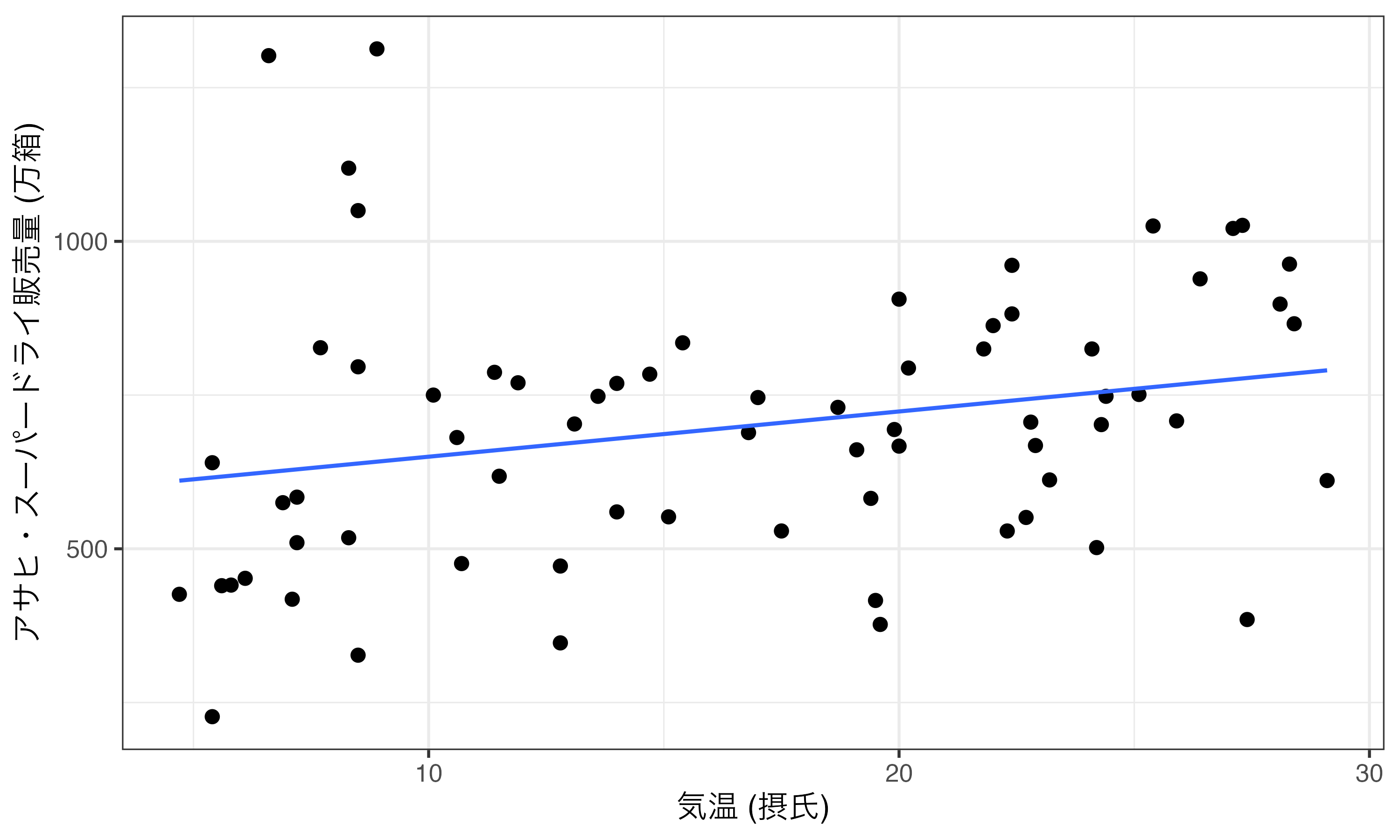
一次関数の切片と傾きがわかれば以下のような直線(=回帰直線)を描くことができる。
beer_df |>
ggplot(aes(x = Temperature, y = Beer)) +
geom_point(size = 3) +
geom_smooth(method = "lm", se = FALSE) +
labs(x = "気温 (摂氏)", y = "アサヒ・スーパードライ販売量 (万箱)") +
theme_bw(base_size = 16)
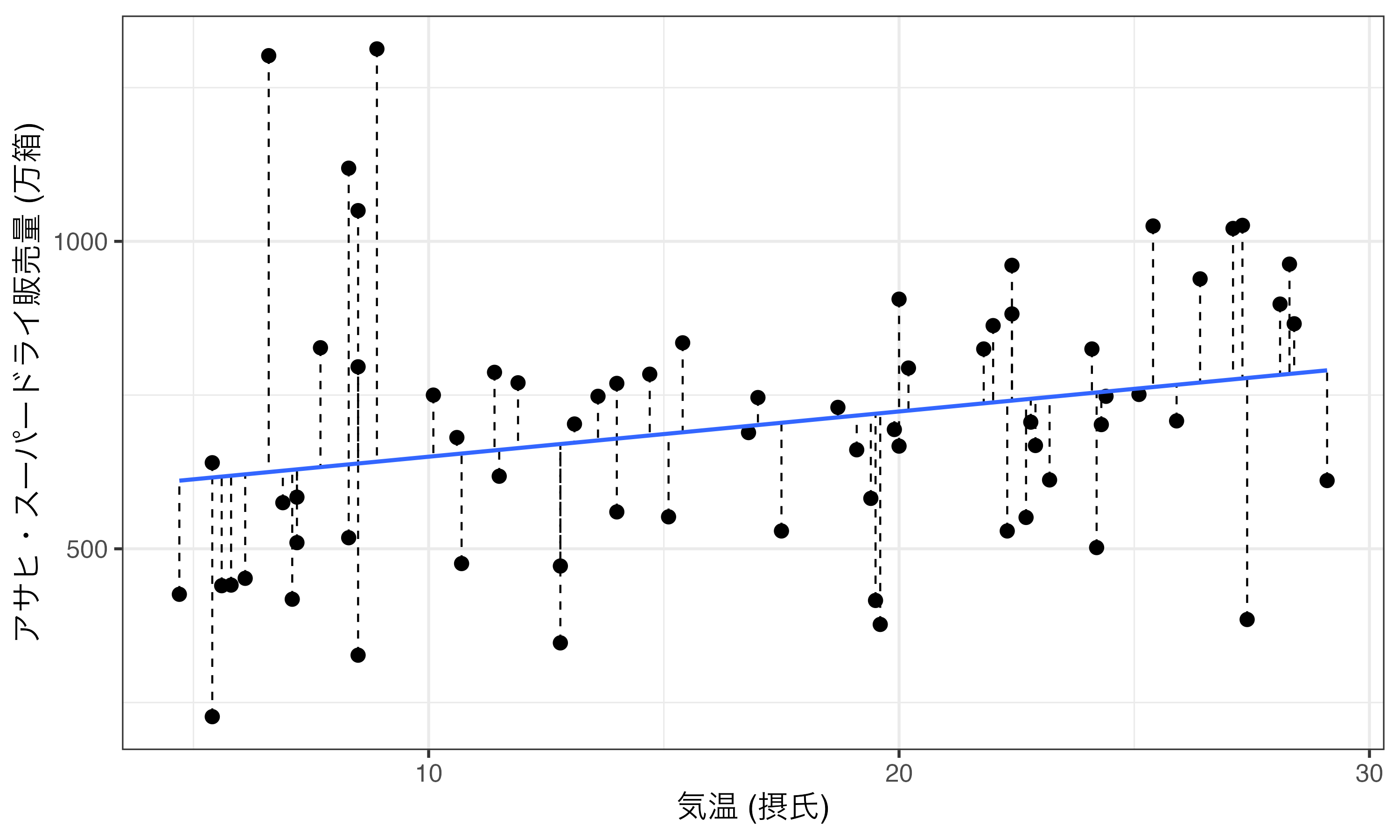
この回帰直線ってどのように決まるだろうか。それは残差の二乗和が最小化されるような直線である。残差とは任意の直線を引いた際、各点(観測値)と直線間の距離を意味する。観測値と直線間の距離は最短距離でなく、横軸に対して垂直方向の距離であることに注意すること(以下の図を参照)。ただし、この残差には符号が存在し、正と負が相殺される。したがって、全て正にするために残差を二乗する(絶対値を使うこともできるが、微分が大変なので使われない)。
この直線の切片と傾きはR内臓のlm()関数で簡単に計算できる。第一引数は回帰式であり、応答変数 ~ 説明変数と書く。第二引数はdataであり、回帰式に登場した変数が格納されているデータのオブジェクト名を指定する。今回の回帰式はBeer ~ Temperatureであり、この2つの変数はbeer_dfにあるため、data = beer_dfと指定する。推定結果は何らかの名前を付けて作業スペース内に格納する必要があるが、今回はbeer_fitと名付ける。推定結果を出力する際はsummary()関数を使用すること。
beer_fit <- lm(Beer ~ Temperature, data = beer_df)
summary(beer_fit)
Call:
lm(formula = Beer ~ Temperature, data = beer_df)
Residuals:
Min 1Q Median 3Q Max
-392.8 -169.1 -10.8 115.1 677.2
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 576.227 63.941 9.012 3.64e-13 ***
Temperature 7.355 3.519 2.090 0.0404 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 217.1 on 67 degrees of freedom
Multiple R-squared: 0.0612, Adjusted R-squared: 0.04719
F-statistic: 4.368 on 1 and 67 DF, p-value: 0.04042
(Intercept)は切片を、その以下の行は各変数の傾きを意味する。点推定値はEstimate列である。切片は約576.227、気温の傾きは7.355であることから以下のような関係が分かる。
アサヒスーパードライ販売量の予測値 = 576.227 + 7.355 \(\times\) 気温
これは「Temperatureが1上がると、Beerの値が平均的に7.355上がる」ことを意味する。Temperatureの1は1度、Beerの1は1万箱であるため、これをより自然な形で解釈すると、「気温が1度上がると、アサヒスーパードライの販売量は平均的に約7.355万箱上がる」となる。また、気温とビールの販売量間の関係が統計的に有意な関係かを確認するためには、傾きの統計的有意性検定が必要である。帰無仮説は「傾きは0である(=関係がない)」であり、今回得られた\(p\)値は約0.040であることから、統計的に有意な関係があると考えられる。もし、\(p \geq 0.05\)の場合は、「気温とビール販売量の間には統計的に有意な関係があるとは言えない」、または「気温とビール販売量の間には統計的に有意な関係が確認できない」こととなる。
推定の結果、回帰式は「アサヒスーパードライ販売量の予測値 = 576.227 + 7.355 \(\times\) 気温」のようになる。ここで注意すべき点は「予測値」だ。たとえば、2016年5月の場合、気温は20.2度である。これを代入すると「576.227 + 7.355 \(\times\) 20.2 \(\simeq\) 725」、つまり725万箱であり、これが予測値である。しかし、実際の販売量(観測値)は794万箱であり、約69万箱の差が存在する。この69万箱が2016年5月の残差であり、回帰分析はこの残差を最小化するような直線を推定する手法である。2つの変数間の相関係数が1、または-1でない限り、残差が0になることはない。
本モデルの説明力は決定係数から確認できる。Rの場合、デフォルトで2種類の決系係数が出力される。Multiple R-squaredが通常の決定係数、Adjusted R-squaredが自由度調整済み決定係数である。通常の決定係数は説明変数が増えると必ず大きくなるため、モデルのパフォーマンスの判断材料としては望ましくないとされる。一般的に、モデルはシンプルであるほど良い(オッカムの剃刀)と考えられるため、多少決定係数が小さくても説明変数の少ない方が良いモデルとされる。一方、自由度調整済み決定係数は説明変数が増えると決定係数にペナルティーを課するため、こちらの方がより適切である。いずれの決定係数も0以上1以下の値を取り、1に近いほど説明力の高いモデルであるとされる。
重回帰分析
以上の例のように、説明変数が1つのみの回帰分析は「単回帰分析」と呼ばれる。しかし、実際のデータ分析の場面において、ある応答変数を1つの変数だけで説明することは滅多になく、複数の説明変数を回帰式に投入する。このように説明変数が2つ以上の回帰分析を「重回帰分析」と呼ぶ。以下では重回帰分析の実装、解釈、モデル間の比較について解説する。
まず、実習に必要なデータを読み込む。重回帰分析の実習用データはPrefData.csvであり、LMSからダウンロード可能だ。以下のコードはPrefData.csvがプロジェクト内のDataフォルダー内にアップロードされている場合の例である。データの保存先がDataフォルダーではない場合、適宜フォルダー名を修正すること。読み込んだデータはpref_dfという名のオブジェクトとして作業環境内に格納する。
データを読み込んだら、データの中身を出力する。
pref_df <- read_csv("Data/PrefData.csv")
pref_df
# A tibble: 47 × 6
ID Pref Jimin Zaisei Over65 Primary
<dbl> <chr> <dbl> <dbl> <dbl> <dbl>
1 1 Hokkaido 32.8 0.435 29.2 7.00
2 2 Aomori 40.4 0.341 30.2 12.0
3 3 Iwate 34.9 0.352 30.5 10.6
4 4 Miyagi 36.7 0.614 25.9 4.36
5 5 Akita 43.5 0.309 33.9 9.62
6 6 Yamagata 42.5 0.351 30.9 9.19
7 7 Fukushima 33.8 0.533 28.8 6.48
8 8 Ibaraki 40.6 0.637 27.1 5.64
9 9 Tochigi 38.8 0.640 26.3 5.52
10 10 Gunma 42.1 0.625 28.1 4.96
# ℹ 37 more rows
分析の前にデータの記述統計量を出力する。今回は各行の番号(ID)と都道府県名(Pref)列の記述統計量は不要であるため、descr()関数に渡す前に2つの列を除外する。
pref_df |>
select(-c(ID, Pref)) |>
descr(stats = c("mean", "sd", "min", "max", "n.valid"),
transpose = TRUE, order = "p")
Descriptive Statistics
Mean Std.Dev Min Max N.Valid
------------- ------- --------- ------- ------- ---------
Jimin 38.71 5.43 22.12 48.24 47.00
Zaisei 0.51 0.19 0.25 1.10 47.00
Over65 28.52 2.72 19.76 33.94 47.00
Primary 5.64 3.14 0.39 12.03 47.00
ここでは「都道府県の財政力指数(Zaisei)が自民党得票率(Jimin)に与える影響」を調べるとし、まずは単回帰分析を実装する。
自民党の得票率の予測値 = \(\alpha\) + \(\beta \times\) 財政力指数
推定結果はjimin_fit1という名のオブジェクトとして作業環境内に格納し、summary()関数で推定結果を確認しよう。
jimin_fit1 <- lm(Jimin ~ Zaisei, data = pref_df)
summary(jimin_fit1)
Call:
lm(formula = Jimin ~ Zaisei, data = pref_df)
Residuals:
Min 1Q Median 3Q Max
-13.216 -2.900 0.652 3.526 9.110
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 45.291 2.049 22.106 < 2e-16 ***
Zaisei -13.012 3.800 -3.424 0.00133 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4.89 on 45 degrees of freedom
Multiple R-squared: 0.2067, Adjusted R-squared: 0.1891
F-statistic: 11.72 on 1 and 45 DF, p-value: 0.001326
推定結果から以下のような一次関数が得られた。
自民党の得票率の予測値 = 45.291 - 13.012 \(\times\) 財政力指数
これは「財政力指数が1上がると、自民党の得票率の予測値は約13.012%p下がる」ことを意味し、この関係は統計的に有意である(\(p\) = 0.001)。
ここで注意すべき点が2つある。1点目は係数の符号である。今回得られたZaiseiの傾き係数は負(マイナス)である。したがって、解釈の際は「\(x\)が上がると、\(y\)は下がる」と解釈する必要がある。2点目は予測値の単位だ。Jimin変数の場合、単位は「%(パーセント)」であるが、解釈の際は「%p(パーセントポイント)」となる。たとえば、財政力指数が0の都道府県の場合、自民党得票率の予測値は45.291%である。一方、財政力指数が1の場合のそれは32.279%だ。財政力指数が1あがったところで自民党得票率は45.291%から32.279%へ下がる。つまり、「45.291% - 32.279%」分下がるということであるが、この場合「13.012%下がる」と解釈してはいけない。正しい解釈は「13.012%p下がる」だ。この2つには大きな違いがある。たとえば、得票率が20%から40%へ上昇した場合の解釈は「100%上がる」か「20%p上がる」どっちかである。「%」の差分は「%」でなく「%p」であることに注意すること。
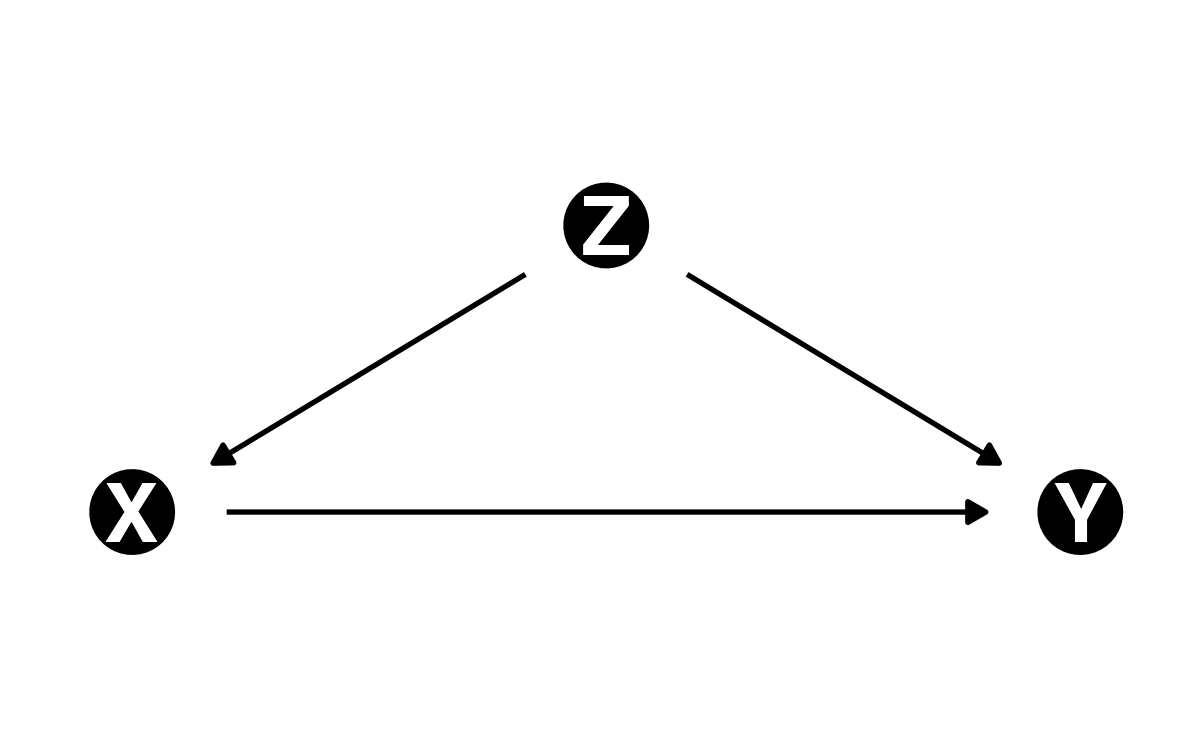
話を戻そう。我々は「原因以外の重要な要因」を考慮する必要があることを既に知っている(リサーチデザインの講義資料を参照)。とりわけ、\(y\)に影響を与えそうな要因の中には、\(x\)にも影響を与えそうな要因もある。この第3の変数を\(z\)と呼ぼう。
この\(z\)に該当する変数は無限に存在するが、手元のデータ(pref_df)内の変数が限られている。それでも出来る限り、手元も変数を最大限活用したい。たとえば、65歳以上人口の割合(Over65)はどうだろうか。基本的に高齢者が多い地域ほど財政力指数が低い傾向がある。また、政治学では高齢者ほど政治的に保守的イデオロギーを持つとも言われている(加齢効果)。したがって、65歳以上人口の割合(Over65)は\(z\)に該当すると考えられる。このような\(z\)は回帰分析の説明変数として加える必要がある。
それでは先程の単回帰モデルに65歳以上人口の割合(Over65)を加えた以下の回帰モデルを推定する。
自民党の得票率の予測値 = \(\alpha\) + \(\beta_1 \times\) 財政力指数 + \(\beta_2 \times\) 65歳以上人口の割合
推定対象は\(\alpha\)と\(\beta_1\)、\(\beta_2\)である。実装の方法は単回帰分析と同じであり、説明変数を+でつなぐだけである。推定結果はjimin_fit2という名のオブジェクトとして作業環境内に格納し、summary()関数で推定結果を確認しよう。
jimin_fit2 <- lm(Jimin ~ Zaisei + Over65, data = pref_df)
summary(jimin_fit2)
Call:
lm(formula = Jimin ~ Zaisei + Over65, data = pref_df)
Residuals:
Min 1Q Median 3Q Max
-13.6140 -2.8382 0.8015 3.1558 9.6759
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 15.8910 11.3983 1.394 0.1703
Zaisei -4.5472 4.8211 -0.943 0.3507
Over65 0.8810 0.3366 2.617 0.0121 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4.6 on 44 degrees of freedom
Multiple R-squared: 0.3135, Adjusted R-squared: 0.2823
F-statistic: 10.05 on 2 and 44 DF, p-value: 0.0002545
推定結果から以下のような一次関数が得られた。
自民党の得票率の予測値 = 15.891 - 4.547 \(\times\) 財政力指数 + 0.881 \(\times\) 65歳以上人口の割合
以上の結果を解釈すると「65歳以上人口の割合が同じである場合、財政力指数が1上がると、自民党の得票率の予測値は約4.547%p下がる」となる。
ここでも解釈の際、2つの注意点がある。1点目は変数の統制である。重回帰分析の結果を解釈する際は、解釈の対象とする変数以外の変数の値が同じあることを意識する必要がある。「65歳以上人口の割合の効果を除いた財政力指数の影響」とも言えよう。このような統制変数によって係数の大きさも変わりうる。実際、単回帰分析では-13.012だった点推定値が-4.547となった。これは単回帰分析から得られた-13.012%pという効果には、実際のところ、65際以上人口の割合の効果が混ざっていたことを意味する。2点目は統計的有意性である。今回の例だとZaiseiの係数の\(p\)値は約0.351となり、0.05を上回る。単回帰分析とは違って、ZaiseiとJiminの間には統計的に有意な関係があるとは言えないこととなる。したがって、正しい解釈は「他の変数が同じである場合、財政力指数と自民党の得票率の間には統計的に有意な関係があるとは言えない」、あるいは「他の変数が同じである場合、財政力指数が1上がると、自民党の得票率の予測値は約4.547%p下がるものの統計的に有意な関係があるとは言えない」となる。
説明変数はもっと増やすこともできる(厳密には\(n-1\)個まで投入できる)。たとえば、当該都道府県の第一次産業の割合(Primary)はどうだろうか。自民党の固い支持基盤としての農協(JA)、そして財政力指数の大きい部分を製造業(第二次産業)、サービス業(第三次産業)が占めることを考えると、これもまた「第3の変数」であろう。先程のjimin_fit2モデルにPrimaryを追加したモデルも推定してみよう。
jimin_fit3 <- lm(Jimin ~ Zaisei + Over65 + Primary, data = pref_df)
summary(jimin_fit3)
Call:
lm(formula = Jimin ~ Zaisei + Over65 + Primary, data = pref_df)
Residuals:
Min 1Q Median 3Q Max
-13.6296 -2.8400 0.8063 3.1514 9.6538
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 15.914364 11.576998 1.375 0.1764
Zaisei -4.630626 6.131046 -0.755 0.4542
Over65 0.883231 0.355203 2.487 0.0169 *
Primary -0.008154 0.363066 -0.022 0.9822
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4.654 on 43 degrees of freedom
Multiple R-squared: 0.3135, Adjusted R-squared: 0.2656
F-statistic: 6.547 on 3 and 43 DF, p-value: 0.0009578
推定結果から以下のような一次関数が得られた。
自民党の得票率の予測値 = 15.914 - 4.631 \(\times\) 財政力指数 + 0.883 \(\times\) 65歳以上人口の割合 - 0.008 \(\times\) 第一産業従事者の割合
これまで3つのモデルを推定してきたが、モデル間の比較する際には{modelsummary}パッケージが便利だ。{modelsummary}のmodelsummary()関数の第一引数として推定結果のオブジェクトをlist()でまとめて入れるだけである。
# ない場合はinstall.packages("modelsummary")でインストール
library(modelsummary)
modelsummary(list(jimin_fit1, jimin_fit2, jimin_fit3))
| (Intercept) |
45.291 |
15.891 |
15.914 |
|
(2.049) |
(11.398) |
(11.577) |
| Zaisei |
−13.012 |
−4.547 |
−4.631 |
|
(3.800) |
(4.821) |
(6.131) |
| Over65 |
|
0.881 |
0.883 |
|
|
(0.337) |
(0.355) |
| Primary |
|
|
−0.008 |
|
|
|
(0.363) |
| Num.Obs. |
47 |
47 |
47 |
| R2 |
0.207 |
0.314 |
0.314 |
| R2 Adj. |
0.189 |
0.282 |
0.266 |
| AIC |
286.5 |
281.7 |
283.7 |
| BIC |
292.1 |
289.1 |
293.0 |
| Log.Lik. |
−140.269 |
−136.869 |
−136.869 |
| F |
11.724 |
10.048 |
6.547 |
| RMSE |
4.79 |
4.45 |
4.45 |
カッコで囲まれている数値は標準誤差(Standard Error; SE)である。一般的な学術論文では\(p\)値よりも標準誤差の掲載が一般的である(標準誤差から\(p\)値の計算は簡単だが、その逆は面倒だから)。もし、標準誤差の代わりに\(p\)値を掲載する場合は以下のようにコードを修正する(statistic引数の追加)。また、coef_rename引数で変数名の任意の文字列に変更することも出来、notes引数で注を付けることもできる。
modelsummary(list(jimin_fit1, jimin_fit2, jimin_fit3),
statistic = "({p.value})",
coef_rename = c("(Intercept)" = "切片",
"Zaisei" = "財政力指数",
"Over65" = "65歳以上人口の割合",
"Primary" = "第一次産業従事者の割合"),
notes = "注: カッコ内はp値")
| 切片 |
45.291 |
15.891 |
15.914 |
|
(<0.001) |
(0.170) |
(0.176) |
| 財政力指数 |
−13.012 |
−4.547 |
−4.631 |
|
(0.001) |
(0.351) |
(0.454) |
| 65歳以上人口の割合 |
|
0.881 |
0.883 |
|
|
(0.012) |
(0.017) |
| 第一次産業従事者の割合 |
|
|
−0.008 |
|
|
|
(0.982) |
| Num.Obs. |
47 |
47 |
47 |
| R2 |
0.207 |
0.314 |
0.314 |
| R2 Adj. |
0.189 |
0.282 |
0.266 |
| AIC |
286.5 |
281.7 |
283.7 |
| BIC |
292.1 |
289.1 |
293.0 |
| Log.Lik. |
−140.269 |
−136.869 |
−136.869 |
| F |
11.724 |
10.048 |
6.547 |
| RMSE |
4.79 |
4.45 |
4.45 |
| 注: カッコ内はp値 |
|
|
|
自由度調整済み決定係数は「R2 Adj.」行から確認できる。最も高いモデルは財政力指数と65歳以上人口の割合のみに構成されて2番目のモデル(jimin_fit2)である。第一次産業従事者の割合まで追加した3番目のモデルは、やや低い決定係数が得られた。追加された「第一次産業従事者の割合」の係数が非常に小さく、統計的に有意な関係も見られない。つまり、どちらかの言えば「不要(\(\simeq\)あっても良いが、入れて得することもない)」に近い変数であることを意味する。説明力が同じであれば、説明変数は少ないことに越したことはないので、モデル2がより望ましいと評価できよう。