23 表の作成
記述統計や推定結果を示す場合は図表が用いられることが多い。図に関しては{ggplot2}が最もポピュラーなパッケージである(Base Rもまた根強い人気を誇る)。一方、表の場合、現時点において2つの選択肢がある1。一つはこれまで長らく使われてきた{knitr}パッケージのkable()(= kbl())と{kabelExtra}パッケージの組み合わせ、もう一つが近年注目を集めている{gt}パッケージだ。
{gt}はGrammar of Tablesの略であり、Grammar of Graphicsの具現化した{ggplot2}の影響を受けたものである。つまり、一つの表を独立した要素に分解し、それぞれのレイヤーを重ねていくイメージだ。{ggplot2}の考え方(\(\neq\)使い方)に慣れている読者なら{gt}にもすぐ慣れるだろう。ただし、{gt}は開発途上であり、PDF出力との相性が現在 (2025年01月15日; {gt} 0.11.1)、優れているとはいい難い。表をPDF形式に出力したいのであれば{knitr}のkable() + {kableExtra}を推奨する。また、{gt}単体での機能はkable() + {kableExtra}より貧弱ではあったものの、現在は{gtExtras}の登場により、ほぼ同じことが行えるようになった。
ここではRStudio社が開発をサポートしている{gt}パッケージについて簡単に解説する2。また、どのパッケージもHTML出力とLaTeX出力両方に対応しているが、ここではHTML出力のみ紹介する。ただし、LaTeX出力に関しては引数の追加などで簡単にできるため、詳細は各パッケージの公式ページやヴィネット等を参考されたい。
それではまず、実習に使用するパッケージとデータを読み込でおこう。
# A tibble: 7 × 6
Variable Mean SD Min Max Obs
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Population 41.7 151. 0.000801 1447. 186
2 Area 69.6 187. 0 1638. 186
3 GDP_per_capita 1.62 2.57 0.00577 18.3 185
4 PPP_per_capita 2.08 2.10 0.0733 11.3 178
5 HDI_2018 0.713 0.153 0.377 0.954 180
6 Polity_Score 4.26 6.10 -10 10 158
7 FH_Total 57.7 29.9 0 100 185# A tibble: 35 × 7
Continent Variable Mean SD Min Max Obs
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Africa Population 24.6 35.9 0.0983 206. 54
2 Africa Area 54.4 59.2 0.046 238. 54
3 Africa GDP_per_capita 0.251 0.313 0.00577 1.73 54
4 Africa PPP_per_capita 0.567 0.602 0.0733 2.78 52
5 Africa HDI_2018 0.553 0.109 0.377 0.801 53
6 Africa Polity_Score 2.48 5.00 -9 10 48
7 Africa FH_Total 41.6 25.1 2 92 54
8 America Population 28.7 66.3 0.0532 334. 36
9 America Area 108. 246. 0.026 916. 36
10 America GDP_per_capita 1.25 1.27 0.0745 6.44 36
# ℹ 25 more rows# A tibble: 5 × 8
Continent Population Area GDP PPP HDI Polity FH
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Africa 24.6 54.4 0.251 0.567 0.553 2.48 41.6
2 America 28.7 108. 1.25 1.81 0.742 6.93 71.9
3 Asia 107. 70.2 1.32 2.27 0.723 0.342 38.9
4 Europe 17.1 46.5 3.56 3.78 0.861 7.93 79.4
5 Oceania 10.0 210. 2.66 2.76 0.782 7.25 79 # A tibble: 178 × 3
Country Continent PPP_per_capita
<chr> <chr> <dbl>
1 Afghanistan Asia 2125.
2 Albania Europe 13781.
3 Algeria Africa 11324.
4 Angola Africa 6649.
5 Antigua and Barbuda America 21267.
6 Argentina America 22938.
7 Armenia Europe 12974.
8 Australia Oceania 50001.
9 Austria Europe 55824.
10 Azerbaijan Europe 14257.
# ℹ 168 more rows# A tibble: 6 × 3
Name Hex Download
<chr> <chr> <dbl>
1 dplyr https://github.com/rstudio/hex-stickers/blob/main/thumbs/dplyr.png?raw=true 35720
2 quarto https://github.com/rstudio/hex-stickers/blob/main/thumbs/quarto.png?raw=true 171
3 ggplot2 https://github.com/rstudio/hex-stickers/blob/main/thumbs/ggplot2.png?raw=true 44403
4 shiny https://github.com/rstudio/hex-stickers/blob/main/thumbs/shiny.png?raw=true 10795
5 rmarkdown https://github.com/rstudio/hex-stickers/blob/main/thumbs/rmarkdown.png?raw=true 23038
6 tidyverse https://github.com/rstudio/hex-stickers/blob/main/thumbs/tidyverse.png?raw=true 3909423.1 表の出力
{gt}では、表がタイトル、列ラベル、ホディ―などの要素で構成されている考え( 図 23.1 )、それぞれの要素を追加したり、修正する形で表を作成する。

まず、これまで使ってきたdf1を使ってHTML形式の表を出力してみよう。使用する関数はgt()であり、data.frameまたはtibbleオブジェクト名が第1引数である。
| Variable | Mean | SD | Min | Max | Obs |
|---|---|---|---|---|---|
| Population | 41.7377735 | 151.2702976 | 0.000801000 | 1447.47009 | 186 |
| Area | 69.6069247 | 187.2412489 | 0.000000000 | 1637.68700 | 186 |
| GDP_per_capita | 1.6158103 | 2.5710359 | 0.005770007 | 18.31772 | 185 |
| PPP_per_capita | 2.0833383 | 2.0992134 | 0.073314173 | 11.34231 | 178 |
| HDI_2018 | 0.7134833 | 0.1528503 | 0.377000000 | 0.95400 | 180 |
| Polity_Score | 4.2594937 | 6.1022919 | -10.000000000 | 10.00000 | 158 |
| FH_Total | 57.7135135 | 29.8656244 | 0.000000000 | 100.00000 | 185 |
23.2 列の操作
これだけでも十分に綺麗な表が出来上がった。それではこちらの表を少しずつ修正してみよう。まず、Mean列からMax列だが、これを小数点3桁で丸めてみよう。これらの数字は 図 23.1 のTable Bodyに該当する。このTable Bodyのフォーマットに関わる調整はfmt_*()関数を使用する。Mean列からMax列までの数値に関する調整はfmt_number()関数を使用する。gt()で作成された表オブジェクトをそのままfmt_number()に渡し、columns引数で何列に当該内容を適用するかを指定する。たとえば、Mean列からMax列までは2〜5列目に相当するのでcolumns = 2:5、またはcolumns = c(2, 3, 4, 5)で良い。続いて、小数点の桁数を指定するdecimalsに3を指定してみよう。
| Variable | Mean | SD | Min | Max | Obs |
|---|---|---|---|---|---|
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
columnsは列の番号じゃなく、列名そのままでも指定できる。
| Variable | Mean | SD | Min | Max | Obs |
|---|---|---|---|---|---|
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
列名の変更はcols_lable()レイヤーで行う。()内には"元の列名" = "新しい列名"のように記述する。{knitr} + {kableExtra}のkable()(kbl())は全ての列に対して列名を指定しないといけなかったが(つまり、変更したくない列も一応、指定が必要)、{gt}だと変更したい列のみ指定しても良いといったメリットがある。
df1 |>
gt() |>
fmt_number(columns = 2:5, decimals = 3) |>
cols_label("Variable" = "変数", "Mean" = "平均値", "SD" = "標準偏差",
"Min" = "最小値", "Max" = "最大値", "Obs" = "有効ケース数")| 変数 | 平均値 | 標準偏差 | 最小値 | 最大値 | 有効ケース数 |
|---|---|---|---|---|---|
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
もう一つ見たいこところは、各セル内のテキストの揃えだ。たとえば、文字型列のVariableは左揃え、数値型列であるその他の列は右揃えになっている。これはこのままで問題ない。しかし、どうしても特定の列を中央揃えしたい時もあるだろう。その場合、cols_align()レイヤーで修正することができる。たとえば、Variable列の値を中央揃えに変えてみよう。引数はalignで"left"、"center"、"right"のいずれかを、columnsには適用したい列の番号、または列名を指定する。
df1 |>
gt() |>
fmt_number(columns = 2:5, decimals = 3) |>
cols_align(align = "center", columns = 1) # columns = Variable でもOK| Variable | Mean | SD | Min | Max | Obs |
|---|---|---|---|---|---|
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
また、各列のラベル(図 23.1 のcolumn labels)の位置も表のボディー(図 23.1 のtable body)に連動する。もし、列ラベルのみ中央揃えにしたい場合はtab_style()レイヤーを使用する。
df1 |>
gt() |>
fmt_number(columns = 2:5, decimals = 3) |>
tab_style(style = cell_text(align = "center"),
locations = cells_column_labels())- 1
- セル内のテキストを中央揃えにする。
- 2
- 列ラベルのみに適用
| Variable | Mean | SD | Min | Max | Obs |
|---|---|---|---|---|---|
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
また、HTMLのCSSによって異なるが、{gt}で作成された表の幅がページの幅に強制的に調整される場合がある。本書はQuartoで執筆されているが、まさにそのケースである)。この場合は、as_raw_html()を使えば良い。一つ注意すべき点はas_raw_html()は必ず最後のレイヤーにする必要がある。as_raw_html()の後ろにレイヤーが足される場合はエラーが発生する。
このas_raw_html()は必要に応じて入れる。R Markdown/Quartoを使わない場合はそもそも不要だ(RStudioのViewerペインでは問題なく表示される)。もし、R Markdown/Quartoで{gt}を使用し、表の幅が気に入らない場合のみ使うことにしよう。ちなみに本書はas_raw_html()を省略しても表の幅がページ幅に強制調整されないように設定されている。
23.3 タイトル・フットノート
表のタイトルおよびサブタイトルはtab_header()関数のtitleとsubtitle引数で指定できる。また、表の下段に位置するフットノート(footnote)とソースノート(source note)は別の関数に対応し、それぞれtab_footnote()とtab_source_note()を使う。使用する引数はそれぞれfootnoteとsource_noteであるが、第1引数であるため、省略可能だ。
df1 |>
gt() |>
fmt_number(columns = 2:5, decimals = 3) |>
tab_header(title = "タイトル", subtitle = "サブタイトル") |>
tab_footnote(footnote = "注: ここにはフットノートが入る") |>
tab_source_note(source_note = "出典: 『私たちのR』")| タイトル | |||||
| サブタイトル | |||||
| Variable | Mean | SD | Min | Max | Obs |
|---|---|---|---|---|---|
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
| 出典: 『私たちのR』 | |||||
| 注: ここにはフットノートが入る | |||||
ちなみに、tab_footnote()やtab_source_note()は複数回使用することで複数行にすることができる。
df1 |>
gt() |>
fmt_number(columns = 2:5, decimals = 3) |>
tab_header(title = "タイトル", subtitle = "サブタイトル") |>
tab_footnote(footnote = "注1: ここにはフットノート1が入る") |>
tab_footnote(footnote = "注2: ここにはフットノート2が入る") |>
tab_source_note(source_note = "出典: 『私たちのR』")| タイトル | |||||
| サブタイトル | |||||
| Variable | Mean | SD | Min | Max | Obs |
|---|---|---|---|---|---|
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
| 出典: 『私たちのR』 | |||||
| 注1: ここにはフットノート1が入る | |||||
| 注2: ここにはフットノート2が入る | |||||
また、タイトルやフットノートに限定された機能ではないが、テキストはMarkdownやHTML文法で書くこともできる。たとえば、上記のコードの『私たちのR』にリンクを貼る場合、Markdown文法だと"『[私たちのR](https://www.jaysong.net/RBook/)』"となるが、このままではうまくいかない。
df1 |>
gt() |>
fmt_number(columns = 2:5, decimals = 3) |>
tab_header(title = "タイトル", subtitle = "サブタイトル") |>
tab_footnote(footnote = "注1: ここにはフットノート1が入る") |>
tab_footnote(footnote = "注2: ここにはフットノート2が入る") |>
tab_source_note(source_note = "出典: 『[私たちのR](https://www.jaysong.net/RBook/)』")| タイトル | |||||
| サブタイトル | |||||
| Variable | Mean | SD | Min | Max | Obs |
|---|---|---|---|---|---|
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
| 出典: 『[私たちのR](https://www.jaysong.net/RBook/)』 | |||||
| 注1: ここにはフットノート1が入る | |||||
| 注2: ここにはフットノート2が入る | |||||
Markdown文法を使う場合は、文字列をmd()関数内で指定することでMarkdown文として解釈されるようになる。
df1 |>
gt() |>
fmt_number(columns = 2:5, decimals = 3) |>
tab_header(title = "タイトル", subtitle = "サブタイトル") |>
tab_footnote(footnote = "注1: ここにはフットノート1が入る") |>
tab_footnote(footnote = "注2: ここにはフットノート2が入る") |>
tab_source_note(source_note = md("出典: 『[私たちのR](https://www.jaysong.net/RBook/)』"))| タイトル | |||||
| サブタイトル | |||||
| Variable | Mean | SD | Min | Max | Obs |
|---|---|---|---|---|---|
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
| 出典: 『私たちのR』 | |||||
| 注1: ここにはフットノート1が入る | |||||
| 注2: ここにはフットノート2が入る | |||||
23.4 グループ化
列をグループ化するためにはtab_spanner()関数を使う。columns引数にはグループ化する列の位置、もしくは名前を、labelにはグループ名を指定すれば良い。たとえば、df1を使う場合、MinとMax列を一つのグループとしてRangeと名付けるとしよう。columnsは列の番号でも、列名でも良い。
df1 |>
gt() |>
tab_spanner(columns = 4:5, label = "Range") |>
fmt_number(columns = 2:5, decimals = 3)| Variable | Mean | SD |
Range
|
Obs | |
|---|---|---|---|---|---|
| Min | Max | ||||
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
続いて、行をグループ化する方法について紹介する。まず、df2の中身を確認してみよう。
| Continent | Variable | Mean | SD | Min | Max | Obs |
|---|---|---|---|---|---|---|
| Africa | Population | 24.5609472 | 35.90062114 | 0.098347000 | 206.139589 | 54 |
| Africa | Area | 54.4435111 | 59.21810613 | 0.046000000 | 238.174000 | 54 |
| Africa | GDP_per_capita | 0.2514072 | 0.31334566 | 0.005770007 | 1.727394 | 54 |
| Africa | PPP_per_capita | 0.5667087 | 0.60151933 | 0.073314173 | 2.778814 | 52 |
| Africa | HDI_2018 | 0.5532642 | 0.10889924 | 0.377000000 | 0.801000 | 53 |
| Africa | Polity_Score | 2.4791667 | 5.00208290 | -9.000000000 | 10.000000 | 48 |
| Africa | FH_Total | 41.5740741 | 25.12955251 | 2.000000000 | 92.000000 | 54 |
| America | Population | 28.7362271 | 66.28460983 | 0.053199000 | 334.308644 | 36 |
| America | Area | 108.1607833 | 245.85173673 | 0.026000000 | 915.802000 | 36 |
| America | GDP_per_capita | 1.2526519 | 1.27016543 | 0.074535927 | 6.444591 | 36 |
| America | PPP_per_capita | 1.8100292 | 1.26006234 | 0.176587508 | 6.178997 | 35 |
| America | HDI_2018 | 0.7424722 | 0.09094975 | 0.466000000 | 0.922000 | 36 |
| America | Polity_Score | 6.9259259 | 3.59407553 | -5.000000000 | 10.000000 | 27 |
| America | FH_Total | 71.9166667 | 22.42750225 | 14.000000000 | 98.000000 | 36 |
| Asia | Population | 107.3001606 | 301.72686527 | 0.437479000 | 1447.470092 | 42 |
| Asia | Area | 70.1983405 | 155.92487158 | 0.030000000 | 938.929100 | 42 |
| Asia | GDP_per_capita | 1.3167525 | 1.70584531 | 0.049067972 | 6.368026 | 42 |
| Asia | PPP_per_capita | 2.2728133 | 2.40667620 | 0.139610508 | 9.525177 | 41 |
| Asia | HDI_2018 | 0.7228537 | 0.12010715 | 0.463000000 | 0.935000 | 41 |
| Asia | Polity_Score | 0.3421053 | 7.48431266 | -10.000000000 | 10.000000 | 38 |
| Asia | FH_Total | 38.9285714 | 25.15453977 | 0.000000000 | 96.000000 | 42 |
| Europe | Population | 17.1127533 | 29.05674254 | 0.000801000 | 145.934462 | 50 |
| Europe | Area | 46.4618980 | 230.34717622 | 0.000000000 | 1637.687000 | 50 |
| Europe | GDP_per_capita | 3.5575266 | 3.86463361 | 0.296369600 | 18.317721 | 49 |
| Europe | PPP_per_capita | 3.7782593 | 2.12763785 | 0.842873869 | 11.342306 | 46 |
| Europe | HDI_2018 | 0.8611304 | 0.06306914 | 0.711000000 | 0.954000 | 46 |
| Europe | Polity_Score | 7.9268293 | 4.23314448 | -7.000000000 | 10.000000 | 41 |
| Europe | FH_Total | 79.4285714 | 22.70187217 | 10.000000000 | 100.000000 | 49 |
| Oceania | Population | 10.0465332 | 10.81385119 | 0.896445000 | 25.499884 | 4 |
| Oceania | Area | 210.4312500 | 372.29122053 | 1.827000000 | 768.230000 | 4 |
| Oceania | GDP_per_capita | 2.6577585 | 2.60067976 | 0.279082855 | 5.461517 | 4 |
| Oceania | PPP_per_capita | 2.7572651 | 2.19837188 | 0.417111768 | 5.000127 | 4 |
| Oceania | HDI_2018 | 0.7815000 | 0.18631604 | 0.543000000 | 0.938000 | 4 |
| Oceania | Polity_Score | 7.2500000 | 3.20156212 | 4.000000000 | 10.000000 | 4 |
| Oceania | FH_Total | 79.0000000 | 20.80064102 | 60.000000000 | 97.000000 | 4 |
各大陸ごとの人口、面積などの情報が含まれている表であるが、これらを大陸単位で行をグループ化してみよう。方法は簡単だ。{dplyr}のようにgt()関数に渡す前に、group_by()でデータをグループ化すれば良い。今回はContinent列の値に基づいてグループ化するため、group_by(Continent)とする。
| Variable | Mean | SD | Min | Max | Obs |
|---|---|---|---|---|---|
| Africa | |||||
| Population | 24.5609472 | 35.90062114 | 0.098347000 | 206.139589 | 54 |
| Area | 54.4435111 | 59.21810613 | 0.046000000 | 238.174000 | 54 |
| GDP_per_capita | 0.2514072 | 0.31334566 | 0.005770007 | 1.727394 | 54 |
| PPP_per_capita | 0.5667087 | 0.60151933 | 0.073314173 | 2.778814 | 52 |
| HDI_2018 | 0.5532642 | 0.10889924 | 0.377000000 | 0.801000 | 53 |
| Polity_Score | 2.4791667 | 5.00208290 | -9.000000000 | 10.000000 | 48 |
| FH_Total | 41.5740741 | 25.12955251 | 2.000000000 | 92.000000 | 54 |
| America | |||||
| Population | 28.7362271 | 66.28460983 | 0.053199000 | 334.308644 | 36 |
| Area | 108.1607833 | 245.85173673 | 0.026000000 | 915.802000 | 36 |
| GDP_per_capita | 1.2526519 | 1.27016543 | 0.074535927 | 6.444591 | 36 |
| PPP_per_capita | 1.8100292 | 1.26006234 | 0.176587508 | 6.178997 | 35 |
| HDI_2018 | 0.7424722 | 0.09094975 | 0.466000000 | 0.922000 | 36 |
| Polity_Score | 6.9259259 | 3.59407553 | -5.000000000 | 10.000000 | 27 |
| FH_Total | 71.9166667 | 22.42750225 | 14.000000000 | 98.000000 | 36 |
| Asia | |||||
| Population | 107.3001606 | 301.72686527 | 0.437479000 | 1447.470092 | 42 |
| Area | 70.1983405 | 155.92487158 | 0.030000000 | 938.929100 | 42 |
| GDP_per_capita | 1.3167525 | 1.70584531 | 0.049067972 | 6.368026 | 42 |
| PPP_per_capita | 2.2728133 | 2.40667620 | 0.139610508 | 9.525177 | 41 |
| HDI_2018 | 0.7228537 | 0.12010715 | 0.463000000 | 0.935000 | 41 |
| Polity_Score | 0.3421053 | 7.48431266 | -10.000000000 | 10.000000 | 38 |
| FH_Total | 38.9285714 | 25.15453977 | 0.000000000 | 96.000000 | 42 |
| Europe | |||||
| Population | 17.1127533 | 29.05674254 | 0.000801000 | 145.934462 | 50 |
| Area | 46.4618980 | 230.34717622 | 0.000000000 | 1637.687000 | 50 |
| GDP_per_capita | 3.5575266 | 3.86463361 | 0.296369600 | 18.317721 | 49 |
| PPP_per_capita | 3.7782593 | 2.12763785 | 0.842873869 | 11.342306 | 46 |
| HDI_2018 | 0.8611304 | 0.06306914 | 0.711000000 | 0.954000 | 46 |
| Polity_Score | 7.9268293 | 4.23314448 | -7.000000000 | 10.000000 | 41 |
| FH_Total | 79.4285714 | 22.70187217 | 10.000000000 | 100.000000 | 49 |
| Oceania | |||||
| Population | 10.0465332 | 10.81385119 | 0.896445000 | 25.499884 | 4 |
| Area | 210.4312500 | 372.29122053 | 1.827000000 | 768.230000 | 4 |
| GDP_per_capita | 2.6577585 | 2.60067976 | 0.279082855 | 5.461517 | 4 |
| PPP_per_capita | 2.7572651 | 2.19837188 | 0.417111768 | 5.000127 | 4 |
| HDI_2018 | 0.7815000 | 0.18631604 | 0.543000000 | 0.938000 | 4 |
| Polity_Score | 7.2500000 | 3.20156212 | 4.000000000 | 10.000000 | 4 |
| FH_Total | 79.0000000 | 20.80064102 | 60.000000000 | 97.000000 | 4 |
このようにグループ化することができる。引き続きMean列からMax列までの値を小数点3桁目で丸めてみよう。MeanとMax列の位置は2、5列目であるかのように見える。とりあえずやってみよう。
| Variable | Mean | SD | Min | Max | Obs |
|---|---|---|---|---|---|
| Africa | |||||
| Population | 24.561 | 35.901 | 0.098 | 206.139589 | 54 |
| Area | 54.444 | 59.218 | 0.046 | 238.174000 | 54 |
| GDP_per_capita | 0.251 | 0.313 | 0.006 | 1.727394 | 54 |
| PPP_per_capita | 0.567 | 0.602 | 0.073 | 2.778814 | 52 |
| HDI_2018 | 0.553 | 0.109 | 0.377 | 0.801000 | 53 |
| Polity_Score | 2.479 | 5.002 | −9.000 | 10.000000 | 48 |
| FH_Total | 41.574 | 25.130 | 2.000 | 92.000000 | 54 |
| America | |||||
| Population | 28.736 | 66.285 | 0.053 | 334.308644 | 36 |
| Area | 108.161 | 245.852 | 0.026 | 915.802000 | 36 |
| GDP_per_capita | 1.253 | 1.270 | 0.075 | 6.444591 | 36 |
| PPP_per_capita | 1.810 | 1.260 | 0.177 | 6.178997 | 35 |
| HDI_2018 | 0.742 | 0.091 | 0.466 | 0.922000 | 36 |
| Polity_Score | 6.926 | 3.594 | −5.000 | 10.000000 | 27 |
| FH_Total | 71.917 | 22.428 | 14.000 | 98.000000 | 36 |
| Asia | |||||
| Population | 107.300 | 301.727 | 0.437 | 1447.470092 | 42 |
| Area | 70.198 | 155.925 | 0.030 | 938.929100 | 42 |
| GDP_per_capita | 1.317 | 1.706 | 0.049 | 6.368026 | 42 |
| PPP_per_capita | 2.273 | 2.407 | 0.140 | 9.525177 | 41 |
| HDI_2018 | 0.723 | 0.120 | 0.463 | 0.935000 | 41 |
| Polity_Score | 0.342 | 7.484 | −10.000 | 10.000000 | 38 |
| FH_Total | 38.929 | 25.155 | 0.000 | 96.000000 | 42 |
| Europe | |||||
| Population | 17.113 | 29.057 | 0.001 | 145.934462 | 50 |
| Area | 46.462 | 230.347 | 0.000 | 1637.687000 | 50 |
| GDP_per_capita | 3.558 | 3.865 | 0.296 | 18.317721 | 49 |
| PPP_per_capita | 3.778 | 2.128 | 0.843 | 11.342306 | 46 |
| HDI_2018 | 0.861 | 0.063 | 0.711 | 0.954000 | 46 |
| Polity_Score | 7.927 | 4.233 | −7.000 | 10.000000 | 41 |
| FH_Total | 79.429 | 22.702 | 10.000 | 100.000000 | 49 |
| Oceania | |||||
| Population | 10.047 | 10.814 | 0.896 | 25.499884 | 4 |
| Area | 210.431 | 372.291 | 1.827 | 768.230000 | 4 |
| GDP_per_capita | 2.658 | 2.601 | 0.279 | 5.461517 | 4 |
| PPP_per_capita | 2.757 | 2.198 | 0.417 | 5.000127 | 4 |
| HDI_2018 | 0.781 | 0.186 | 0.543 | 0.938000 | 4 |
| Polity_Score | 7.250 | 3.202 | 4.000 | 10.000000 | 4 |
| FH_Total | 79.000 | 20.801 | 60.000 | 97.000000 | 4 |
このようにエラーが表示される。なぜだろう。それはグルーピングに使用された変数も1つの列としてカウントされるからだ。つまり、グルーピングに使用されたContinent列は列としては見えないものの、1列目として存在する。したがって、目に見える列番号に1を足す必要がある。それではグルーピングあと、Mean列からMax列までは小数点3桁目で丸め、Min列とMax列はRangeという名でグルーピングしてみよう。
df2 |>
group_by(Continent) |>
gt() |>
tab_spanner(columns = 5:6, label = "Range") |>
fmt_number(columns = 3:6, decimals = 3)| Variable | Mean | SD |
Range
|
Obs | |
|---|---|---|---|---|---|
| Min | Max | ||||
| Africa | |||||
| Population | 24.561 | 35.901 | 0.098 | 206.140 | 54 |
| Area | 54.444 | 59.218 | 0.046 | 238.174 | 54 |
| GDP_per_capita | 0.251 | 0.313 | 0.006 | 1.727 | 54 |
| PPP_per_capita | 0.567 | 0.602 | 0.073 | 2.779 | 52 |
| HDI_2018 | 0.553 | 0.109 | 0.377 | 0.801 | 53 |
| Polity_Score | 2.479 | 5.002 | −9.000 | 10.000 | 48 |
| FH_Total | 41.574 | 25.130 | 2.000 | 92.000 | 54 |
| America | |||||
| Population | 28.736 | 66.285 | 0.053 | 334.309 | 36 |
| Area | 108.161 | 245.852 | 0.026 | 915.802 | 36 |
| GDP_per_capita | 1.253 | 1.270 | 0.075 | 6.445 | 36 |
| PPP_per_capita | 1.810 | 1.260 | 0.177 | 6.179 | 35 |
| HDI_2018 | 0.742 | 0.091 | 0.466 | 0.922 | 36 |
| Polity_Score | 6.926 | 3.594 | −5.000 | 10.000 | 27 |
| FH_Total | 71.917 | 22.428 | 14.000 | 98.000 | 36 |
| Asia | |||||
| Population | 107.300 | 301.727 | 0.437 | 1,447.470 | 42 |
| Area | 70.198 | 155.925 | 0.030 | 938.929 | 42 |
| GDP_per_capita | 1.317 | 1.706 | 0.049 | 6.368 | 42 |
| PPP_per_capita | 2.273 | 2.407 | 0.140 | 9.525 | 41 |
| HDI_2018 | 0.723 | 0.120 | 0.463 | 0.935 | 41 |
| Polity_Score | 0.342 | 7.484 | −10.000 | 10.000 | 38 |
| FH_Total | 38.929 | 25.155 | 0.000 | 96.000 | 42 |
| Europe | |||||
| Population | 17.113 | 29.057 | 0.001 | 145.934 | 50 |
| Area | 46.462 | 230.347 | 0.000 | 1,637.687 | 50 |
| GDP_per_capita | 3.558 | 3.865 | 0.296 | 18.318 | 49 |
| PPP_per_capita | 3.778 | 2.128 | 0.843 | 11.342 | 46 |
| HDI_2018 | 0.861 | 0.063 | 0.711 | 0.954 | 46 |
| Polity_Score | 7.927 | 4.233 | −7.000 | 10.000 | 41 |
| FH_Total | 79.429 | 22.702 | 10.000 | 100.000 | 49 |
| Oceania | |||||
| Population | 10.047 | 10.814 | 0.896 | 25.500 | 4 |
| Area | 210.431 | 372.291 | 1.827 | 768.230 | 4 |
| GDP_per_capita | 2.658 | 2.601 | 0.279 | 5.462 | 4 |
| PPP_per_capita | 2.757 | 2.198 | 0.417 | 5.000 | 4 |
| HDI_2018 | 0.781 | 0.186 | 0.543 | 0.938 | 4 |
| Polity_Score | 7.250 | 3.202 | 4.000 | 10.000 | 4 |
| FH_Total | 79.000 | 20.801 | 60.000 | 97.000 | 4 |
ややこしい話であるが、列を番号でなく、列名で指定すると、このような混乱を避けることができる。列の指定方法は好みの問題でもあるので、好きなやり方を使おう。
df2 |>
group_by(Continent) |>
gt() |>
tab_spanner(columns = Min:Max, label = "Range") |>
fmt_number(columns = Mean:Max, decimals = 3)| Variable | Mean | SD |
Range
|
Obs | |
|---|---|---|---|---|---|
| Min | Max | ||||
| Africa | |||||
| Population | 24.561 | 35.901 | 0.098 | 206.140 | 54 |
| Area | 54.444 | 59.218 | 0.046 | 238.174 | 54 |
| GDP_per_capita | 0.251 | 0.313 | 0.006 | 1.727 | 54 |
| PPP_per_capita | 0.567 | 0.602 | 0.073 | 2.779 | 52 |
| HDI_2018 | 0.553 | 0.109 | 0.377 | 0.801 | 53 |
| Polity_Score | 2.479 | 5.002 | −9.000 | 10.000 | 48 |
| FH_Total | 41.574 | 25.130 | 2.000 | 92.000 | 54 |
| America | |||||
| Population | 28.736 | 66.285 | 0.053 | 334.309 | 36 |
| Area | 108.161 | 245.852 | 0.026 | 915.802 | 36 |
| GDP_per_capita | 1.253 | 1.270 | 0.075 | 6.445 | 36 |
| PPP_per_capita | 1.810 | 1.260 | 0.177 | 6.179 | 35 |
| HDI_2018 | 0.742 | 0.091 | 0.466 | 0.922 | 36 |
| Polity_Score | 6.926 | 3.594 | −5.000 | 10.000 | 27 |
| FH_Total | 71.917 | 22.428 | 14.000 | 98.000 | 36 |
| Asia | |||||
| Population | 107.300 | 301.727 | 0.437 | 1,447.470 | 42 |
| Area | 70.198 | 155.925 | 0.030 | 938.929 | 42 |
| GDP_per_capita | 1.317 | 1.706 | 0.049 | 6.368 | 42 |
| PPP_per_capita | 2.273 | 2.407 | 0.140 | 9.525 | 41 |
| HDI_2018 | 0.723 | 0.120 | 0.463 | 0.935 | 41 |
| Polity_Score | 0.342 | 7.484 | −10.000 | 10.000 | 38 |
| FH_Total | 38.929 | 25.155 | 0.000 | 96.000 | 42 |
| Europe | |||||
| Population | 17.113 | 29.057 | 0.001 | 145.934 | 50 |
| Area | 46.462 | 230.347 | 0.000 | 1,637.687 | 50 |
| GDP_per_capita | 3.558 | 3.865 | 0.296 | 18.318 | 49 |
| PPP_per_capita | 3.778 | 2.128 | 0.843 | 11.342 | 46 |
| HDI_2018 | 0.861 | 0.063 | 0.711 | 0.954 | 46 |
| Polity_Score | 7.927 | 4.233 | −7.000 | 10.000 | 41 |
| FH_Total | 79.429 | 22.702 | 10.000 | 100.000 | 49 |
| Oceania | |||||
| Population | 10.047 | 10.814 | 0.896 | 25.500 | 4 |
| Area | 210.431 | 372.291 | 1.827 | 768.230 | 4 |
| GDP_per_capita | 2.658 | 2.601 | 0.279 | 5.462 | 4 |
| PPP_per_capita | 2.757 | 2.198 | 0.417 | 5.000 | 4 |
| HDI_2018 | 0.781 | 0.186 | 0.543 | 0.938 | 4 |
| Polity_Score | 7.250 | 3.202 | 4.000 | 10.000 | 4 |
| FH_Total | 79.000 | 20.801 | 60.000 | 97.000 | 4 |
最後に、グルーピングとは関係ないものの、行の名前を指定する方法について説明する。それはgt()で表を作成する際、行の名前にしたい列名をrowname_colで指定すれば良い。たとえば、Variable列を行の名前にしてみよう。
df2 |>
group_by(Continent) |>
gt(rowname_col = "Variable") |>
tab_spanner(columns = 5:6, label = "Range") |>
fmt_number(columns = 3:6, decimals = 3)| Mean | SD |
Range
|
Obs | ||
|---|---|---|---|---|---|
| Min | Max | ||||
| Africa | |||||
| Population | 24.561 | 35.901 | 0.098 | 206.140 | 54 |
| Area | 54.444 | 59.218 | 0.046 | 238.174 | 54 |
| GDP_per_capita | 0.251 | 0.313 | 0.006 | 1.727 | 54 |
| PPP_per_capita | 0.567 | 0.602 | 0.073 | 2.779 | 52 |
| HDI_2018 | 0.553 | 0.109 | 0.377 | 0.801 | 53 |
| Polity_Score | 2.479 | 5.002 | −9.000 | 10.000 | 48 |
| FH_Total | 41.574 | 25.130 | 2.000 | 92.000 | 54 |
| America | |||||
| Population | 28.736 | 66.285 | 0.053 | 334.309 | 36 |
| Area | 108.161 | 245.852 | 0.026 | 915.802 | 36 |
| GDP_per_capita | 1.253 | 1.270 | 0.075 | 6.445 | 36 |
| PPP_per_capita | 1.810 | 1.260 | 0.177 | 6.179 | 35 |
| HDI_2018 | 0.742 | 0.091 | 0.466 | 0.922 | 36 |
| Polity_Score | 6.926 | 3.594 | −5.000 | 10.000 | 27 |
| FH_Total | 71.917 | 22.428 | 14.000 | 98.000 | 36 |
| Asia | |||||
| Population | 107.300 | 301.727 | 0.437 | 1,447.470 | 42 |
| Area | 70.198 | 155.925 | 0.030 | 938.929 | 42 |
| GDP_per_capita | 1.317 | 1.706 | 0.049 | 6.368 | 42 |
| PPP_per_capita | 2.273 | 2.407 | 0.140 | 9.525 | 41 |
| HDI_2018 | 0.723 | 0.120 | 0.463 | 0.935 | 41 |
| Polity_Score | 0.342 | 7.484 | −10.000 | 10.000 | 38 |
| FH_Total | 38.929 | 25.155 | 0.000 | 96.000 | 42 |
| Europe | |||||
| Population | 17.113 | 29.057 | 0.001 | 145.934 | 50 |
| Area | 46.462 | 230.347 | 0.000 | 1,637.687 | 50 |
| GDP_per_capita | 3.558 | 3.865 | 0.296 | 18.318 | 49 |
| PPP_per_capita | 3.778 | 2.128 | 0.843 | 11.342 | 46 |
| HDI_2018 | 0.861 | 0.063 | 0.711 | 0.954 | 46 |
| Polity_Score | 7.927 | 4.233 | −7.000 | 10.000 | 41 |
| FH_Total | 79.429 | 22.702 | 10.000 | 100.000 | 49 |
| Oceania | |||||
| Population | 10.047 | 10.814 | 0.896 | 25.500 | 4 |
| Area | 210.431 | 372.291 | 1.827 | 768.230 | 4 |
| GDP_per_capita | 2.658 | 2.601 | 0.279 | 5.462 | 4 |
| PPP_per_capita | 2.757 | 2.198 | 0.417 | 5.000 | 4 |
| HDI_2018 | 0.781 | 0.186 | 0.543 | 0.938 | 4 |
| Polity_Score | 7.250 | 3.202 | 4.000 | 10.000 | 4 |
| FH_Total | 79.000 | 20.801 | 60.000 | 97.000 | 4 |
表としては同じ表であるが、Variable列の右側に垂直線が出力される。ちなみにこれによって、列番号がずれることはないので安心しよう。
23.5 セルの色分け
23.5.1 行・列のハイライト
続いて、セルを色塗りする方法を紹介する。まず、gt()を使用し、df3の表を作成し、Population列からFH列までの値を小数点3桁までにする。作成した表はdf3_tblという名で格納し、出力してみよう。
| Continent | Population | Area | GDP | PPP | HDI | Polity | FH |
|---|---|---|---|---|---|---|---|
| Africa | 24.561 | 54.444 | 0.251 | 0.567 | 0.553 | 2.479 | 41.574 |
| America | 28.736 | 108.161 | 1.253 | 1.810 | 0.742 | 6.926 | 71.917 |
| Asia | 107.300 | 70.198 | 1.317 | 2.273 | 0.723 | 0.342 | 38.929 |
| Europe | 17.113 | 46.462 | 3.558 | 3.778 | 0.861 | 7.927 | 79.429 |
| Oceania | 10.047 | 210.431 | 2.658 | 2.757 | 0.781 | 7.250 | 79.000 |
まずは、特定の行を色塗りする方法を紹介する。使用する関数はdata_color()関数である。rows引数でハイライトしたい行の位置を指定する。たとえば、3行目をハイライトしたい場合はrows = 3とする。
| Continent | Population | Area | GDP | PPP | HDI | Polity | FH |
|---|---|---|---|---|---|---|---|
| Africa | 24.561 | 54.444 | 0.251 | 0.567 | 0.553 | 2.479 | 41.574 |
| America | 28.736 | 108.161 | 1.253 | 1.810 | 0.742 | 6.926 | 71.917 |
| Asia | 107.300 | 70.198 | 1.317 | 2.273 | 0.723 | 0.342 | 38.929 |
| Europe | 17.113 | 46.462 | 3.558 | 3.778 | 0.861 | 7.927 | 79.429 |
| Oceania | 10.047 | 210.431 | 2.658 | 2.757 | 0.781 | 7.250 | 79.000 |
ハイライトの色はpalette引数で指定できる。
| Continent | Population | Area | GDP | PPP | HDI | Polity | FH |
|---|---|---|---|---|---|---|---|
| Africa | 24.561 | 54.444 | 0.251 | 0.567 | 0.553 | 2.479 | 41.574 |
| America | 28.736 | 108.161 | 1.253 | 1.810 | 0.742 | 6.926 | 71.917 |
| Asia | 107.300 | 70.198 | 1.317 | 2.273 | 0.723 | 0.342 | 38.929 |
| Europe | 17.113 | 46.462 | 3.558 | 3.778 | 0.861 | 7.927 | 79.429 |
| Oceania | 10.047 | 210.431 | 2.658 | 2.757 | 0.781 | 7.250 | 79.000 |
また、rows引数は行の番号でなく、条件式を使うこともできる。たとえば、HDI列の値が0.75以上の行をハイライトしたい場合はrows = (HID >= 0.75)のように指定する。()はなくても良いが、可読性が落ちるので入れておこう。複数の行をハイライトする目的でdata_color()を使う場合、palette引数で色を必ず指定する。後ほど紹介するが、実はdata_color()はセルの値に応じて色が変わる。palette引数はその色のバリエーションを指定する関数だが、特定の色("red"とか"#000000"など)を指定するとすべてのセルがその色に固定される。ここでは特定の行をハイライトするだけなので、palette = "色"で色を固定しよう。
| Continent | Population | Area | GDP | PPP | HDI | Polity | FH |
|---|---|---|---|---|---|---|---|
| Africa | 24.561 | 54.444 | 0.251 | 0.567 | 0.553 | 2.479 | 41.574 |
| America | 28.736 | 108.161 | 1.253 | 1.810 | 0.742 | 6.926 | 71.917 |
| Asia | 107.300 | 70.198 | 1.317 | 2.273 | 0.723 | 0.342 | 38.929 |
| Europe | 17.113 | 46.462 | 3.558 | 3.778 | 0.861 | 7.927 | 79.429 |
| Oceania | 10.047 | 210.431 | 2.658 | 2.757 | 0.781 | 7.250 | 79.000 |
続いて列のハイライト方法を紹介する。ここでも同じくdata_color()を使用する。ただし、列を指定する引数がrowsでなく、columnsであることに注意すること。また、columns実引数として条件式は使用できない。以下はdf3_tblのPolity列からFH列までを"#ACB3CC"色にハイライトした例である。
| Continent | Population | Area | GDP | PPP | HDI | Polity | FH |
|---|---|---|---|---|---|---|---|
| Africa | 24.561 | 54.444 | 0.251 | 0.567 | 0.553 | 2.479 | 41.574 |
| America | 28.736 | 108.161 | 1.253 | 1.810 | 0.742 | 6.926 | 71.917 |
| Asia | 107.300 | 70.198 | 1.317 | 2.273 | 0.723 | 0.342 | 38.929 |
| Europe | 17.113 | 46.462 | 3.558 | 3.778 | 0.861 | 7.927 | 79.429 |
| Oceania | 10.047 | 210.431 | 2.658 | 2.757 | 0.781 | 7.250 | 79.000 |
23.5.2 セルの色分け
以上の例は「行」と「列」のハイライトであった。ここでは「セル」に注目する。セルの色塗りには2つのケースがある。1つ目は特定のセルをハイライトすることであり、2つ目は値に応じて色分けをすることである。まず、特定のセルを強調したい場合はdata_color()関数を使用する。ただし、rows引数のみだと全列がハイライトされてしまうので、今回は更にcolumns引数も追加し、「何行目、何列目のセル」かを特定する必要がある。
| Continent | Population | Area | GDP | PPP | HDI | Polity | FH |
|---|---|---|---|---|---|---|---|
| Africa | 24.561 | 54.444 | 0.251 | 0.567 | 0.553 | 2.479 | 41.574 |
| America | 28.736 | 108.161 | 1.253 | 1.810 | 0.742 | 6.926 | 71.917 |
| Asia | 107.300 | 70.198 | 1.317 | 2.273 | 0.723 | 0.342 | 38.929 |
| Europe | 17.113 | 46.462 | 3.558 | 3.778 | 0.861 | 7.927 | 79.429 |
| Oceania | 10.047 | 210.431 | 2.658 | 2.757 | 0.781 | 7.250 | 79.000 |
セルの値に応じて色分けをする場合もdata_color()関数を使う。たとえば、Population列(2列目)の値に応じて色分けをするなら、columns = Population、またはcolumns = 2を指定する。
| Continent | Population | Area | GDP | PPP | HDI | Polity | FH |
|---|---|---|---|---|---|---|---|
| Africa | 24.561 | 54.444 | 0.251 | 0.567 | 0.553 | 2.479 | 41.574 |
| America | 28.736 | 108.161 | 1.253 | 1.810 | 0.742 | 6.926 | 71.917 |
| Asia | 107.300 | 70.198 | 1.317 | 2.273 | 0.723 | 0.342 | 38.929 |
| Europe | 17.113 | 46.462 | 3.558 | 3.778 | 0.861 | 7.927 | 79.429 |
| Oceania | 10.047 | 210.431 | 2.658 | 2.757 | 0.781 | 7.250 | 79.000 |
ちなみに、色についても説明する。デフォルトの色だと値の高低が分かりにくいため、もう少し直感的なパレットにした方が良いだろう。このパレットはpalette引数で指定することができる。特定のパッケージが提供するパレットであれば"パッケージ名::パレット名"と指定する。たとえば、Population列からFH列まで色分けをし、{ggsci}のblue_materialパレットを使う場合はpalette = "ggsci::blue_material"のように指定する必要がある。
| Continent | Population | Area | GDP | PPP | HDI | Polity | FH |
|---|---|---|---|---|---|---|---|
| Africa | 24.561 | 54.444 | 0.251 | 0.567 | 0.553 | 2.479 | 41.574 |
| America | 28.736 | 108.161 | 1.253 | 1.810 | 0.742 | 6.926 | 71.917 |
| Asia | 107.300 | 70.198 | 1.317 | 2.273 | 0.723 | 0.342 | 38.929 |
| Europe | 17.113 | 46.462 | 3.558 | 3.778 | 0.861 | 7.927 | 79.429 |
| Oceania | 10.047 | 210.431 | 2.658 | 2.757 | 0.781 | 7.250 | 79.000 |
このように濃いほど値が大きく、薄いほど小さいことが一目瞭然となる。{ggsci}は他にも様々なパレットを提供しているが、詳細は公式レファレンスを参照されたい。また、{ggsci}以外のパッケージが提供するパレットも使える。定番の{RColorBrewer}パッケージも様々なパレットを提供しており、以下の例はYlOrRdパレットを使った例だ。
| Continent | Population | Area | GDP | PPP | HDI | Polity | FH |
|---|---|---|---|---|---|---|---|
| Africa | 24.561 | 54.444 | 0.251 | 0.567 | 0.553 | 2.479 | 41.574 |
| America | 28.736 | 108.161 | 1.253 | 1.810 | 0.742 | 6.926 | 71.917 |
| Asia | 107.300 | 70.198 | 1.317 | 2.273 | 0.723 | 0.342 | 38.929 |
| Europe | 17.113 | 46.462 | 3.558 | 3.778 | 0.861 | 7.927 | 79.429 |
| Oceania | 10.047 | 210.431 | 2.658 | 2.757 | 0.781 | 7.250 | 79.000 |
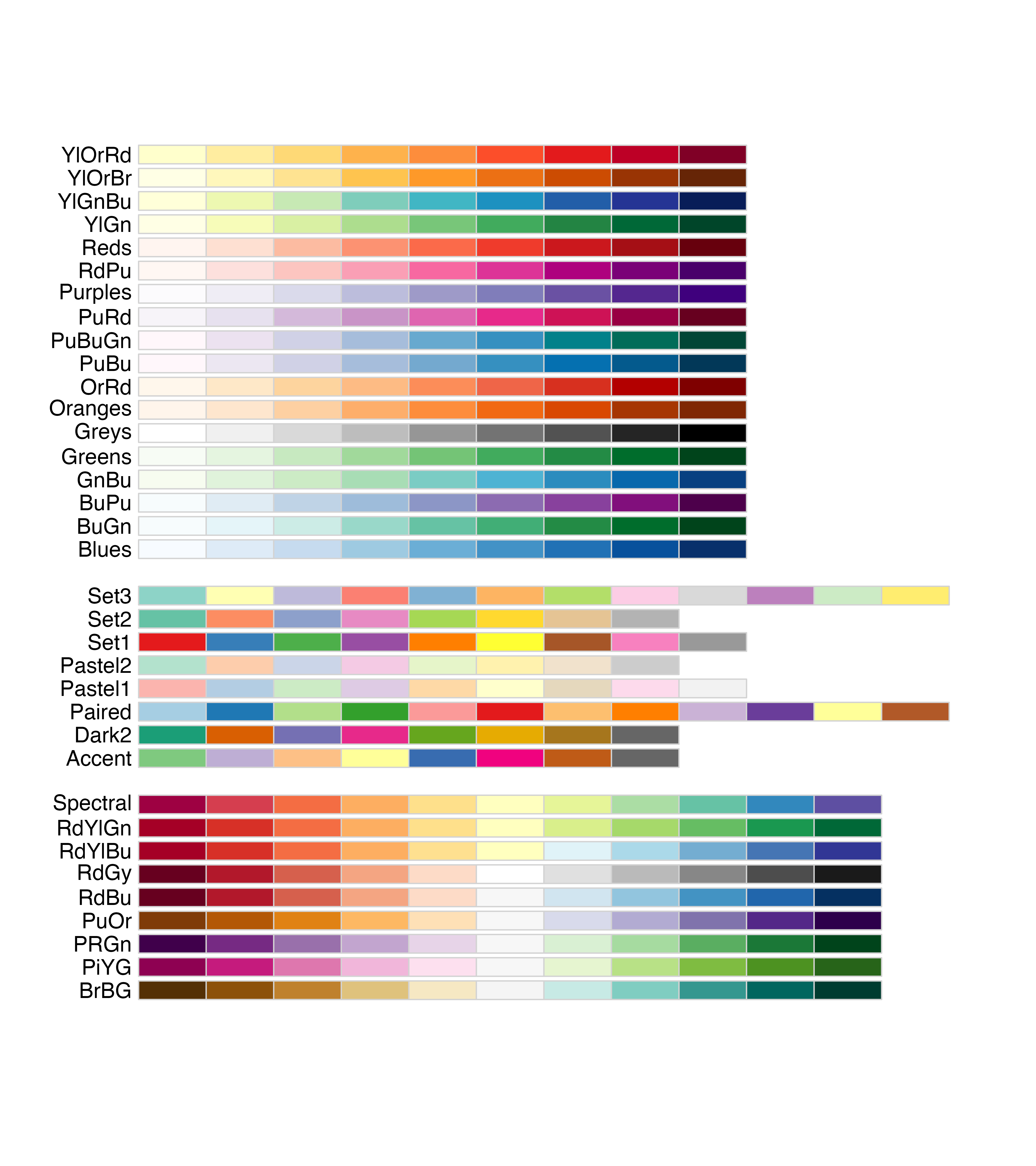
{RColorBrewer}が提供するパレットの例はコンソール上でRColorBrewer::display.brewer.all()と入力すると 図 23.2 のようなパレット一覧が出力される。
23.6 画像・プロットの追加
以下では表の中にプロットや画像を入れる方法について紹介する。まずはdf4を利用し、大陸(Continent)ごとの一人あたり購買力平価GDP(PPP_per_capita)の記述統計と分布を作成する。グループごとの記述統計を作成するため、ここではgroup_by()とsummarise()関数を使用する。平均値、標準偏差、最小値、最大値、国家数をそれぞれMean、SD、Min、Max、N列にする。そして、当該大陸に属する国のPPP_per_capitaを一つのベクトルとし、PPP列に入れる。この場合、list()関数を使えば良い。以上の結果をdf4_groupedに格納する。
出来上がったdf4_groupedは以下の通りだ。
# A tibble: 5 × 7
Continent Mean SD Min Max N PPP
<chr> <dbl> <dbl> <dbl> <dbl> <int> <list>
1 Africa 5667. 6015. 733. 27788. 52 <dbl [52]>
2 America 18100. 12601. 1766. 61790. 35 <dbl [35]>
3 Asia 22728. 24067. 1396. 95252. 41 <dbl [41]>
4 Europe 37783. 21276. 8429. 113423. 46 <dbl [46]>
5 Oceania 27573. 21984. 4171. 50001. 4 <dbl [4]> それではdf4_groupedをgt()で表にしてみよう。
| Continent | Mean | SD | Min | Max | N | PPP |
|---|---|---|---|---|---|---|
| Africa | 5667.087 | 6015.193 | 733.1417 | 27788.14 | 52 | 11324.0725, 6649.1673, 3067.3395, 17310.5769, 1799.9818, 733.1417, 6912.7516, 3506.4386, 923.5042, 1525.4869, 3006.8733, 3191.0497, 1043.4956, 3641.9578, 5071.1943, 11198.2578, 19458.2978, 1860.3065, 8633.5553, 2046.8136, 14380.1640, 2072.3368, 5097.3606, 1901.6047, 4104.9732, 3019.3082, 1461.0965, 14018.7988, 1567.1475, 1016.0831, 2208.4879, 3601.3961, 22636.5579, 7553.9970, 1246.5947, 10314.3368, 824.0225, 5018.4108, 2007.9457, 3890.9194, 3247.9262, 27788.1379, 1634.0012, 12604.8540, 1410.1588, 4062.9183, 2428.0001, 1515.5174, 10773.4423, 1716.0125, 3396.9366, 3264.8320 |
| America | 18100.292 | 12600.623 | 1765.8751 | 61789.97 | 35 | 21267.245, 22938.453, 35662.133, 16065.907, 7090.572, 8623.407, 14734.442, 49087.531, 24261.632, 14474.628, 19395.153, 11755.063, 17774.017, 11478.292, 8727.663, 33836.181, 8332.809, 2416.077, 9447.449, 1765.875, 5624.412, 9886.558, 19962.713, 5693.549, 30816.642, 12877.619, 12703.540, 26152.935, 13828.250, 12686.047, 15858.204, 26727.710, 61789.968, 21961.226, 17806.318 |
| Asia | 22728.133 | 24066.762 | 1396.1051 | 95251.77 | 41 | 2125.363, 43624.136, 4457.529, 11362.544, 60655.643, 4931.585, 4142.204, 15176.568, 6564.248, 11396.947, 13961.476, 10434.202, 41318.464, 41490.573, 9849.485, 25469.454, 39921.960, 50094.732, 5083.211, 7548.949, 16473.367, 27477.879, 18087.834, 11801.134, 3210.718, 27700.112, 4664.227, 8098.786, 93465.650, 47196.131, 95251.768, 13413.583, 46145.206, 3161.765, 18383.526, 3034.142, 65777.677, 6792.995, 7627.625, 1396.105, 3083.957 |
| Europe | 37782.593 | 21276.379 | 8428.7387 | 113423.06 | 46 | 13780.638, 12974.285, 55823.776, 14257.217, 19415.237, 51548.972, 15158.639, 22550.810, 27996.133, 28723.892, 40130.231, 56753.797, 36233.104, 49324.081, 45649.605, 13633.866, 53886.153, 31256.640, 31955.380, 60011.048, 83254.278, 42769.738, 11077.907, 31412.683, 36875.034, 113423.060, 47787.124, 8428.739, 21103.451, 57277.744, 16621.538, 66276.146, 31863.289, 34564.831, 29406.377, 28731.642, 62554.007, 14078.861, 32539.756, 38655.236, 40519.800, 54212.515, 68233.163, 27465.404, 12207.236, 45596.210 |
| Oceania | 27572.651 | 21983.719 | 4171.1177 | 50001.27 | 4 | 50001.271, 13939.907, 42178.309, 4171.118 |
続いて、平均値から最大値までの値を小数点1桁で丸め、列名を修正し、タイトルを付ける。
df4_grouped |>
gt() |>
fmt_number(columns = Mean:Max, decimals = 1) |>
cols_label("Continent" = "大陸",
"Mean" = "平均値",
"SD" = "標準偏差",
"Min" = "最小値",
"Max" = "最大値",
"N" = "国家数",
"PPP" = "分布") |>
tab_header(title = "大陸別一人あたり購買力平価GDP")| 大陸別一人あたり購買力平価GDP | ||||||
|---|---|---|---|---|---|---|
| 大陸 | 平均値 | 標準偏差 | 最小値 | 最大値 | 国家数 | 分布 |
| Africa | 5,667.1 | 6,015.2 | 733.1 | 27,788.1 | 52 | 11324.0725, 6649.1673, 3067.3395, 17310.5769, 1799.9818, 733.1417, 6912.7516, 3506.4386, 923.5042, 1525.4869, 3006.8733, 3191.0497, 1043.4956, 3641.9578, 5071.1943, 11198.2578, 19458.2978, 1860.3065, 8633.5553, 2046.8136, 14380.1640, 2072.3368, 5097.3606, 1901.6047, 4104.9732, 3019.3082, 1461.0965, 14018.7988, 1567.1475, 1016.0831, 2208.4879, 3601.3961, 22636.5579, 7553.9970, 1246.5947, 10314.3368, 824.0225, 5018.4108, 2007.9457, 3890.9194, 3247.9262, 27788.1379, 1634.0012, 12604.8540, 1410.1588, 4062.9183, 2428.0001, 1515.5174, 10773.4423, 1716.0125, 3396.9366, 3264.8320 |
| America | 18,100.3 | 12,600.6 | 1,765.9 | 61,790.0 | 35 | 21267.245, 22938.453, 35662.133, 16065.907, 7090.572, 8623.407, 14734.442, 49087.531, 24261.632, 14474.628, 19395.153, 11755.063, 17774.017, 11478.292, 8727.663, 33836.181, 8332.809, 2416.077, 9447.449, 1765.875, 5624.412, 9886.558, 19962.713, 5693.549, 30816.642, 12877.619, 12703.540, 26152.935, 13828.250, 12686.047, 15858.204, 26727.710, 61789.968, 21961.226, 17806.318 |
| Asia | 22,728.1 | 24,066.8 | 1,396.1 | 95,251.8 | 41 | 2125.363, 43624.136, 4457.529, 11362.544, 60655.643, 4931.585, 4142.204, 15176.568, 6564.248, 11396.947, 13961.476, 10434.202, 41318.464, 41490.573, 9849.485, 25469.454, 39921.960, 50094.732, 5083.211, 7548.949, 16473.367, 27477.879, 18087.834, 11801.134, 3210.718, 27700.112, 4664.227, 8098.786, 93465.650, 47196.131, 95251.768, 13413.583, 46145.206, 3161.765, 18383.526, 3034.142, 65777.677, 6792.995, 7627.625, 1396.105, 3083.957 |
| Europe | 37,782.6 | 21,276.4 | 8,428.7 | 113,423.1 | 46 | 13780.638, 12974.285, 55823.776, 14257.217, 19415.237, 51548.972, 15158.639, 22550.810, 27996.133, 28723.892, 40130.231, 56753.797, 36233.104, 49324.081, 45649.605, 13633.866, 53886.153, 31256.640, 31955.380, 60011.048, 83254.278, 42769.738, 11077.907, 31412.683, 36875.034, 113423.060, 47787.124, 8428.739, 21103.451, 57277.744, 16621.538, 66276.146, 31863.289, 34564.831, 29406.377, 28731.642, 62554.007, 14078.861, 32539.756, 38655.236, 40519.800, 54212.515, 68233.163, 27465.404, 12207.236, 45596.210 |
| Oceania | 27,572.7 | 21,983.7 | 4,171.1 | 50,001.3 | 4 | 50001.271, 13939.907, 42178.309, 4171.118 |
それではこのPPP列をプロットにしてみよう。ここで使うのが{gtExtras}のgt_plt_dist()だ。引数はプロットにする列名で十分だ。
df4_grouped |>
gt() |>
fmt_number(columns = Mean:Max, decimals = 1) |>
cols_label("Continent" = "大陸",
"Mean" = "平均値",
"SD" = "標準偏差",
"Min" = "最小値",
"Max" = "最大値",
"N" = "国家数",
"PPP" = "分布") |>
tab_header(title = "大陸別一人あたり購買力平価GDP") |>
gt_plt_dist(PPP)| 大陸別一人あたり購買力平価GDP | ||||||
|---|---|---|---|---|---|---|
| 大陸 | 平均値 | 標準偏差 | 最小値 | 最大値 | 国家数 | 分布 |
| Africa | 5,667.1 | 6,015.2 | 733.1 | 27,788.1 | 52 | |
| America | 18,100.3 | 12,600.6 | 1,765.9 | 61,790.0 | 35 | |
| Asia | 22,728.1 | 24,066.8 | 1,396.1 | 95,251.8 | 41 | |
| Europe | 37,782.6 | 21,276.4 | 8,428.7 | 113,423.1 | 46 | |
| Oceania | 27,572.7 | 21,983.7 | 4,171.1 | 50,001.3 | 4 | |
このように密度曲線が生成される。もし、密度曲線ではなく、ヒストグラムにしたい場合はtype引数を追加し、"histogram"を指定すれば良い。
df4_grouped |>
gt() |>
fmt_number(columns = Mean:Max, decimals = 1) |>
cols_label("Continent" = "大陸",
"Mean" = "平均値",
"SD" = "標準偏差",
"Min" = "最小値",
"Max" = "最大値",
"N" = "国家数",
"PPP" = "分布") |>
tab_header(title = "大陸別一人あたり購買力平価GDP") |>
gt_plt_dist(PPP, type = "histogram")| 大陸別一人あたり購買力平価GDP | ||||||
|---|---|---|---|---|---|---|
| 大陸 | 平均値 | 標準偏差 | 最小値 | 最大値 | 国家数 | 分布 |
| Africa | 5,667.1 | 6,015.2 | 733.1 | 27,788.1 | 52 | |
| America | 18,100.3 | 12,600.6 | 1,765.9 | 61,790.0 | 35 | |
| Asia | 22,728.1 | 24,066.8 | 1,396.1 | 95,251.8 | 41 | |
| Europe | 37,782.6 | 21,276.4 | 8,428.7 | 113,423.1 | 46 | |
| Oceania | 27,572.7 | 21,983.7 | 4,171.1 | 50,001.3 | 4 | |
続いて、画像について解説する。ここではdf5を使用する。まずはgt()で中身を確認してみよう。
| Name | Hex | Download |
|---|---|---|
| dplyr | https://github.com/rstudio/hex-stickers/blob/main/thumbs/dplyr.png?raw=true | 35720 |
| quarto | https://github.com/rstudio/hex-stickers/blob/main/thumbs/quarto.png?raw=true | 171 |
| ggplot2 | https://github.com/rstudio/hex-stickers/blob/main/thumbs/ggplot2.png?raw=true | 44403 |
| shiny | https://github.com/rstudio/hex-stickers/blob/main/thumbs/shiny.png?raw=true | 10795 |
| rmarkdown | https://github.com/rstudio/hex-stickers/blob/main/thumbs/rmarkdown.png?raw=true | 23038 |
| tidyverse | https://github.com/rstudio/hex-stickers/blob/main/thumbs/tidyverse.png?raw=true | 39094 |
3つの列があり、1列目はパッケージ名(Name)、2列目はHEXロゴのURL(Hex)、3列目は2023年5月9日現在のダウンロード数(Download)である。ここで{gtExtras}のgt_img_rows()関数を使用し、画像のパス・URLが格納されている列名を指定すれば、当該画像が表示される。
| Name | Hex | Download |
|---|---|---|
| dplyr |  |
35720 |
| quarto |  |
171 |
| ggplot2 |  |
44403 |
| shiny |  |
10795 |
| rmarkdown |  |
23038 |
| tidyverse |  |
39094 |
画像の大きさはheightで調整できる。今回は50ピクセル(50px)にしてみよう。
| Name | Hex | Download |
|---|---|---|
| dplyr | |
35720 |
| quarto | |
171 |
| ggplot2 | |
44403 |
| shiny | |
10795 |
| rmarkdown | |
23038 |
| tidyverse | |
39094 |
続いて、列名を変更する。NameはPackageに、HexはLogoとする。
| Package | Logo | Download |
|---|---|---|
| dplyr | |
35720 |
| quarto | |
171 |
| ggplot2 | |
44403 |
| shiny | |
10795 |
| rmarkdown | |
23038 |
| tidyverse | |
39094 |
ここで更にDownload列を棒グラフに変えてみよう。棒グラフの作成はgt_plt_bar()を使用する。第1引数は棒グラフにしたい列名だ。
df5 |>
gt() |>
gt_img_rows(Hex, height = 50) |>
cols_label("Name" = "Package",
"Hex" = "Logo") |>
gt_plt_bar(Download)| Package | Logo | Download |
|---|---|---|
| dplyr | |
|
| quarto | |
|
| ggplot2 | |
|
| shiny | |
|
| rmarkdown | |
|
| tidyverse | |
棒グラフにすることで相対的な比較がしやすくなった。しかし、元々あった数字がなくなったので、具体的に何回ダウンロードされたかに関する情報を消えている。もし、元の列を残したい場合はkeep_column = TRUEを指定する。
df5 |>
gt() |>
gt_img_rows(Hex, height = 50) |>
cols_label("Name" = "Package",
"Hex" = "Logo") |>
gt_plt_bar(Download, keep_column = TRUE)| Package | Logo | Download | Download |
|---|---|---|---|
| dplyr | |
35720 | |
| quarto | |
171 | |
| ggplot2 | |
44403 | |
| shiny | |
10795 | |
| rmarkdown | |
23038 | |
| tidyverse | |
39094 |
最後にタイトルを付け、棒グラフの色を"royalblue"にしてみよう。棒の色はcolor引数で指定できる。また、df5をgt()に渡す前にarrange()を使って、パッケージの表示順番もダウンロード数の多いものからに並べ替えてみよう。
df5 |>
arrange(desc(Download)) |>
gt() |>
gt_img_rows(Hex, height = 50) |>
cols_label("Name" = "Package",
"Hex" = "Logo") |>
gt_plt_bar(Download, keep_column = TRUE, color = "royalblue") |>
tab_header(title = "Number of packages downloaded on May 9, 2023")| Number of packages downloaded on May 9, 2023 | |||
|---|---|---|---|
| Package | Logo | Download | Download |
| ggplot2 | |
44403 | |
| tidyverse | |
39094 | |
| dplyr | |
35720 | |
| rmarkdown | |
23038 | |
| shiny | |
10795 | |
| quarto | |
171 | |
{gtExtras}は他にも様々なプロットを提供し、画像の追加にもいくつかのバリエーションがある。詳細は{gtExtras}の公式マニュアルを参照されたい。
23.7 テーマ
{gtExtras}パッケージは8種類のテーマを提供する(バージョン0.5.0現在)。テーマはgt_theme_*()関数によって指定することができる。たとえば、以下のdf1_tblにそれぞれのテーマを適用してみよう。
df1_tbl <- df1 |>
gt() |>
tab_spanner(columns = 4:5, label = "Range") |>
fmt_number(columns = 2:5, decimals = 3) |>
tab_style(style = cell_text(align = "center"),
locations = cells_column_labels())
df1_tbl| Variable | Mean | SD |
Range
|
Obs | |
|---|---|---|---|---|---|
| Min | Max | ||||
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
使い方は簡単で、{gt}で作成した表オブジェクトをgt_theme_*()関数に渡すだけだ。以下は{gtExtras}が提供する8種類のテーマをdf1_tblに適用した例である。
| Variable | Mean | SD |
Range
|
Obs | |
|---|---|---|---|---|---|
| Min | Max | ||||
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
| Variable | Mean | SD |
Range
|
Obs | |
|---|---|---|---|---|---|
| Min | Max | ||||
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
| Variable | Mean | SD |
Range
|
Obs | |
|---|---|---|---|---|---|
| Min | Max | ||||
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
| Variable | Mean | SD |
Range
|
Obs | |
|---|---|---|---|---|---|
| Min | Max | ||||
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
| Variable | Mean | SD |
Range
|
Obs | |
|---|---|---|---|---|---|
| Min | Max | ||||
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
| Variable | Mean | SD |
Range
|
Obs | |
|---|---|---|---|---|---|
| Min | Max | ||||
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
| Variable | Mean | SD |
Range
|
Obs | |
|---|---|---|---|---|---|
| Min | Max | ||||
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
| Variable | Mean | SD |
Range
|
Obs | |
|---|---|---|---|---|---|
| Min | Max | ||||
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
23.8 表の書き出し
{gt}で作成した表は様々なフォーマットで出力することができる。現在(2025年01月15日; {gt} 0.11.1)、Microsoft Word(.docx)、 \(\LaTeX\) (.tex)、ハイパーテキスト(.html)、リッチテキスト(.rtf)、画像(.png)形式で出力可能だ。ここでは簡単な例を紹介する。
まず、{gt}を使って表を作成し、オブジェクトとして作業環境内に格納する。ここではgt_tableと名付けた。
gt_table <- df1 |>
gt() |>
fmt_number(columns = 2:5, decimals = 3) |>
tab_header(title = "タイトル", subtitle = "サブタイトル") |>
tab_footnote(footnote = "注1: ここにはフットノート1が入る") |>
tab_footnote(footnote = "注2: ここにはフットノート2が入る") |>
tab_source_note(source_note = md("出典: 『[私たちのR](https://www.jaysong.net/RBook/)』"))
gt_table| タイトル | |||||
| サブタイトル | |||||
| Variable | Mean | SD | Min | Max | Obs |
|---|---|---|---|---|---|
| Population | 41.738 | 151.270 | 0.001 | 1,447.470 | 186 |
| Area | 69.607 | 187.241 | 0.000 | 1,637.687 | 186 |
| GDP_per_capita | 1.616 | 2.571 | 0.006 | 18.318 | 185 |
| PPP_per_capita | 2.083 | 2.099 | 0.073 | 11.342 | 178 |
| HDI_2018 | 0.713 | 0.153 | 0.377 | 0.954 | 180 |
| Polity_Score | 4.259 | 6.102 | −10.000 | 10.000 | 158 |
| FH_Total | 57.714 | 29.866 | 0.000 | 100.000 | 185 |
| 出典: 『私たちのR』 | |||||
| 注1: ここにはフットノート1が入る | |||||
| 注2: ここにはフットノート2が入る | |||||
このgt_tableを保存する関数はgtsave()である。第1引数は先ほど作成した表のオブジェクト名、第2引数は出力するファイル名である。このファイル名の拡張子によって保存されるファイルのフォーマットが変わる。結果をここで見せることは難しいが、難しい作業ではないので各自やってみよう。
たとえば、.tex形式で書き出したファイルを開いてみると、以下のような \(\LaTeX\) コードが書かれていることが確認できる。
\setlength{\LTpost}{0mm}
\begin{longtable}{lrrrrr}
\caption*{
{\large タイトル} \\
{\small サブタイトル}
} \\
\toprule
Variable & Mean & SD & Min & Max & Obs \\
\midrule
Population & $41.738$ & $151.270$ & $0.001$ & $1,447.470$ & 186 \\
Area & $69.607$ & $187.241$ & $0.000$ & $1,637.687$ & 186 \\
GDP\_per\_capita & $1.616$ & $2.571$ & $0.006$ & $18.318$ & 185 \\
PPP\_per\_capita & $2.083$ & $2.099$ & $0.073$ & $11.342$ & 178 \\
HDI\_2018 & $0.713$ & $0.153$ & $0.377$ & $0.954$ & 180 \\
Polity\_Score & $4.259$ & $6.102$ & $-10.000$ & $10.000$ & 158 \\
FH\_Total & $57.714$ & $29.866$ & $0.000$ & $100.000$ & 185 \\
\bottomrule
\end{longtable}
\begin{minipage}{\linewidth}
\textsuperscript{\textit{NA}}注1: ここにはフットノート1が入る\\
\textsuperscript{\textit{NA}}注2: ここにはフットノート2が入る\\
出典: 『\href{https://www.jaysong.net/RBook/}{私たちのR}』\\
\end{minipage}23.9 データの出力
PDF、Microsoft Word形式の文書を作成する場合、生データ(raw data)を掲載することはめったにないだろう。数十行のデータなら掲載することもあろうが3、規模の大きいデータセットの場合、資源(紙)の無駄遣いとなる。しかし、HTMLフォーマットの文書なら話は別だ。ファイルの容量は大きくなるものの、生データを全て掲載することもできる。
そこまで大きいデータセットではないが、たとえばdf2をR Markdown / QuartoのHTML文書に掲載するとしよう。この場合、まず考えられるのは普通にdf2を出力することだ。ただし、df2のクラスによって出力結果がややことなる。たとえば、df2はread_csv()関数で読み込んだデータであるため、data.frameでなく、tibbleである。実際にクラスを確認してみよう。「クラス(class)」の概念については第30章を参照されたい。
data.frameクラスを継承しているが、クラスに"tbl"や"tbl_df"も含まれており、これはdf2がtibble形式であることを意味する。これをこのまま出力してみよう。
# A tibble: 35 × 7
Continent Variable Mean SD Min Max Obs
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Africa Population 24.6 35.9 0.0983 206. 54
2 Africa Area 54.4 59.2 0.046 238. 54
3 Africa GDP_per_capita 0.251 0.313 0.00577 1.73 54
4 Africa PPP_per_capita 0.567 0.602 0.0733 2.78 52
5 Africa HDI_2018 0.553 0.109 0.377 0.801 53
6 Africa Polity_Score 2.48 5.00 -9 10 48
7 Africa FH_Total 41.6 25.1 2 92 54
8 America Population 28.7 66.3 0.0532 334. 36
9 America Area 108. 246. 0.026 916. 36
10 America GDP_per_capita 1.25 1.27 0.0745 6.44 36
# ℹ 25 more rowstibble形式のデータは通常、最初の10行のみ出力される。また、小数点も2〜3桁目で丸められる。もう一つの特徴としては横に長い表の場合(つまり、列が多い場合)、一部の列は省略される(省略された列の簡単な情報は表示される)。このようにtibbleクラスのデータは読みやすく出力される長所があるものの、全てのデータが出力されないケースもある。
一方、read_csv()でなく、read.csv()で読み込んだ表形式データのクラスはdata.frameだ。df2をas.data.frame()関数を使ってdata.frameクラスに変更してみよう。クラスを変更したdf2はdf6_dfと名付ける。
それではdf6_dfを出力してみよう。
Continent Variable Mean SD Min Max Obs
1 Africa Population 24.5609472 35.90062114 0.098347000 206.139589 54
2 Africa Area 54.4435111 59.21810613 0.046000000 238.174000 54
3 Africa GDP_per_capita 0.2514072 0.31334566 0.005770007 1.727394 54
4 Africa PPP_per_capita 0.5667087 0.60151933 0.073314173 2.778814 52
5 Africa HDI_2018 0.5532642 0.10889924 0.377000000 0.801000 53
6 Africa Polity_Score 2.4791667 5.00208290 -9.000000000 10.000000 48
7 Africa FH_Total 41.5740741 25.12955251 2.000000000 92.000000 54
8 America Population 28.7362271 66.28460983 0.053199000 334.308644 36
9 America Area 108.1607833 245.85173673 0.026000000 915.802000 36
10 America GDP_per_capita 1.2526519 1.27016543 0.074535927 6.444591 36
11 America PPP_per_capita 1.8100292 1.26006234 0.176587508 6.178997 35
12 America HDI_2018 0.7424722 0.09094975 0.466000000 0.922000 36
13 America Polity_Score 6.9259259 3.59407553 -5.000000000 10.000000 27
14 America FH_Total 71.9166667 22.42750225 14.000000000 98.000000 36
15 Asia Population 107.3001606 301.72686527 0.437479000 1447.470092 42
16 Asia Area 70.1983405 155.92487158 0.030000000 938.929100 42
17 Asia GDP_per_capita 1.3167525 1.70584531 0.049067972 6.368026 42
18 Asia PPP_per_capita 2.2728133 2.40667620 0.139610508 9.525177 41
19 Asia HDI_2018 0.7228537 0.12010715 0.463000000 0.935000 41
20 Asia Polity_Score 0.3421053 7.48431266 -10.000000000 10.000000 38
21 Asia FH_Total 38.9285714 25.15453977 0.000000000 96.000000 42
22 Europe Population 17.1127533 29.05674254 0.000801000 145.934462 50
23 Europe Area 46.4618980 230.34717622 0.000000000 1637.687000 50
24 Europe GDP_per_capita 3.5575266 3.86463361 0.296369600 18.317721 49
25 Europe PPP_per_capita 3.7782593 2.12763785 0.842873869 11.342306 46
26 Europe HDI_2018 0.8611304 0.06306914 0.711000000 0.954000 46
27 Europe Polity_Score 7.9268293 4.23314448 -7.000000000 10.000000 41
28 Europe FH_Total 79.4285714 22.70187217 10.000000000 100.000000 49
29 Oceania Population 10.0465332 10.81385119 0.896445000 25.499884 4
30 Oceania Area 210.4312500 372.29122053 1.827000000 768.230000 4
31 Oceania GDP_per_capita 2.6577585 2.60067976 0.279082855 5.461517 4
32 Oceania PPP_per_capita 2.7572651 2.19837188 0.417111768 5.000127 4
33 Oceania HDI_2018 0.7815000 0.18631604 0.543000000 0.938000 4
34 Oceania Polity_Score 7.2500000 3.20156212 4.000000000 10.000000 4
35 Oceania FH_Total 79.0000000 20.80064102 60.000000000 97.000000 4今回は全ての行と列が出力された。そもそも生データを掲載するのが目的であれば、tibbleクラスよりも、data.frameクラスが目的に合致する。しかし、読みにくいという深刻な問題がある。また、世論調査データのように数千行、変数も数十列以上あるデータセットを出力するとあまりにも長い画面になってしまう。
ここで便利なのが{DT}パッケージのdatatable()関数だ。全ての行と列を読みやすい形式で出力してくれる。
このように情報が損失されることなく、非常に読みやすい表になった。これで十分かも知れないが、小数点を丸めたい人もいるかも知れないので、その方法を紹介する。具体的にはdataframe()で作成した表をformatRound()関数に渡すだけだ。formatRound()関数の引数はcolumnsとdigitsがあり、それぞれ適用する列と小数点を桁数を指定すればよい。
しかし、情報の損失がないということは、生データ内の全ての値がHTMLファイルに埋め込まれることを意味する。CSVフォーマットの生データの大きさが10MBなら生成されるHTMLファイルのサイズは必然的に10MBよりも大きくなる。大きい表は別途のファイルとして提供する方が良いだろう。
kable()+ {kableExtra}の使い方については、インターネット上のヴィネットを参考されたい。↩︎どうでも良い話だが、Arend LijphartのPattern of Democracyの場合(邦訳:『民主主義対民主主義』)、データセットがMicrosoft Word形式で公開されている…。↩︎