32 スクレイピング
本章の内容は今後、大きく変更される予定です。スクレイピング先の仕様や構造が頻繁に変更され、またサーバーへの負担をなるべく軽減するために、今後、実習用のページを別途提供する予定です。
まず、本章で使用するパッケージを読み込んでおく。
32.1 HTML
我々が普段見るウェブページは主にHTML(HyperText Markup Language)という言語で記述されている。裏ではPhp、Ruby、Pythonなどが動いているかも知れないが、少なくとも我々がウェブブラウザー(Firefox、Chrome、Safari、Edge等)越しで見る内容はHTML(+CSS、JavaScript、WebAssembly等)で記述されたものだ。(ウェブ)スクレイピングはこのHTMLで記述された表示内容(の一部)を構造化されたデータとして読み込むことである。
したがって、スクレイピングをするためにはHTMLの基本的な知識が必要だ。一つの画面に表示された内容の中で我々が欲しいものは、全体内容の一部だ。これはスクレイピングを行う際、全体内容の中から取得する箇所を指定する必要があることを意味する。そこで重要なのがタグ(tag)と属性(attribute)、セレクター(selector)だ。
32.1.1 タグ
タグは<タグ名>と</タグ名>で構成され1、この間に挟まれた内容は予め決まった書式となる。例えば、<em>R Not for Everyone</em>は「R Not for Everyone」という文字列に対して<em>タグを適用するコードである。<em>タグは予めHTMLで用意されているものであり、文字列をイタリック(例:R Not for Everyone)にするものだ。また、<strong>タグは太字を意味し、<strong>R Not for Everyone</strong>は「R Not for Everyone」と出力される。また、段落を意味する<p>タグも頻繁に使われる。HTMLには様々なタグが用意されており、詳細なリストはW3Cなどを参照されたい(リンク先はHTML5基準)。
タグの中にタグを入れることもできる。以下のコードを見てみよう。
HTMLコード
ブラウザー上の出力内容
- 項目1
- 項目1A
- 項目1B
- 項目1C
- 項目2
- 項目3
<ol>は順序付きリスト(箇条書き)を意味し、一つ一つの項目は<li>タグで指定する。以上の例は<ol>タグの中に<li>タグが入っている入れ子構造だ。また、順序なしリストのタグ<ul>は最初の<li>の中に入っている。たとえば、「項目1B」は<ol> > <li> > <ul> > <li>で定義された内容である。
32.1.2 属性
タグの中には属性といものが定義されている場合がある。タグをプログラミング言語における関数とすれば、属性は引数(argumentとparameter)に該当する。たとえば、画像を貼り付けるタグは<img>だ。ちなみに<img>はタグを閉じる必要がなく、単体のみ存在するため<img>〜</img>でなく、<img>のみか<img/>と記述する。本書では単体で使うタグを区分するために<img/>と表記する。この<img/>タグだけではどの画像を表示するかが分からない。画像の具体的なパスやURLを指定する必要がある。<img/>タグにはsrcという属性があり、src="パス or URL"と書く。たとえば、https://www.jaysong.net/RBook/Figs/favicon.pngというURLの画像を表示させるためには<img src="https://www.jaysong.net/RBook/Figs/favicon.png"/>と記述する必要がある。
{kind=link}
一つのタグは複数の属性を持つこともできる。<img/>タグの場合、画像の幅と高さをwidthとheight属性で指定することができ、altで代替テキストを指定することもできる。ちなみに属性が不要なタグもあるが、属性を持つことができないタグは存在しない。すべてのタグはclassやhidden、styleなどの属性を持つことができ、このようにすべてのタグで使える属性はグローバル属性(global attributes)と呼ばれる。
32.1.3 セレクター
セレクターを理解するためにはCSS(Cascading Style Sheets)の知識が必要であるが、ここでは最低限のことのみ解説する。ウェブスクレイピングは指定したHTMLファイルから特定のタグに囲まれた内容を取得するのが一般的、かつ基本的なやり方だ。たとえば、あるページ上の表を取得するためには表のタグである<table>タグで囲まれた内容を取得する。しかし、一つのページ内に複数の<table>タグがあればどうだろうか。多くのスクレイピングのパッケージやライブラリはすべてを読み込むが、それはメモリの無駄遣いだ。予め具体的にどの表を取得するかを指定した方が効率的だろう。ここで必要なのがセレクターだ。
そもそもセレクターが何なのかを知るためには、CSSの話を簡単にしておく必要がある。CSSはHTMLの「見た目」を担当するものであり、通常、HTMLとは別途のファイル(.cssファイル)で作成され、HTMLに読み込まれる。.cssファイルの内部には「この箇所はこのような見た目にしてくれ」といったものが細かく書かれている。
まずは以下の簡単なHTMLページ(sample00.html)を確認してみよう。
変哲もないページであるが、このページのソースコードは以下の通りである。例えば、<title>タグで囲まれているテキストはそのページのタイトルとなり、<h1>は見出しとなる。いくつかのタグにはidやclassといった属性もついている。たとえば、7行目の<a>タグにはhref、id、classの3つの属性がある。
https://www.jaysong.net/RBook/Data/scraping/sample00.html
<html>
<head>
<meta charset="utf-8">
<title>HTMLの例</title>
</head>
<body>
<h1>第1章:文章</h1>
<p>『<a href="https://www.jaysong.net/RBook/" id="rbook" class="book-title">私たちのR</a>』は<a href="https://www.jaysong.net/">宋財泫</a>(SONG Jaehyun)と<a href="https://yukiyanai.github.io/">矢内勇生</a>が共同で執筆するRプログラミングの「入門書」である。統計学の本ではない。</p>
<p>また、本書はデータ分析の手法の解説書でもない。Rを用いたデータ分析については他の本を参照されたい。私たちが専門とする政治学におけるデータ分析については、以下の本を勧める。</p>
<h1>第2章:箇条書き</h1>
<ul>
<li>浅野正彦・矢内勇生. 2018. 『<span class="book-title">Rによる計量政治学</span>』オーム社.</li>
<li>飯田健. 2013.『<span class="book-title">計量政治分析</span>』共立出版.</li>
</ul>
<ol>
<li>聞いて...</li>
<li>感じて...</li>
<li>考えて...</li>
</ol>
<h1>第3章:表</h1>
<h2>数学成績</h2>
<table class="score" id="math">
<thead>
<tr>
<td>ID</td>
<td>名前</td>
<td>成績</td>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>田中</td>
<td class="tbl-score">80</td>
</tr>
<tr>
<td>2</td>
<td>佐藤</td>
<td class="tbl-score">100</td>
</tr>
<tr>
<td>3</td>
<td>渡辺</td>
<td class="tbl-score">75</td>
</tr>
</tbody>
</table>
<h2>英語成績</h2>
<table class="score" id="english">
<thead>
<tr>
<td>ID</td>
<td>名前</td>
<td>成績</td>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>田中</td>
<td class="tbl-score">20</td>
</tr>
<tr>
<td>2</td>
<td>佐藤</td>
<td class="tbl-score">100</td>
</tr>
<tr>
<td>3</td>
<td>渡辺</td>
<td class="tbl-score">90</td>
</tr>
</tbody>
</table>
</body>
</html> 続いて、もう一つのページ(sample01.html)も見てみよう。
内容的には同じものであるが、見た目がだいぶ異なることが分かるだろう。ソースコードを見ると、一行を除き、sample00.htmlとsample01.htmlのコードは一致していることが分かる。具体的には4行目に<link/>タグが追加されているだけだ。この4行目のコードはstyle01.cssファイルを読み込み、本ファイル(sample01.html)へ適用するということを意味する。他の内容はsample00.htmlと全く同じだ。つまり、この2つのファイルの見た目が異なるのはstyle01.cssの存在が原因であると推測できる。
https://www.jaysong.net/RBook/Data/scraping/sample01.html
<html>
<head>
<meta charset="utf-8">
<link href="sample01.css" rel="stylesheet" type="text/css" media="all"/>
<title>HTMLの例</title>
</head>
<body>
<h1>第1章:文章</h1>
<p>『<a href="https://www.jaysong.net/RBook/" id="rbook" class="book-title">私たちのR</a>』は<a href="https://www.jaysong.net/">宋財泫</a>(SONG Jaehyun)と<a href="https://yukiyanai.github.io/">矢内勇生</a>が共同で執筆するRプログラミングの「入門書」である。統計学の本ではない。</p>
<p>また、本書はデータ分析の手法の解説書でもない。Rを用いたデータ分析については他の本を参照されたい。私たちが専門とする政治学におけるデータ分析については、以下の本を勧める。</p>
<h1>第2章:箇条書き</h1>
<ul>
<li>浅野正彦・矢内勇生. 2018. 『<span class="book-title">Rによる計量政治学</span>』オーム社.</li>
<li>飯田健. 2013.『<span class="book-title">計量政治分析</span>』共立出版.</li>
</ul>
<ol>
<li>聞いて...</li>
<li>感じて...</li>
<li>考えて...</li>
</ol>
<h1>第3章:表</h1>
<h2>数学成績</h2>
<table class="score" id="math">
<thead>
<tr>
<td>ID</td>
<td>名前</td>
<td>成績</td>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>田中</td>
<td class="tbl-score">80</td>
</tr>
<tr>
<td>2</td>
<td>佐藤</td>
<td class="tbl-score">100</td>
</tr>
<tr>
<td>3</td>
<td>渡辺</td>
<td class="tbl-score">75</td>
</tr>
</tbody>
</table>
<h2>英語成績</h2>
<table class="score" id="english">
<thead>
<tr>
<td>ID</td>
<td>名前</td>
<td>成績</td>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>田中</td>
<td class="tbl-score">20</td>
</tr>
<tr>
<td>2</td>
<td>佐藤</td>
<td class="tbl-score">100</td>
</tr>
<tr>
<td>3</td>
<td>渡辺</td>
<td class="tbl-score">90</td>
</tr>
</tbody>
</table>
</body>
</html>https://www.jaysong.net/RBook/Data/scraping/sample01.css
h1, h2, h3 {
font-family: sans-serif;
}
a {
text-decoration: none;
color: royalblue;
}
table {
border-collapse: collapse;
border: 1px solid;
}
td {
border-collapse: collapse;
border: 1px solid;
}
thead {
text-align: center;
font-weight: 600;
}
#rbook {
color: red;
}
.book-title {
font-weight: 600;
}
.score {
width: 300px;
}
.tbl-score {
text-align: right;
} 一つずつ確認していこう。まず、「第1章:文章」や「英語成績」のような見出しが明朝体(serif)からゴジック体(sans-serif)に変わったことが分かる。続いてsample01.cssの1〜3行目を確認してみよう。
このCSSの意味は<h1>、<h2>、<h3>タグに囲まれた内容に対し、{}内の設定を適用するといういみで、今回はフォント族(font-family)をゴジック(sans-serif)にした。また、リンクの下線が無くなり、文字の色もロイヤルブルーになったが、これもsample01.cssの4〜7行目で適宜されたものである。このようにタグ名 {}で特定のタグに対し、スタイルを適用することができ、ここでのタグ名はタグに対するセレクターである。このようなタグ名のセレクターは要素型セレクター(type selector)と呼ばれる。
引き続き、sample01.htmlを見ると『私たちのR』が太字、かつ赤色になっていることが分かる。また、コードの8行目を見ると『私たちのR』の部分が<a>タグで囲まれ、 リンク先を意味するhref属性以外にも、idとclassにそれぞれ"rbook"と"book-title"の値が指定されていることが分かる。そして、sample01.cssの20〜25行目にidがrbookの場合とclassがbook-titleの場合のスタイルが定義されている。たとえば、idは#ID名がセレクターであり(今回は#rbook)、赤色が定義されている。クラスは.クラス名がセレクターであり(今回は.book-title)、文字の太さ(weight)が600になっていることが分かる。ちなみに一つのタグに対して複数のクラスを与えることもできる。この場合、タグ内にclass="クラス名1 クラス名2 クラス名3"のように半角スペースでクラス名を区切れば良い。
このようにIDセレクターとクラスセレクターが用意されているが、特定のタグに識別可能な名前を付ける点で、2つの役割は非常に似ている。しかし、IDとクラスには決定的な違いがある。それはIDは一つのページ内において1回しか登場できないものの、クラスはこのような制限がないことだ。何回も登場するスタイルであればクラスを使用し、固有の識別子が必要な場合はIDを使う。それでも「クラスを1回だけ使っても良いのでは?」と思う読者もいるだろう。たしかにその通りである。しかし、IDとクラスのもう一つの違いはスタイルが衝突する場合、IDセレクターがクラスセレクターに優先する点にある。たとえば、あるタグが#AIDと.Bクラスを両方持ち、.css内部においてそれぞれ文字の太さが600、300に定義されていると、#Aに指定された太さ600が適用される。スクレイピングにおいてIDとクラスの違いは重要ではないが、念のために述べておく。
以上で紹介したもの以外にも、セレクターは多数用意されている。たとえば、文章全体にスタイルを適用したい場合のセレクターは*であり、全称セレクター(universal selector)と呼ばれる。また、特定の属性を持つタグに対してスタイルを適用できる。たとえば、<img>タグすべてでなく、alt属性を持つ<img>タグのみにスタイルを適用する場合のセレクターはimg[alt]のようにタグ名[属性名]のように記述する。また、a[href="http://www.jaysong.net"]のようにhref属性の値が"http://www.jaysong.net"と一致する<a>タグを選択することもできる2。
以上ではCSSセレクターの書き方について紹介したが、実はHTML内の要素を指定するもう一つの記述方法があり、それがXPathというものだ。たとえば、<img>タグの場合、CSSはimg、XPathでは//imgと記述する。また、クラスはCSSだと.クラス名、XPathだと//*[contains(@class,"クラス名")]となり、IDはそれぞれ#ID名、//*[@id="ID名"]となる。通常、CSSセレクターの方がXPathより簡潔なので、より幅広く使われる。しかし、XPathではCSSセレクターでは指定できない要素まで指定できるなど、機能面ではより強力だ。また、規則的なページ構造を持たないページのスクレイピングはSeleniumというものを使う場面が多いが、SeleniumではCSSセレクターよりXPathの方が幅広く使われる。本章で紹介する{rvest}パッケージはいずれの書き方にも対応しているが、引数を指定しない場合は第2引数であるCSSセレクターの書き方となる。XPathを使う場合はxpath = "XPath ID"のように仮引数名を指定する必要がある。
32.1.4 セレクターの確認
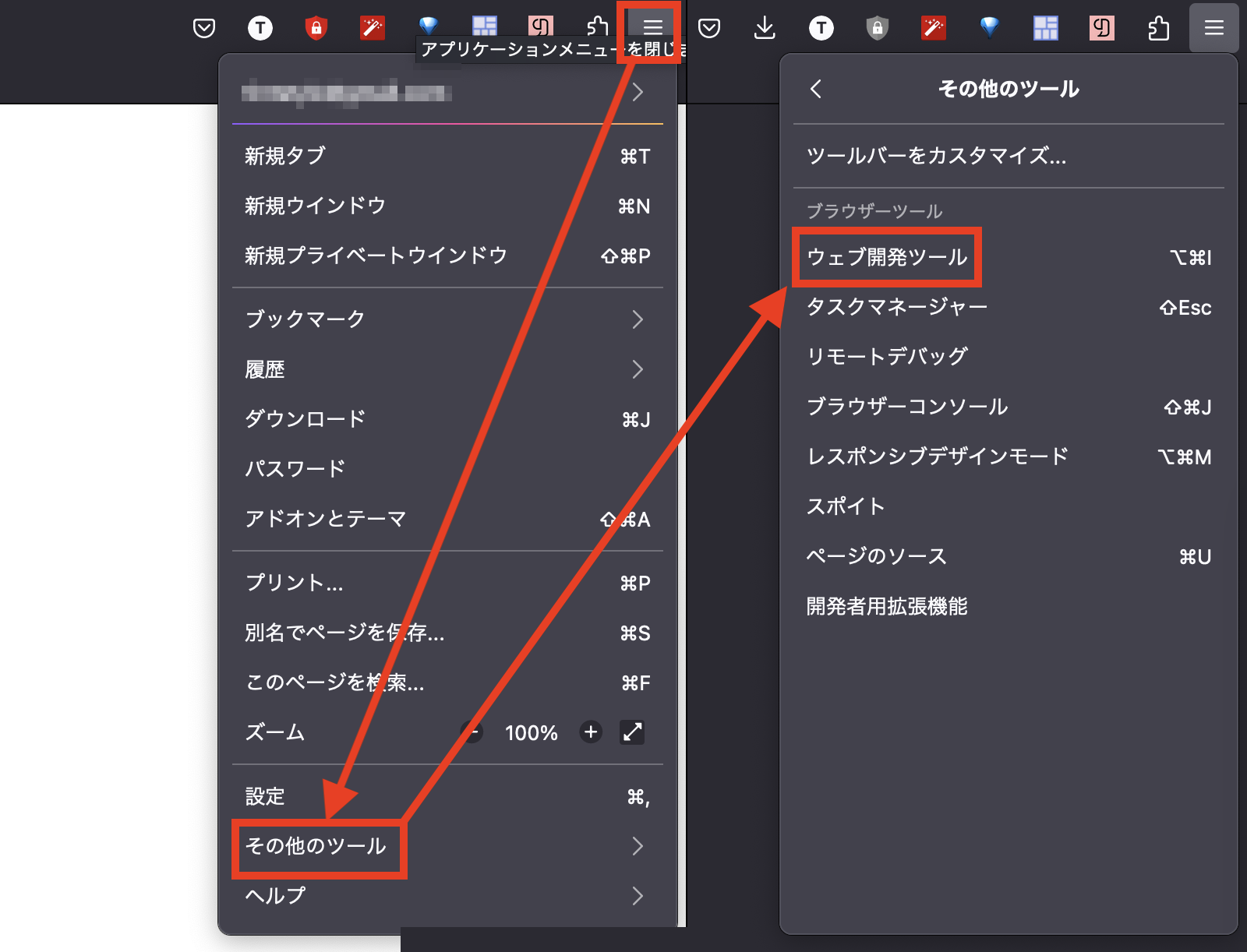
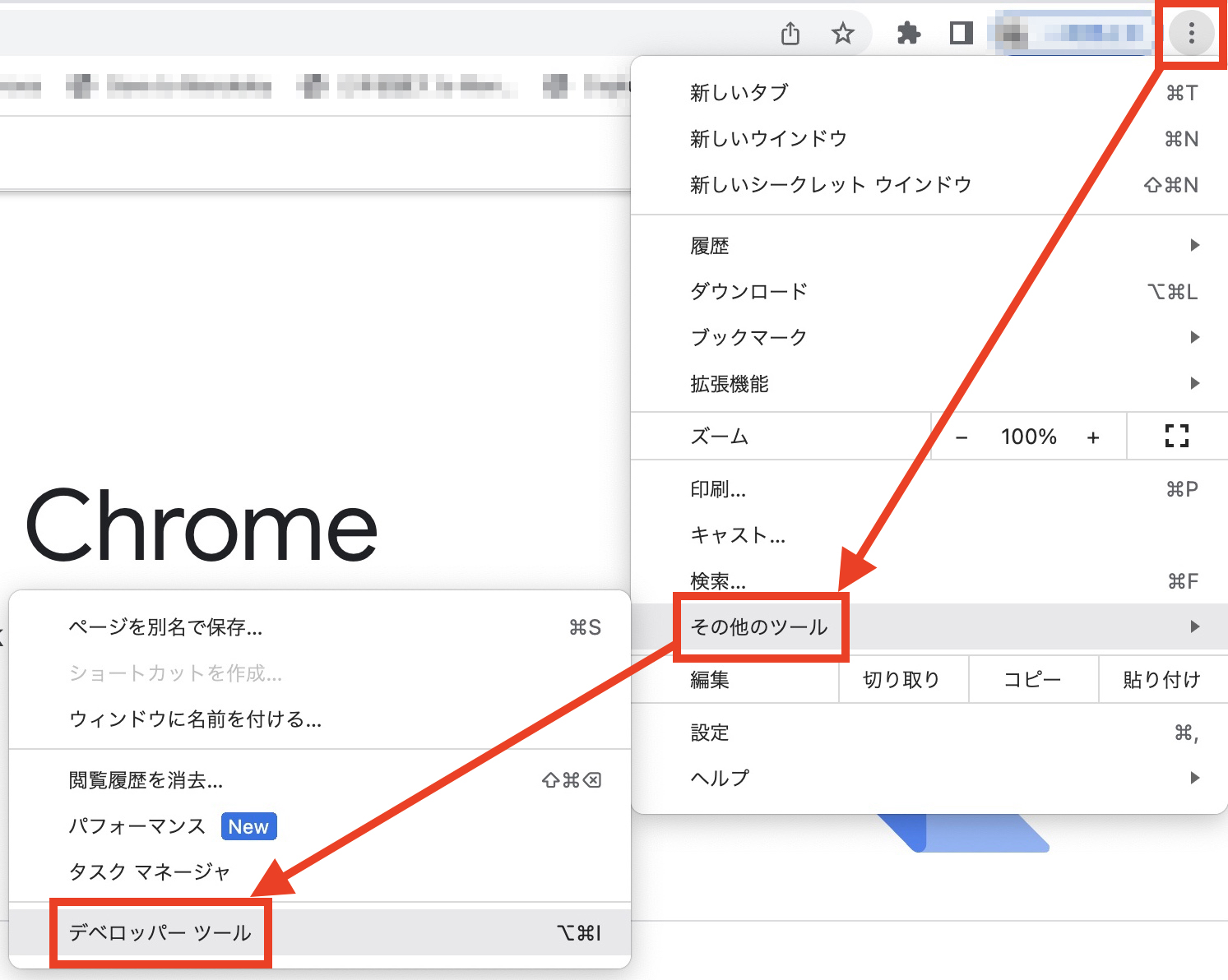
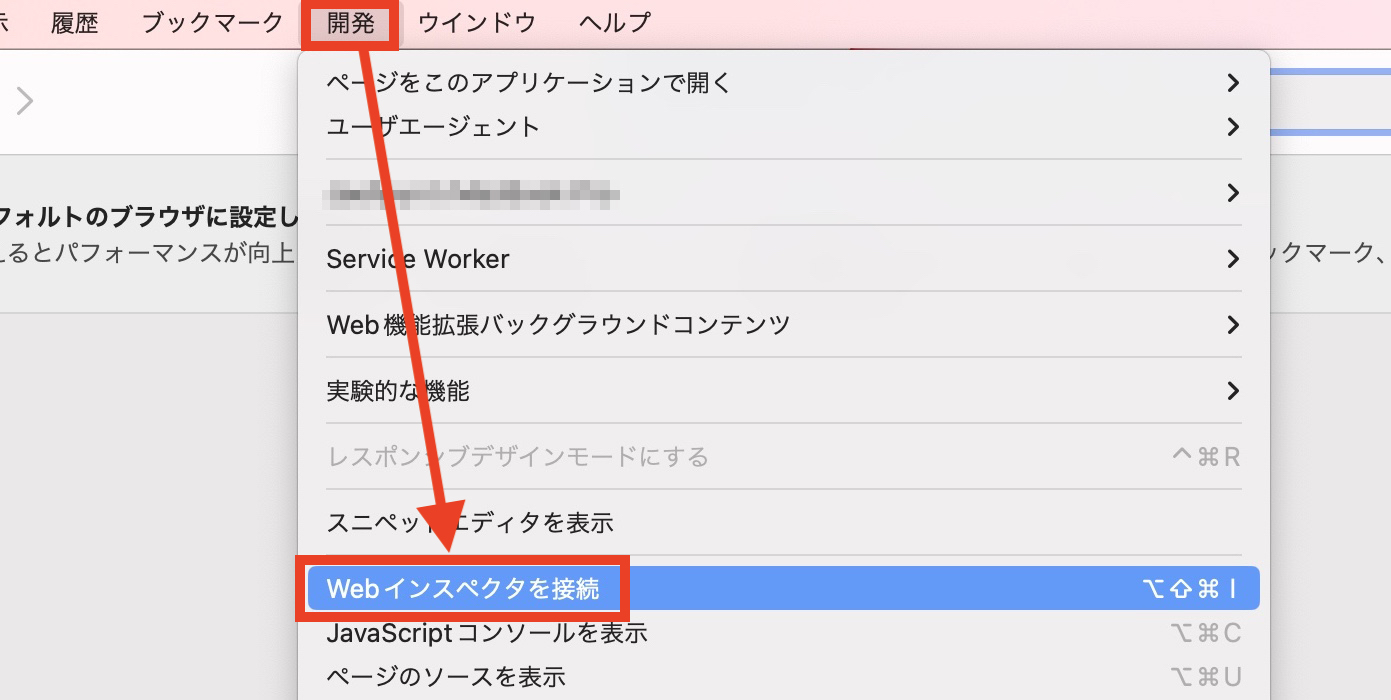
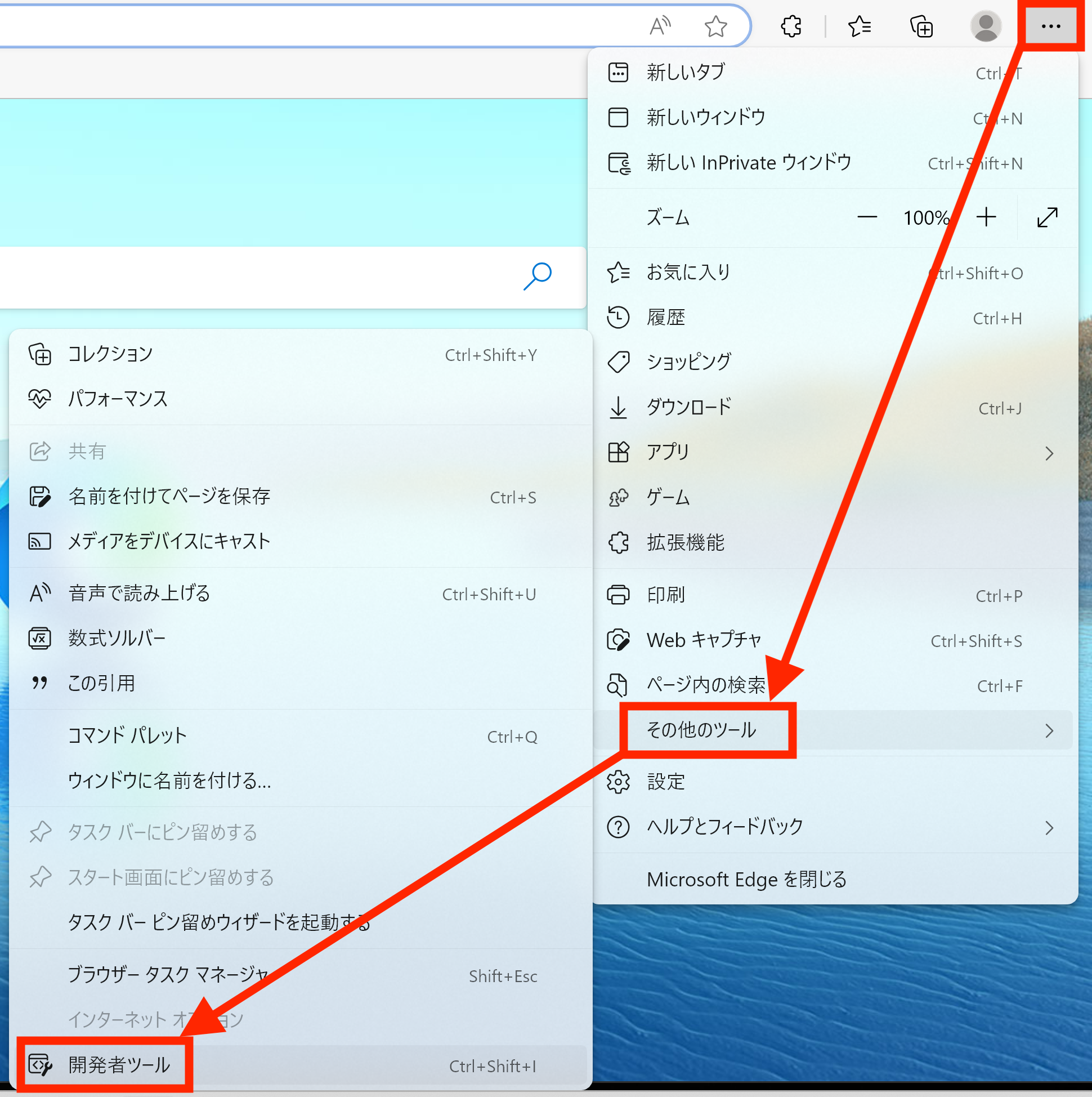
CSSを勉強する場合のセレクターの話はもっと長くなるが、スクレイピング入門レベルであれば、タグ、ID、クラス、属性セレクターだけでも問題ない3。つまり、自分がスクレイピングしたい内容のタグ、ID、クラス、属性を知るだけで十分だ。これを調べるにはHTMLソースコードを読む必要はあるが、最近のHTMLページは数百〜数千行のコードで構成されているため、すべてを精査することは現実的でない。最近のウェブブラウザーには開発者専用のメニューが用意されており、これを活用すると素早く必要な内容のセレクターを調べることができる。しかし、ブラウザーごとに開発者メニューの開き方が異なる。以下ではstatcounter基準、代表的な4つのブラウザーの例を紹介する。
右上の「≡」>その他のツール>ウェブ開発ツール
右上の「⋮」>その他のツール>デベロッパーツール
開発 > Webインスペクタを接続
- 開発メニューがない場合は環境設定の「詳細」タブの「メニューバーに”開発”メニューを表示」にチェックを入れる必要がある。
右上の「…」>その他のツール>開発者ツール
ここからは筆者(宋)が使用しているFirefox基準で説明するが、どのブラウザーでも使い方は大きく変わらない。以下は『私たちのR』の初期ページからウェブ開発メニューを開いたものである。
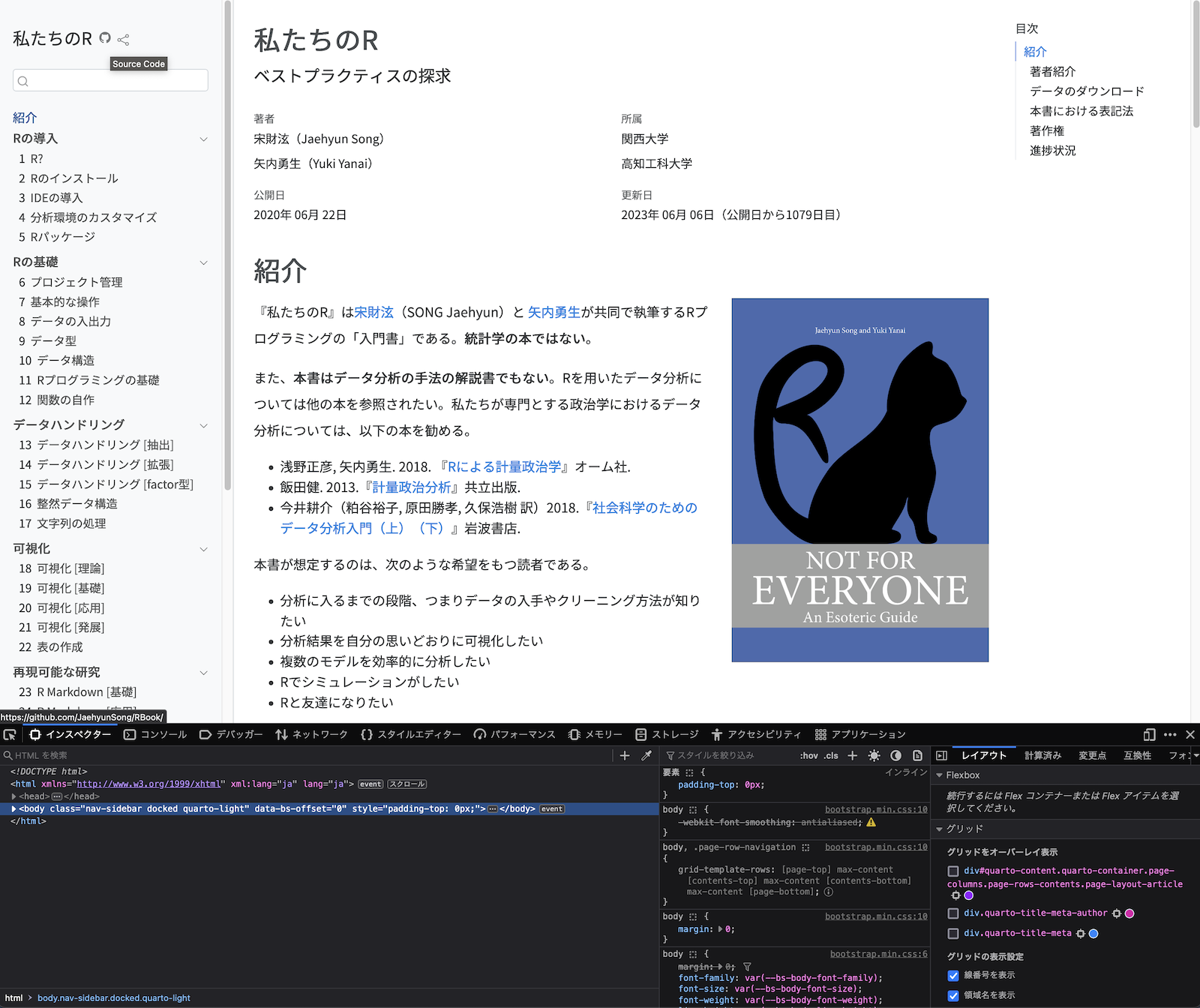
このページのコードは2023年6月現在、1148行である。ここで、画面右にある『私たちのR』のカーバー(仮)のタグ、クラス、ID、属性、親タグなどを調べてみよう。まず、ウェブ開発メニューの左上にある ボタンをクリックする。これはページ内の要素を選択し、その要素のコードなどを表示してくれる機能である。このボタンのアイコンはブラウザーごとにことなるが、開発者メニューの左上か右上に位置する。
ボタンをクリックする。これはページ内の要素を選択し、その要素のコードなどを表示してくれる機能である。このボタンのアイコンはブラウザーごとにことなるが、開発者メニューの左上か右上に位置する。
続いて、調べたい要素を選択する。マウスカーソルを要素の上に乗せるとハイライトされるため、分かりやすい。調べたい要素がハイライトされたらそのままクリックすると、開発者メニューに当該箇所のソースコードが表示される。
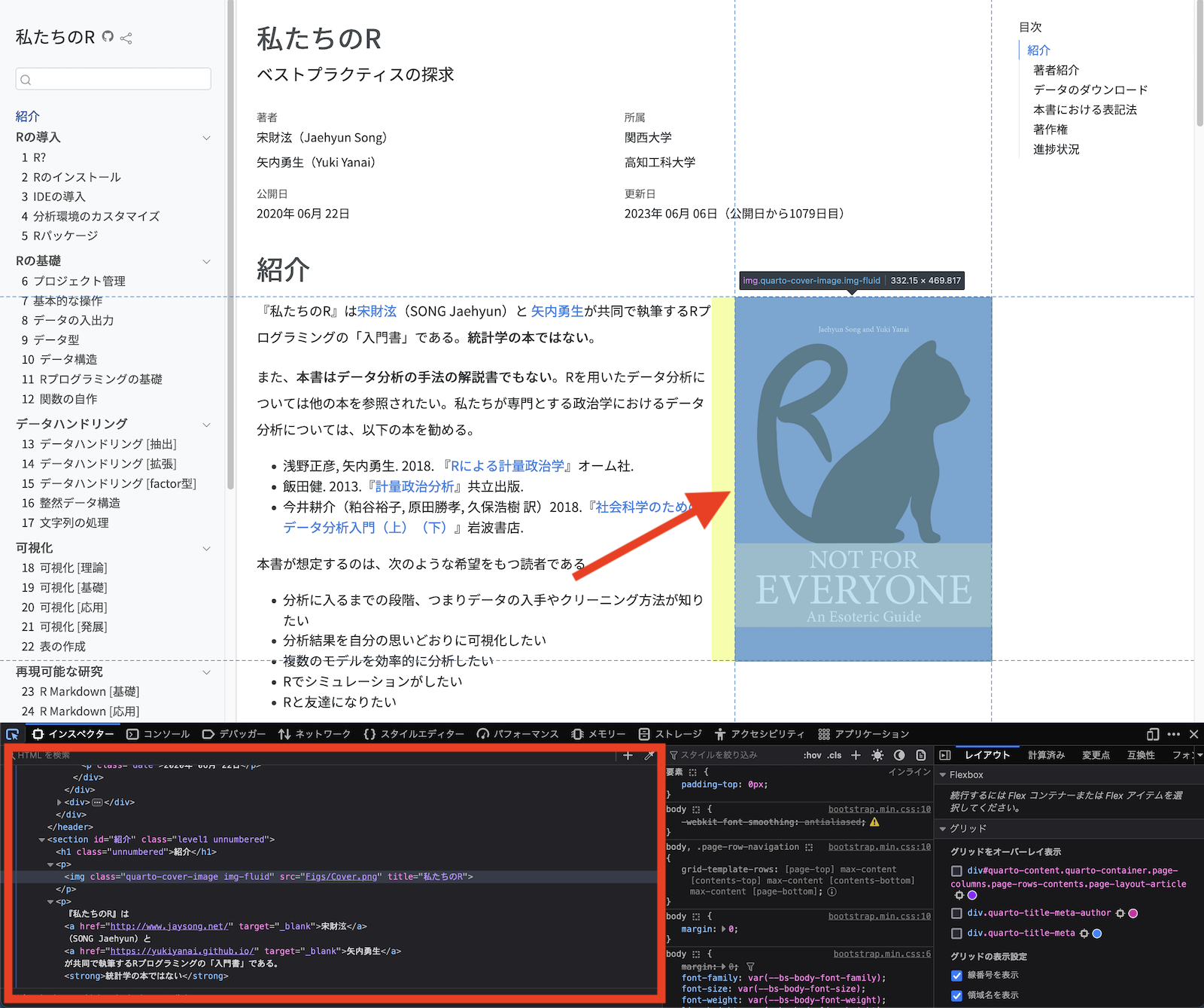
以下は当該箇所のコードの一部を抜粋したものだ。
当該箇所のタグは<img>である。クラスはquarto-cover-imageとimg-fluid、2つだ。他にもsrcとtitleという属性を持ち、それぞれ"Figs/Cover.png"と"私たちのR"という値が割り当てられている。他にもこの<img>タグの親タグは<p>であり、その親タグは<section>タグだということが分かる。ここでこの図の情報が必要な場合、セレクターはimg十分だろうか。答えはNoだ。このページにはこの画像以外にもイケメン著者たちの写真もある。imgだけだとどの図なのかが分からない。この図を特定するためには更に情報が必要だ。
たとえば、<img>のtitle属性に注目しても良いだろう。イケメン著者たちの画像はtitle属性を持たない(各自確認してみよう)が、カーバー(仮)にはtitle="私たちのR"がある。これを利用するとimg[title="私たちのR"]といったセレクターも有効だろう。もう一つは親のタグ、ID、クラスなどを利用する方法だ。カーバー(仮)の親タグの一つは<section>であり、"紹介"というIDが指定されている。IDはこのページに1回しか登場しないものであるため、これは使えるかも知れない。このページ内の2つの画像のコードを簡単に示すと以下の通りだ。
どの画像も親タグは<section>であるが、異なるIDを持つ。つまり、異なる親を持つ。カーバー(仮)はid="紹介"、イケメン著者はid="著者紹介"の<section>親を持つ。この場合、(1)IDが"著者"の要素を選択し(#紹介)、(2)<img>タグを選択する(img)といった手順で、欲しい内容が抽出できる。本章では基本的に、このような多段階の抽出方法を採用する。より洗練された書き方で効率的なスクレイピングもできるが、入門レベルだとこのようなやり方でも問題ないだろう。それではRにおけるスクレイピングの定番パッケージ、{rvest}の簡単な使い方を見てみよう。
32.2 {rvest}の使い方
実際のウェブスクレイピングをやってみる前に、{rvest}パッケージを使って実習用のページ(sample01.html)の内容を取得してみよう。
- テキスト/表の取得
html_elment()、html_elments()で特定のタグやクラス、IDを抽出html_text()、html_text2()やhtml_table()で抽出- 画像の場合、
<img>タグのsrc属性を抽出する必要があるため、html_attr()
まずは、read_html()関数を使用し、スクレイピングするHTMLファイルそのものを読み込んでおく必要がある。引数はHTMLファイルのURL、もしくはパスだけで問題ないが、Shift-JISやEUC-KRといった邪悪なロケールで作成されたページであれば、encoding引数が必要となる。サンプルページはUTF-8であるため、URLのみで問題ない。
{html_document}
<html>
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
[2] <body>\n\t\t<h1>第1章:文章</h1>\n\t\t<p>『<a href="https://www.jaysong.net/RBo ...中身は簡単にしか確認できないが、そもそもRでコードをすべて表示する必要もないので問題ないだろう。HTMLのソースコード全体が見たい場合はウェブブラウザーから確認しよう。ここでは問題なくHTMLファイルが読み込まれていることだけを確認すれば良い。
それではこのmy_htmlからいくつかの要素を抽出してみよう。まずは、タグ名セレクターを使用し、特定のタグだけを抽出する。ここで使用する関数はhtml_elements()だ4。たとえば、ハイパーリンクを意味する<a>タグが使用された箇所すべてを読み組むにはhtml_elemtns(HTMLオブジェクト名, "a")で良い。HTMLオブジェクト名(今回はmy_html)は第1引数だから、パイプ演算子を使用しよう。
{xml_nodeset (3)}
[1] <a href="https://www.jaysong.net/RBook/" id="rbook" class="book-title">私た ...
[2] <a href="https://www.jaysong.net/">宋財泫</a>
[3] <a href="https://yukiyanai.github.io/">矢内勇生</a> しかし、通常、これらの内容すべてが必要になるケースは稀だろう。普通、<a>と</a>に囲まれたテキストの内容や、リンク先のURLのリストが欲しいだろう。html_elements()で指定したセレクター内のテキストを抽出する場合は、html_text()を使用する5。
<a>と</a>に囲まれたテキストの内容でなく、リンク先のURLを抽出することもできる。<a>タグのリンク先はhref属性で指定するため、href属性の値を抽出すれば良い。特定の属性の値を取得する関数はhtml_attr()であり、引数として属性名を指定すれば良い。
[1] "https://www.jaysong.net/RBook/" "https://www.jaysong.net/"
[3] "https://yukiyanai.github.io/" 続いて、箇条書きの要素を抽出してみよう。今回は2本の書籍リストが対象だ。箇条書きの内容は<li>タグで記述されるので、html_elements("li")で<li>タグの内容を取得してみよう。
{xml_nodeset (5)}
[1] <li>浅野正彦・矢内勇生. 2018. 『<span class="book-title">Rによる計量政治学</span>』オーム社.</li>
[2] <li>飯田健. 2013.『<span class="book-title">計量政治分析</span>』共立出版.</li>
[3] <li>聞いて...</li>
[4] <li>感じて...</li>
[5] <li>考えて...</li> 書籍リストだけでなく、謎の言葉も取得される。実際、サンプルページには2つの箇条書きがあり、書籍は順序なしの箇条書き(<ul>)、謎の言葉は順序付き箇条書き(<ol>)である。したがって、まず、<ul>タグを抽出し、そこから<li>を抽出すれば良い。
{xml_nodeset (2)}
[1] <li>浅野正彦・矢内勇生. 2018. 『<span class="book-title">Rによる計量政治学</span>』オーム社.</li>
[2] <li>飯田健. 2013.『<span class="book-title">計量政治分析</span>』共立出版.</li> ちなみにhtml_elements()が続く場合は引数を"タグ名 > タグ名"にしても同じ結果が得られる。
{xml_nodeset (2)}
[1] <li>浅野正彦・矢内勇生. 2018. 『<span class="book-title">Rによる計量政治学</span>』オーム社.</li>
[2] <li>飯田健. 2013.『<span class="book-title">計量政治分析</span>』共立出版.</li> ここから更にテキストのみ抽出する場合はhtml_text()を使えば良い。
[1] "浅野正彦・矢内勇生. 2018. 『Rによる計量政治学』オーム社."
[2] "飯田健. 2013.『計量政治分析』共立出版." html_elements()にはタグ名以外のセレクターも使える。たとえば、クラス(.クラス名)やID(#ID名)の指定もできる。サンプルページには書籍名が3回登場し、それらは<span>タグに囲まれている。<span>タグそのものは機能を持たないが、文章の一部などにIDやクラスを割り当てる際によく使われる6。今回の例だと、書籍名はクラスがbook-titleの<span>タグで囲まれている。したがって、書籍名を抽出する時にはhtml_elements(".book-title")
{xml_nodeset (3)}
[1] <a href="https://www.jaysong.net/RBook/" id="rbook" class="book-title">私た ...
[2] <span class="book-title">Rによる計量政治学</span>
[3] <span class="book-title">計量政治分析</span> このようにbook-titleクラスのタグと、その内容が全て抽出される。ここからテキストを抽出する場合はhtml_text()を使えば良い。
スクレイピングで最も需要の高いものは表だろう。表の場合、HTMLでは<table>タグで記述されるが、{rvest}は表を取得し、tibble形式で返すhtml_table()関数が用意されている。これまで使ってきたhtml_elements()関数はあっても良いが、なくても問題ない。サンプルページには2つの表があるが、HTMLオブジェクトをそのままhtml_table()に渡すと表が抽出される。
[[1]]
# A tibble: 4 × 3
X1 X2 X3
<chr> <chr> <chr>
1 ID 名前 成績
2 1 田中 80
3 2 佐藤 100
4 3 渡辺 75
[[2]]
# A tibble: 4 × 3
X1 X2 X3
<chr> <chr> <chr>
1 ID 名前 成績
2 1 田中 20
3 2 佐藤 100
4 3 渡辺 90 長さ2のリストが出力され、それぞれ表が格納されている。今回のように、表のヘッダー(1行目)が中身として出力される場合もあるが、このような場合はheader = TRUEを指定すると、1行目が変数名となる。
[[1]]
# A tibble: 3 × 3
ID 名前 成績
<int> <chr> <int>
1 1 田中 80
2 2 佐藤 100
3 3 渡辺 75
[[2]]
# A tibble: 3 × 3
ID 名前 成績
<int> <chr> <int>
1 1 田中 20
2 2 佐藤 100
3 3 渡辺 90 この2つの表をbind_rows()を使って結合することもできる。まず、names()関数を使って、リストの各要素に名前を割り当てる。
$数学
# A tibble: 3 × 3
ID 名前 成績
<int> <chr> <int>
1 1 田中 80
2 2 佐藤 100
3 3 渡辺 75
$英語
# A tibble: 3 × 3
ID 名前 成績
<int> <chr> <int>
1 1 田中 20
2 2 佐藤 100
3 3 渡辺 90 続いて、bind_rows()関数に表のリストを入れ、.id変数で2つの表を識別する値が格納される列名を指定する。bind_rows()の詳細は第15.3章を参照されたい。
# A tibble: 6 × 4
科目 ID 名前 成績
<chr> <int> <chr> <int>
1 数学 1 田中 80
2 数学 2 佐藤 100
3 数学 3 渡辺 75
4 英語 1 田中 20
5 英語 2 佐藤 100
6 英語 3 渡辺 90 すべての表ではない、英語成績の表だけを抽出する場合はどうすれば良いだろうか。今回は表が2つしかなく、2番目の表が英語成績ということが分かっているのでmy_table[[2]]のような書き方でも問題ない。しかし、表が数百個ある場合は、何番目の表かを数えるのも簡単ではない。幸い、今回はそれぞれの表にmathとenglishといったIDが割り当てられている。このセレクターを使えば、IDが"english"の表を選択することもできよう。html_element()関数の引数として"#english"を指定し、そこからhtml_table()を実行すると英語成績の表だけが抽出される。
# A tibble: 3 × 3
ID 名前 成績
<int> <chr> <int>
1 1 田中 20
2 2 佐藤 100
3 3 渡辺 90 ここで一つ注意事項があるが、html_elements()でなく、html_element()を使う点だ。IDが1ページに1つしか存在しないため、html_element()を使った方が楽である。html_elements()を使っても良いが、返ってくるのはtibbleでなく、長さ1のリストになるので、更に[[1]]などでリストから表を取り出す必要がある。
32.3 実践
32.3.1 テキスト

{html_document}
<html xmlns="http://www.w3.org/1999/xhtml" lang="en" xml:lang="en">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
[2] <body class="nav-sidebar docked fullcontent quarto-light">\n\n<div id="qu ... ここからリンクを意味する<a>を抽出すれば良いが、このページには各章へのリンク以外にも多くの<a>タグが存在する。したがって、範囲を絞る必要があるが、本ページの「目次」の領域に限定すれば良いだろう。開発者メニューを見ると「目次」の見出しには目次というIDが振られているため、まずはIDセレクターで要素を絞ってから<a>タグを抽出する。
{xml_nodeset (37)}
[1] <a href="./aboutr.html">1</a>
[2] <a href="./installation.html">2</a>
[3] <a href="./ide.html">3</a>
[4] <a href="./r_customize.html">4</a>
[5] <a href="./packages.html">5</a>
[6] <a href="./project.html">6</a>
[7] <a href="./r_basic.html">7</a>
[8] <a href="./io.html">8</a>
[9] <a href="./datatype.html">9</a>
[10] <a href="./datastructure.html">10</a>
[11] <a href="./programming.html">11</a>
[12] <a href="./functions.html">12</a>
[13] <a href="./datahandling1.html">13</a>
[14] <a href="./datahandling2.html">14</a>
[15] <a href="./datahandling3.html">15</a>
[16] <a href="./factor.html">16</a>
[17] <a href="./tidydata.html">17</a>
[18] <a href="./string.html">18</a>
[19] <a href="./visualization1.html">19</a>
[20] <a href="./visualization2.html">20</a>
... ここから更にhref属性に割り当てられた値(ここではURL)のみを抽出する必要がある。ここでhtml_attr()関数を使用する。抽出したい属性名を引数として指定するだけだ。
[1] "./aboutr.html" "./installation.html" "./ide.html"
[4] "./r_customize.html" "./packages.html" "./project.html"
[7] "./r_basic.html" "./io.html" "./datatype.html"
[10] "./datastructure.html" "./programming.html" "./functions.html"
[13] "./datahandling1.html" "./datahandling2.html" "./datahandling3.html"
[16] "./factor.html" "./tidydata.html" "./string.html"
[19] "./visualization1.html" "./visualization2.html" "./visualization3.html"
[22] "./visualization4.html" "./table.html" "./quarto1.html"
[25] "./quarto2.html" "./quarto3.html" "./quarto4.html"
[28] "./renv.html" "./iteration.html" "./oop.html"
[31] "./monte.html" "./scraping.html" "./dataset.html"
[34] "./filesystem.html" "./tips.html" "./session.html"
[37] "./references.html" 続いて箇条書きの箇所(<li>タグ)を抽出しよう。
[1] "第1部: Rの導入\n第1章: R?\n第2章: Rのインストール\n第3章: IDEの導入\n第4章: 分析環境のカスタマイズ\n第5章: Rパッケージ\n"
[2] "第1章: R?"
[3] "第2章: Rのインストール"
[4] "第3章: IDEの導入"
[5] "第4章: 分析環境のカスタマイズ"
[6] "第5章: Rパッケージ"
[7] "第2部: Rの基礎\n第6章: プロジェクト管理\n第7章: 基本的な操作\n第8章: データの入出力\n第9章: データ型\n第10章: データ構造\n第11章: Rプログラミングの基礎\n第12章: 関数の自作\n"
[8] "第6章: プロジェクト管理"
[9] "第7章: 基本的な操作"
[10] "第8章: データの入出力"
[11] "第9章: データ型"
[12] "第10章: データ構造"
[13] "第11章: Rプログラミングの基礎"
[14] "第12章: 関数の自作"
[15] "第3部: データハンドリング\n第13章: データハンドリング [抽出]\n第14章: データハンドリング [要約]\n第15章: データハンドリング [拡張]\n第16章: データハンドリング [factor型]\n第17章: 整然データ構造\n第18章: 文字列の処理\n"
[16] "第13章: データハンドリング [抽出]"
[17] "第14章: データハンドリング [要約]"
[18] "第15章: データハンドリング [拡張]"
[19] "第16章: データハンドリング [factor型]"
[20] "第17章: 整然データ構造"
[21] "第18章: 文字列の処理"
[22] "第4部: 可視化\n第19章: 可視化[理論]\n第20章: 可視化[基礎]\n第21章: 可視化[応用]\n第22章: 可視化[発展]\n第23章: 表の作成\n"
[23] "第19章: 可視化[理論]"
[24] "第20章: 可視化[基礎]"
[25] "第21章: 可視化[応用]"
[26] "第22章: 可視化[発展]"
[27] "第23章: 表の作成"
[28] "第5部: 再現可能な研究\n第24章: Quarto [基礎]\n第25章: Quarto [文書]\n第26章: Quarto [スライド]\n第27章: Quarto [発展]\n第28章: 分析環境の管理\n"
[29] "第24章: Quarto [基礎]"
[30] "第25章: Quarto [文書]"
[31] "第26章: Quarto [スライド]"
[32] "第27章: Quarto [発展]"
[33] "第28章: 分析環境の管理"
[34] "第6部: 中級者向け\n第29章: 反復処理\n第30章: オブジェクト指向プログラミング\n第31章: モンテカルロ・シミュレーション\n第32章: スクレイピング\n"
[35] "第29章: 反復処理"
[36] "第30章: オブジェクト指向プログラミング"
[37] "第31章: モンテカルロ・シミュレーション"
[38] "第32章: スクレイピング"
[39] "付録\nデータセット\nファイルシステム\nR Tips\n本書の執筆環境\n参考文献\n"
[40] "データセット"
[41] "ファイルシステム"
[42] "R Tips"
[43] "本書の執筆環境"
[44] "参考文献" 概ね問題はなさそうに見えるが、章だけでなく、部("第1部: Rの導入\n第1章: R?\n第2章: Rのインストール\n第3章: IDEの導入\n第4章: 分析環境のカスタマイズ\n第5章: Rパッケージ\n"など)が書かれた<li>タグまで抽出されてしまった。スクレイピングする内容が今回のように少ないのであれば、自分で一つ一つ消しても良いが、ここではすべて自動化しよう。
まず、開発者メニューを開き、章の箇所(どの章でも良い)を選択する。以下は「第1章: R?」とその前後のコードである(『私たちのR』は日々更新されるため、全く同じコードとは限らない)。
<section id="目次" class="level2">
<h2 class="anchored" data-anchor-id="目次">目次</h2>
<p>章立ては未定。著者が書きたいものから書く予定 (全部で30~35章くらいになる見込み)。</p>
<ul>
<li>第1部: Rの導入
<ul>
<li>第<a href="https://www.jaysong.net/RBook/aboutr.html">1</a>章: R?</li>
<li>第<a href="https://www.jaysong.net/RBook/installation.html">2</a>章: Rのインストール</li>
<li>第<a href="https://www.jaysong.net/RBook/ide.html">3</a>章: IDEの導入</li>
<li>第<a href="https://www.jaysong.net/RBook/r_customize.html">4</a>章: 分析環境のカスタマイズ</li>
<li>第<a href="https://www.jaysong.net/RBook/package.qmd">5</a>章: Rパッケージ</li>
</ul></li>
<li>第2部: Rの基礎 「第1章: R?」は上記のコードの7行目にある。また、その親タグは<ul>、そしてそれの親タグは<li>、そして<ul>もある。これは第2章も、第30章も同じだ。つまり、IDが目次の内容(#目次)の中、<ul>の中の<li>の中の<ul>の中の<li>の箇所を取り出せば良い。セレクターは"ul li ul li"と記述する7。
[1] "第1章: R?"
[2] "第2章: Rのインストール"
[3] "第3章: IDEの導入"
[4] "第4章: 分析環境のカスタマイズ"
[5] "第5章: Rパッケージ"
[6] "第6章: プロジェクト管理"
[7] "第7章: 基本的な操作"
[8] "第8章: データの入出力"
[9] "第9章: データ型"
[10] "第10章: データ構造"
[11] "第11章: Rプログラミングの基礎"
[12] "第12章: 関数の自作"
[13] "第13章: データハンドリング [抽出]"
[14] "第14章: データハンドリング [要約]"
[15] "第15章: データハンドリング [拡張]"
[16] "第16章: データハンドリング [factor型]"
[17] "第17章: 整然データ構造"
[18] "第18章: 文字列の処理"
[19] "第19章: 可視化[理論]"
[20] "第20章: 可視化[基礎]"
[21] "第21章: 可視化[応用]"
[22] "第22章: 可視化[発展]"
[23] "第23章: 表の作成"
[24] "第24章: Quarto [基礎]"
[25] "第25章: Quarto [文書]"
[26] "第26章: Quarto [スライド]"
[27] "第27章: Quarto [発展]"
[28] "第28章: 分析環境の管理"
[29] "第29章: 反復処理"
[30] "第30章: オブジェクト指向プログラミング"
[31] "第31章: モンテカルロ・シミュレーション"
[32] "第32章: スクレイピング"
[33] "データセット"
[34] "ファイルシステム"
[35] "R Tips"
[36] "本書の執筆環境"
[37] "参考文献" 今回は章の文字列だけ取得できた。それでは章のタイトルのベクトル(rbook_titles)とURL(rbook_urls)を一つの表としてまとめてみよう。
# A tibble: 37 × 2
Titles URL
<chr> <chr>
1 第1章: R? ./aboutr.html
2 第2章: Rのインストール ./installation.html
3 第3章: IDEの導入 ./ide.html
4 第4章: 分析環境のカスタマイズ ./r_customize.html
5 第5章: Rパッケージ ./packages.html
6 第6章: プロジェクト管理 ./project.html
7 第7章: 基本的な操作 ./r_basic.html
8 第8章: データの入出力 ./io.html
9 第9章: データ型 ./datatype.html
10 第10章: データ構造 ./datastructure.html
11 第11章: Rプログラミングの基礎 ./programming.html
12 第12章: 関数の自作 ./functions.html
13 第13章: データハンドリング [抽出] ./datahandling1.html
14 第14章: データハンドリング [要約] ./datahandling2.html
15 第15章: データハンドリング [拡張] ./datahandling3.html
16 第16章: データハンドリング [factor型] ./factor.html
17 第17章: 整然データ構造 ./tidydata.html
18 第18章: 文字列の処理 ./string.html
19 第19章: 可視化[理論] ./visualization1.html
20 第20章: 可視化[基礎] ./visualization2.html
21 第21章: 可視化[応用] ./visualization3.html
22 第22章: 可視化[発展] ./visualization4.html
23 第23章: 表の作成 ./table.html
24 第24章: Quarto [基礎] ./quarto1.html
25 第25章: Quarto [文書] ./quarto2.html
26 第26章: Quarto [スライド] ./quarto3.html
27 第27章: Quarto [発展] ./quarto4.html
28 第28章: 分析環境の管理 ./renv.html
29 第29章: 反復処理 ./iteration.html
30 第30章: オブジェクト指向プログラミング ./oop.html
31 第31章: モンテカルロ・シミュレーション ./monte.html
32 第32章: スクレイピング ./scraping.html
33 データセット ./dataset.html
34 ファイルシステム ./filesystem.html
35 R Tips ./tips.html
36 本書の執筆環境 ./session.html
37 参考文献 ./references.html 続いて、separate()関数を使って章とタイトルを": "文字列を基準に別の列として分割し、それぞれSectionとTitleという列とする。ただし、30章以降は付録であるため、": "は存在しない。したがって、章かタイトルどちらかは欠損値となるが、今回は左側を欠損値として埋めたいのでfill = "left"を追加する。さらに、URLも完全なURLにする。まず、付録のURLが何故か"./"で始まるようになっているので、str_remove()を使って除去する。そうすればファイル名だけが残り、後はこれらのファイル名の前に"https://www.jaysong.net/RBook/"を付けるだけだ。
# A tibble: 37 × 3
Section Title URL
<chr> <chr> <chr>
1 第1章 R? https://www.jaysong.net/RBook/aboutr.…
2 第2章 Rのインストール https://www.jaysong.net/RBook/install…
3 第3章 IDEの導入 https://www.jaysong.net/RBook/ide.html
4 第4章 分析環境のカスタマイズ https://www.jaysong.net/RBook/r_custo…
5 第5章 Rパッケージ https://www.jaysong.net/RBook/package…
6 第6章 プロジェクト管理 https://www.jaysong.net/RBook/project…
7 第7章 基本的な操作 https://www.jaysong.net/RBook/r_basic…
8 第8章 データの入出力 https://www.jaysong.net/RBook/io.html
9 第9章 データ型 https://www.jaysong.net/RBook/datatyp…
10 第10章 データ構造 https://www.jaysong.net/RBook/datastr…
11 第11章 Rプログラミングの基礎 https://www.jaysong.net/RBook/program…
12 第12章 関数の自作 https://www.jaysong.net/RBook/functio…
13 第13章 データハンドリング [抽出] https://www.jaysong.net/RBook/datahan…
14 第14章 データハンドリング [要約] https://www.jaysong.net/RBook/datahan…
15 第15章 データハンドリング [拡張] https://www.jaysong.net/RBook/datahan…
16 第16章 データハンドリング [factor型] https://www.jaysong.net/RBook/factor.…
17 第17章 整然データ構造 https://www.jaysong.net/RBook/tidydat…
18 第18章 文字列の処理 https://www.jaysong.net/RBook/string.…
19 第19章 可視化[理論] https://www.jaysong.net/RBook/visuali…
20 第20章 可視化[基礎] https://www.jaysong.net/RBook/visuali…
21 第21章 可視化[応用] https://www.jaysong.net/RBook/visuali…
22 第22章 可視化[発展] https://www.jaysong.net/RBook/visuali…
23 第23章 表の作成 https://www.jaysong.net/RBook/table.h…
24 第24章 Quarto [基礎] https://www.jaysong.net/RBook/quarto1…
25 第25章 Quarto [文書] https://www.jaysong.net/RBook/quarto2…
26 第26章 Quarto [スライド] https://www.jaysong.net/RBook/quarto3…
27 第27章 Quarto [発展] https://www.jaysong.net/RBook/quarto4…
28 第28章 分析環境の管理 https://www.jaysong.net/RBook/renv.ht…
29 第29章 反復処理 https://www.jaysong.net/RBook/iterati…
30 第30章 オブジェクト指向プログラミング https://www.jaysong.net/RBook/oop.html
31 第31章 モンテカルロ・シミュレーション https://www.jaysong.net/RBook/monte.h…
32 第32章 スクレイピング https://www.jaysong.net/RBook/scrapin…
33 <NA> データセット https://www.jaysong.net/RBook/dataset…
34 <NA> ファイルシステム https://www.jaysong.net/RBook/filesys…
35 <NA> R Tips https://www.jaysong.net/RBook/tips.ht…
36 <NA> 本書の執筆環境 https://www.jaysong.net/RBook/session…
37 <NA> 参考文献 https://www.jaysong.net/RBook/referen… 最後にrbook_dfを{gt}パッケージを使って表にする。sub_missing()関数を使って、欠損値の箇所を"付録"に置換し、fmt_url()を使って、URL列をリンクボタン化する。
| 章 | タイトル | リンク |
|---|---|---|
| 第1章 | R? | Link |
| 第2章 | Rのインストール | Link |
| 第3章 | IDEの導入 | Link |
| 第4章 | 分析環境のカスタマイズ | Link |
| 第5章 | Rパッケージ | Link |
| 第6章 | プロジェクト管理 | Link |
| 第7章 | 基本的な操作 | Link |
| 第8章 | データの入出力 | Link |
| 第9章 | データ型 | Link |
| 第10章 | データ構造 | Link |
| 第11章 | Rプログラミングの基礎 | Link |
| 第12章 | 関数の自作 | Link |
| 第13章 | データハンドリング [抽出] | Link |
| 第14章 | データハンドリング [要約] | Link |
| 第15章 | データハンドリング [拡張] | Link |
| 第16章 | データハンドリング [factor型] | Link |
| 第17章 | 整然データ構造 | Link |
| 第18章 | 文字列の処理 | Link |
| 第19章 | 可視化[理論] | Link |
| 第20章 | 可視化[基礎] | Link |
| 第21章 | 可視化[応用] | Link |
| 第22章 | 可視化[発展] | Link |
| 第23章 | 表の作成 | Link |
| 第24章 | Quarto [基礎] | Link |
| 第25章 | Quarto [文書] | Link |
| 第26章 | Quarto [スライド] | Link |
| 第27章 | Quarto [発展] | Link |
| 第28章 | 分析環境の管理 | Link |
| 第29章 | 反復処理 | Link |
| 第30章 | オブジェクト指向プログラミング | Link |
| 第31章 | モンテカルロ・シミュレーション | Link |
| 第32章 | スクレイピング | Link |
| 付録 | データセット | Link |
| 付録 | ファイルシステム | Link |
| 付録 | R Tips | Link |
| 付録 | 本書の執筆環境 | Link |
| 付録 | 参考文献 | Link |
32.3.2 表
まずは簡単な例から始めよう。ここでは英語版Wikipediaの世界報道自由度ランキングの表をスクレイピングする。長いURLは別途のオブジェクトに格納しておくと、コードが簡潔になるだけでなく、コードのリサイクルも簡単になる。ここでは読み込んだHTMLファイルをpfi_htmlという名のオブジェクトとして格納しておく。
{html_document}
<html class="client-nojs vector-feature-language-in-header-enabled vector-feature-language-in-main-menu-disabled vector-feature-language-in-main-page-header-disabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-clientpref-1 vector-feature-main-menu-pinned-disabled vector-feature-limited-width-clientpref-1 vector-feature-limited-width-content-enabled vector-feature-custom-font-size-clientpref-1 vector-feature-appearance-pinned-clientpref-1 skin-theme-clientpref-day vector-sticky-header-enabled wp25eastereggs-enable-clientpref-1 vector-toc-available skin-theme-clientpref-thumb-standard" lang="en" dir="ltr">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
[2] <body class="skin--responsive skin-vector skin-vector-search-vue mediawik ... 続いて、html_table()を使用し、pfi_htmlから表(<table>タグ)を取得し、pfi_tblsオブジェクトに格納する。
[[1]]
# A tibble: 179 × 8
Country `2025[12]` `2024[13]` `2023[14]` `2022[15]` `2021[16]` `2020[17]`
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 Norway (001)92.31 (001)91.89 (001)95.18 (001)92.65 (001)93.28 (001)92.16
2 Estonia (002)89.46 (006)86.44 (008)85.31 (004)88.83 (015)84.75 (014)87.39
3 Netherlands (003)88.64 (004)87.73 (006)87.00 (028)77.93 (006)90.33 (005)90.04
4 Sweden (004)88.13 (003)88.32 (004)88.15 (003)88.84 (003)92.76 (004)90.75
5 Finland (005)87.18 (005)86.55 (005)87.94 (005)88.42 (002)93.01 (002)92.07
6 Denmark (006)86.93 (002)89.60 (003)89.48 (002)90.27 (004)91.43 (003)91.87
7 Ireland (007)86.92 (008)85.59 (002)89.91 (006)88.3 (012)88.09 (013)87.40
8 Portugal (008)84.26 (007)85.90 (009)84.60 (007)87.07 (009)89.89 (010)88.17
9 Switzerland (009)83.98 (009)84.01 (012)84.40 (014)82.72 (010)89.45 (008)89.38
10 Czech Repu… (010)83.96 (017)80.14 (014)83.58 (020)80.54 (040)76.62 (040)76.43
# ℹ 169 more rows
# ℹ 1 more variable: `2019[18]` <chr>
[[2]]
# A tibble: 8 × 2
.mw-parser-output .navbar{display:inline;font-size:88…¹ .mw-parser-output .n…²
<chr> <chr>
1 "Freedom" "Freedom in the World…
2 "Corruption" "Bribe Payers Index\n…
3 "Competitiveness" "Composite Index of N…
4 "History" "Flag adoption date\n…
5 "Rights" "Global Gender Gap Re…
6 "Democracy" "Free and fair electi…
7 "Other" "Central bank indepen…
8 "List of international rankings\nLists by country" "List of internationa…
# ℹ abbreviated names:
# ¹`.mw-parser-output .navbar{display:inline;font-size:88%;font-weight:normal}.mw-parser-output .navbar-collapse{float:left;text-align:left}.mw-parser-output .navbar-boxtext{word-spacing:0}.mw-parser-output .navbar ul{display:inline-block;white-space:nowrap;line-height:inherit}.mw-parser-output .navbar-brackets::before{margin-right:-0.125em;content:"[ "}.mw-parser-output .navbar-brackets::after{margin-left:-0.125em;content:" ]"}.mw-parser-output .navbar li{word-spacing:-0.125em}.mw-parser-output .navbar a>span,.mw-parser-output .navbar a>abbr{text-decoration:inherit}.mw-parser-output .navbar-mini abbr{font-variant:small-caps;border-bottom:none;text-decoration:none;cursor:inherit}.mw-parser-output .navbar-ct-full{font-size:114%;margin:0 7em}.mw-parser-output .navbar-ct-mini{font-size:114%;margin:0 4em}html.skin-theme-clientpref-night .mw-parser-output .navbar li a abbr{color:var(--color-base)!important}@media(prefers-color-scheme:dark){html.skin-theme-clientpref-os .mw-parser-output .navbar li a abbr{color:var(--color-base)!important}}@media print{.mw-parser-output .navbar{display:none!important}}vteLists of countries by political rankings`,
# ²`.mw-parser-output .navbar{display:inline;font-size:88%;font-weight:normal}.mw-parser-output .navbar-collapse{float:left;text-align:left}.mw-parser-output .navbar-boxtext{word-spacing:0}.mw-parser-output .navbar ul{display:inline-block;white-space:nowrap;line-height:inherit}.mw-parser-output .navbar-brackets::before{margin-right:-0.125em;content:"[ "}.mw-parser-output .navbar-brackets::after{margin-left:-0.125em;content:" ]"}.mw-parser-output .navbar li{word-spacing:-0.125em}.mw-parser-output .navbar a>span,.mw-parser-output .navbar a>abbr{text-decoration:inherit}.mw-parser-output .navbar-mini abbr{font-variant:small-caps;border-bottom:none;text-decoration:none;cursor:inherit}.mw-parser-output .navbar-ct-full{font-size:114%;margin:0 7em}.mw-parser-output .navbar-ct-mini{font-size:114%;margin:0 4em}html.skin-theme-clientpref-night .mw-parser-output .navbar li a abbr{color:var(--color-base)!important}@media(prefers-color-scheme:dark){html.skin-theme-clientpref-os .mw-parser-output .navbar li a abbr{color:var(--color-base)!important}}@media print{.mw-parser-output .navbar{display:none!important}}vteLists of countries by political rankings` 当該ページには2つの表があり、我々が欲しい表はリストの1番目の要素である。pfi_tblsの1番目の要素のみを抽出し、更に2024[5]のような列名をYear2024のように修正し、pfi_dfに格納する。
# A tibble: 179 × 8
Country Year2025 Year2024 Year2023 Year2022 Year2021 Year2020 Year2019
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 Norway (001)92… (001)91… (001)95… (001)92… (001)93… (001)92… (001)92…
2 Estonia (002)89… (006)86… (008)85… (004)88… (015)84… (014)87… (011)87…
3 Netherlands (003)88… (004)87… (006)87… (028)77… (006)90… (005)90… (004)91…
4 Sweden (004)88… (003)88… (004)88… (003)88… (003)92… (004)90… (003)91…
5 Finland (005)87… (005)86… (005)87… (005)88… (002)93… (002)92… (002)92…
6 Denmark (006)86… (002)89… (003)89… (002)90… (004)91… (003)91… (005)90…
7 Ireland (007)86… (008)85… (002)89… (006)88… (012)88… (013)87… (015)85…
8 Portugal (008)84… (007)85… (009)84… (007)87… (009)89… (010)88… (012)87…
9 Switzerland (009)83… (009)84… (012)84… (014)82… (010)89… (008)89… (006)89…
10 Czech Republic (010)83… (017)80… (014)83… (020)80… (040)76… (040)76… (040)75…
# ℹ 169 more rows pfi_dfを見ると、Country以外の列は世界報道自由度指数以外にもカッコ内に順位が書かれていることが分かる。具体的には(順位)指数の構造になっている。str_remove()関数を使って、ここから(順位)の箇所を削除しよう。「(で始まり(=^\\()、一つ以上の数字が並び(=([0-9]+))、その後に出てくる)まで(=\\))」の箇所が削除対象であるため、正規表現は^\\(([0-9]+)\\)となる。正規表現の詳細は第18章を参照されたい。抽出が終わっても、まだcharacter型のままなので、as.numeric()関数でnumeric型に変換する。
# A tibble: 179 × 8
Country Year2025 Year2024 Year2023 Year2022 Year2021 Year2020 Year2019
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Norway 92.3 91.9 95.2 92.6 93.3 92.2 92.2
2 Estonia 89.5 86.4 85.3 88.8 84.8 87.4 87.7
3 Netherlands 88.6 87.7 87 77.9 90.3 90.0 91.4
4 Sweden 88.1 88.3 88.2 88.8 92.8 90.8 91.7
5 Finland 87.2 86.6 87.9 88.4 93.0 92.1 92.1
6 Denmark 86.9 89.6 89.5 90.3 91.4 91.9 90.1
7 Ireland 86.9 85.6 89.9 88.3 88.1 87.4 85
8 Portugal 84.3 85.9 84.6 87.1 89.9 88.2 87.4
9 Switzerland 84.0 84.0 84.4 82.7 89.4 89.4 89.5
10 Czech Republic 84.0 80.1 83.6 80.5 76.6 76.4 75.1
# ℹ 169 more rows これで表の抽出が終わった。すべての表を出力しても良いが、かなり長くなるため東アジア地域のみに限定してpfi_dfを{gt}パッケージで出力し、指数の値ごとに色分けをする。セルの色塗りについては第23.5章を参照されたい。
pfi_df |>
filter(Country %in% c("Japan", "South Korea", "North Korea", "China",
"Hong Kong", "Taiwan", "Mongolia")) |>
gt() |>
cols_label("Year2025" = "2025",
"Year2024" = "2024",
"Year2023" = "2023",
"Year2022" = "2022",
"Year2021" = "2021",
"Year2020" = "2020",
"Year2019" = "2019") |>
data_color(columns = Year2024:Year2019,
palette = "ggsci::blue_material")| Country | 2025 | 2024 | 2023 | 2022 | 2021 | 2020 | 2019 |
|---|---|---|---|---|---|---|---|
| Taiwan | 77.04 | 76.13 | 75.54 | 74.08 | 76.14 | 76.24 | 75.02 |
| South Korea | 64.06 | 64.87 | 70.83 | 72.11 | 76.57 | 76.30 | 75.06 |
| Japan | 63.14 | 62.12 | 63.95 | 64.37 | 71.12 | 71.14 | 70.64 |
| Mongolia | 52.57 | 51.34 | 59.33 | 59.17 | 71.03 | 70.39 | 70.49 |
| Hong Kong | 39.86 | 43.06 | 44.86 | 41.64 | 69.56 | 69.99 | 70.35 |
| China | 14.80 | 23.36 | 22.97 | 25.17 | 21.28 | 21.52 | 21.08 |
| North Korea | 12.64 | 20.66 | 21.72 | 13.92 | 18.72 | 14.18 | 16.60 |
32.3.3 表(複数ページ)
続いて、複数のHTMLページから表を取得してみよう。今回はJリーグ(1部から3部まで)の順位表(2023年)が対象である。
- J1: https://www.jleague.jp/standings/2023/
- J2: https://www.jleague.jp/standings/2023/j2/
- J3: https://www.jleague.jp/standings/2023/j3/
3つのページを見ると、ページの構造は一致することが分かる。また、表を意味する<table>タグを見ると、いずれもscoreTable01クラスが付与されていること分かる(各自、開発者メニューから確認してみよう)。したがって、同じ作業を3つのページに対して繰り返すだけで良いだろう。まずは、J1リーグだけ試してみよう。まず、HTMLファイルを読み込み、html_element(".scoreTable01")でscoreTalbe01クラスの要素を抽出し、そこからhtml_table()で表を抽出してみよう。
# A tibble: 19 × 12
X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11 X12
<lgl> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 NA 順位 クラブ名 勝点 試合数…… 勝 分 負 得点 失点 得失点…… "直近5…
2 NA 1 ヴィッセル神戸ヴィッ… 71 34 21 8 5 60 29 31 ""
3 NA 2 横浜F・マリノス横浜… 64 34 19 7 8 63 40 23 ""
4 NA 3 サンフレッチェ広島サ… 58 34 17 7 10 42 28 14 ""
5 NA 4 浦和レッズ浦和レッズ… 57 34 15 12 7 42 27 15 ""
6 NA 5 鹿島アントラーズ鹿島… 52 34 14 10 10 43 34 9 ""
7 NA 6 名古屋グランパス名古… 52 34 14 10 10 41 36 5 ""
8 NA 7 アビスパ福岡アビスパ… 51 34 15 6 13 37 43 -6 ""
9 NA 8 川崎フロンターレ川崎… 50 34 14 8 12 51 45 6 ""
10 NA 9 セレッソ大阪セレッソ… 49 34 15 4 15 39 34 5 ""
11 NA 10 アルビレックス新潟ア… 45 34 11 12 11 36 40 -4 ""
12 NA 11 FC東京FC東京…… 43 34 12 7 15 42 46 -4 ""
13 NA 12 北海道コンサドーレ札… 40 34 10 10 14 56 61 -5 ""
14 NA 13 京都サンガF.C.京… 40 34 12 4 18 40 45 -5 ""
15 NA 14 サガン鳥栖サガン鳥栖… 38 34 9 11 14 43 47 -4 ""
16 NA 15 湘南ベルマーレ湘南ベ… 34 34 8 10 16 40 56 -16 ""
17 NA 16 ガンバ大阪ガンバ大阪… 34 34 9 7 18 38 61 -23 ""
18 NA 17 柏レイソル柏レイソル… 33 34 6 15 13 33 47 -14 ""
19 NA 18 横浜FC横浜FC…… 29 34 7 8 19 31 58 -27 "" 今回もheader = TRUEを入れてヘッダーを指定する必要があると考えられる。また、取得する列は順位から得失点までなので、必要な列だけを抽出してみよう。
# A tibble: 18 × 10
順位 クラブ名 勝点 試合数 勝 分 負 得点 失点 得失点
<int> <chr> <int> <int> <int> <int> <int> <int> <int> <int>
1 1 ヴィッセル神戸ヴィッセル神戸…… 71 34 21 8 5 60 29 31
2 2 横浜F・マリノス横浜F・マリノス…… 64 34 19 7 8 63 40 23
3 3 サンフレッチェ広島サンフレッチェ広島…… 58 34 17 7 10 42 28 14
4 4 浦和レッズ浦和レッズ 57 34 15 12 7 42 27 15
5 5 鹿島アントラーズ鹿島アントラーズ…… 52 34 14 10 10 43 34 9
6 6 名古屋グランパス名古屋グランパス…… 52 34 14 10 10 41 36 5
7 7 アビスパ福岡アビスパ福岡…… 51 34 15 6 13 37 43 -6
8 8 川崎フロンターレ川崎フロンターレ…… 50 34 14 8 12 51 45 6
9 9 セレッソ大阪セレッソ大阪…… 49 34 15 4 15 39 34 5
10 10 アルビレックス新潟アルビレックス新潟…… 45 34 11 12 11 36 40 -4
11 11 FC東京FC東京 43 34 12 7 15 42 46 -4
12 12 北海道コンサドーレ札幌北海道コンサドーレ… 40 34 10 10 14 56 61 -5
13 13 京都サンガF.C.京都サンガF.C.…… 40 34 12 4 18 40 45 -5
14 14 サガン鳥栖サガン鳥栖 38 34 9 11 14 43 47 -4
15 15 湘南ベルマーレ湘南ベルマーレ…… 34 34 8 10 16 40 56 -16
16 16 ガンバ大阪ガンバ大阪 34 34 9 7 18 38 61 -23
17 17 柏レイソル柏レイソル 33 34 6 15 13 33 47 -14
18 18 横浜FC横浜FC 29 34 7 8 19 31 58 -27以上の作業を3つのページに対して繰り返せば良い。まずは、3つのURLが格納されたcharacter型ベクトルを作成しよう。
[1] "https://www.jleague.jp/standings/2023/"
[2] "https://www.jleague.jp/standings/2023/j2.html"
[3] "https://www.jleague.jp/standings/2023/j3.html"また、取得した3つの表を格納する空のリストを作成する。
続いてfor()を使用し、これらのスクレイピングを繰り返す。seq_along(j_urls)は1:length(j_urls)と同じ意味だ。
for (i in seq_along(j_urls)) {
# j_urlsのi番目のURLからHTMLファイルを読み込み、temp_htmlに格納
temp_html <- read_html(j_urls[i])
# 表を取得し、temp_tblに格納
temp_tbl <- temp_html |>
html_element(".scoreTable01") |>
html_table(header = TRUE) |>
select(順位:得失点)
# tbl_listにtemp_tblを格納する。
# tbl_listの名前はJ1、J2、J3になるようにする。
tbl_list[[paste0("J", i)]] <- temp_tbl
# 1つの表を取得したら1秒休む
Sys.sleep(1)
}
tbl_list$J1
# A tibble: 18 × 10
順位 クラブ名 勝点 試合数 勝 分 負 得点 失点 得失点
<int> <chr> <int> <int> <int> <int> <int> <int> <int> <int>
1 1 ヴィッセル神戸ヴィッセル神戸…… 71 34 21 8 5 60 29 31
2 2 横浜F・マリノス横浜F・マリノス…… 64 34 19 7 8 63 40 23
3 3 サンフレッチェ広島サンフレッチェ広島…… 58 34 17 7 10 42 28 14
4 4 浦和レッズ浦和レッズ 57 34 15 12 7 42 27 15
5 5 鹿島アントラーズ鹿島アントラーズ…… 52 34 14 10 10 43 34 9
6 6 名古屋グランパス名古屋グランパス…… 52 34 14 10 10 41 36 5
7 7 アビスパ福岡アビスパ福岡…… 51 34 15 6 13 37 43 -6
8 8 川崎フロンターレ川崎フロンターレ…… 50 34 14 8 12 51 45 6
9 9 セレッソ大阪セレッソ大阪…… 49 34 15 4 15 39 34 5
10 10 アルビレックス新潟アルビレックス新潟…… 45 34 11 12 11 36 40 -4
11 11 FC東京FC東京 43 34 12 7 15 42 46 -4
12 12 北海道コンサドーレ札幌北海道コンサドーレ… 40 34 10 10 14 56 61 -5
13 13 京都サンガF.C.京都サンガF.C.…… 40 34 12 4 18 40 45 -5
14 14 サガン鳥栖サガン鳥栖 38 34 9 11 14 43 47 -4
15 15 湘南ベルマーレ湘南ベルマーレ…… 34 34 8 10 16 40 56 -16
16 16 ガンバ大阪ガンバ大阪 34 34 9 7 18 38 61 -23
17 17 柏レイソル柏レイソル 33 34 6 15 13 33 47 -14
18 18 横浜FC横浜FC 29 34 7 8 19 31 58 -27
$J2
# A tibble: 22 × 10
順位 クラブ名 勝点 試合数 勝 分 負 得点 失点 得失点
<int> <chr> <int> <int> <int> <int> <int> <int> <int> <int>
1 1 FC町田ゼルビアFC町田ゼルビア…… 87 42 26 9 7 79 35 44
2 2 ジュビロ磐田ジュビロ磐田…… 75 42 21 12 9 74 44 30
3 3 東京ヴェルディ東京ヴェルディ…… 75 42 21 12 9 57 31 26
4 4 清水エスパルス清水エスパルス…… 74 42 20 14 8 78 34 44
5 5 モンテディオ山形モンテディオ山形…… 67 42 21 4 17 64 54 10
6 6 ジェフユナイテッド千葉ジェフユナイテッド… 67 42 19 10 13 61 53 8
7 7 V・ファーレン長崎V・ファーレン長崎…… 65 42 18 11 13 70 56 14
8 8 ヴァンフォーレ甲府ヴァンフォーレ甲府…… 64 42 18 10 14 60 50 10
9 9 大分トリニータ大分トリニータ…… 62 42 17 11 14 54 56 -2
10 10 ファジアーノ岡山ファジアーノ岡山…… 58 42 13 19 10 49 49 0
# ℹ 12 more rows
$J3
# A tibble: 20 × 10
順位 クラブ名 勝点 試合数 勝 分 負 得点 失点 得失点
<int> <chr> <int> <int> <int> <int> <int> <int> <int> <int>
1 1 愛媛FC愛媛FC 73 38 21 10 7 59 48 11
2 2 鹿児島ユナイテッドFC鹿児島ユナイテッド… 62 38 18 8 12 58 41 17
3 3 カターレ富山カターレ富山…… 62 38 19 5 14 59 48 11
4 4 FC今治FC今治 59 38 16 11 11 54 42 12
5 5 奈良クラブ奈良クラブ 57 38 15 12 11 45 32 13
6 6 ガイナーレ鳥取ガイナーレ鳥取…… 56 38 14 14 10 57 52 5
7 7 ヴァンラーレ八戸ヴァンラーレ八戸…… 56 38 15 11 12 49 47 2
8 8 FC岐阜FC岐阜 54 38 14 12 12 44 35 9
9 9 松本山雅FC松本山雅FC…… 54 38 15 9 14 51 47 4
10 10 いわてグルージャ盛岡いわてグルージャ盛岡… 54 38 15 9 14 48 49 -1
11 11 FC大阪FC大阪 53 38 14 11 13 41 38 3
12 12 Y.S.C.C.横浜Y.S.C.C.横浜… 52 38 14 10 14 48 50 -2
13 13 アスルクラロ沼津アスルクラロ沼津…… 51 38 15 6 17 48 48 0
14 14 AC長野パルセイロAC長野パルセイロ…… 50 38 13 11 14 52 60 -8
15 15 福島ユナイテッドFC福島ユナイテッドFC… 47 38 12 11 15 37 42 -5
16 16 カマタマーレ讃岐カマタマーレ讃岐…… 44 38 11 11 16 29 45 -16
17 17 FC琉球FC琉球 43 38 12 7 19 43 61 -18
18 18 SC相模原SC相模原 41 38 9 14 15 44 48 -4
19 19 テゲバジャーロ宮崎テゲバジャーロ宮崎…… 39 38 9 12 17 31 52 -21
20 20 ギラヴァンツ北九州ギラヴァンツ北九州…… 31 38 7 10 21 33 45 -12 bind_rows()を使ってリスト内の3つの表を結合し、{gt}パッケージで表示する。
| リーグ | 順位 | クラブ名 | 勝点 | 試合数 | 勝 | 分 | 負 | 得点 | 失点 | 得失点 |
|---|---|---|---|---|---|---|---|---|---|---|
| J1 | 1 | ヴィッセル神戸ヴィッセル神戸 | 71 | 34 | 21 | 8 | 5 | 60 | 29 | 31 |
| J1 | 2 | 横浜F・マリノス横浜F・マリノス | 64 | 34 | 19 | 7 | 8 | 63 | 40 | 23 |
| J1 | 3 | サンフレッチェ広島サンフレッチェ広島 | 58 | 34 | 17 | 7 | 10 | 42 | 28 | 14 |
| J1 | 4 | 浦和レッズ浦和レッズ | 57 | 34 | 15 | 12 | 7 | 42 | 27 | 15 |
| J1 | 5 | 鹿島アントラーズ鹿島アントラーズ | 52 | 34 | 14 | 10 | 10 | 43 | 34 | 9 |
| J1 | 6 | 名古屋グランパス名古屋グランパス | 52 | 34 | 14 | 10 | 10 | 41 | 36 | 5 |
| J1 | 7 | アビスパ福岡アビスパ福岡 | 51 | 34 | 15 | 6 | 13 | 37 | 43 | -6 |
| J1 | 8 | 川崎フロンターレ川崎フロンターレ | 50 | 34 | 14 | 8 | 12 | 51 | 45 | 6 |
| J1 | 9 | セレッソ大阪セレッソ大阪 | 49 | 34 | 15 | 4 | 15 | 39 | 34 | 5 |
| J1 | 10 | アルビレックス新潟アルビレックス新潟 | 45 | 34 | 11 | 12 | 11 | 36 | 40 | -4 |
| J1 | 11 | FC東京FC東京 | 43 | 34 | 12 | 7 | 15 | 42 | 46 | -4 |
| J1 | 12 | 北海道コンサドーレ札幌北海道コンサドーレ札幌 | 40 | 34 | 10 | 10 | 14 | 56 | 61 | -5 |
| J1 | 13 | 京都サンガF.C.京都サンガF.C. | 40 | 34 | 12 | 4 | 18 | 40 | 45 | -5 |
| J1 | 14 | サガン鳥栖サガン鳥栖 | 38 | 34 | 9 | 11 | 14 | 43 | 47 | -4 |
| J1 | 15 | 湘南ベルマーレ湘南ベルマーレ | 34 | 34 | 8 | 10 | 16 | 40 | 56 | -16 |
| J1 | 16 | ガンバ大阪ガンバ大阪 | 34 | 34 | 9 | 7 | 18 | 38 | 61 | -23 |
| J1 | 17 | 柏レイソル柏レイソル | 33 | 34 | 6 | 15 | 13 | 33 | 47 | -14 |
| J1 | 18 | 横浜FC横浜FC | 29 | 34 | 7 | 8 | 19 | 31 | 58 | -27 |
| J2 | 1 | FC町田ゼルビアFC町田ゼルビア | 87 | 42 | 26 | 9 | 7 | 79 | 35 | 44 |
| J2 | 2 | ジュビロ磐田ジュビロ磐田 | 75 | 42 | 21 | 12 | 9 | 74 | 44 | 30 |
| J2 | 3 | 東京ヴェルディ東京ヴェルディ | 75 | 42 | 21 | 12 | 9 | 57 | 31 | 26 |
| J2 | 4 | 清水エスパルス清水エスパルス | 74 | 42 | 20 | 14 | 8 | 78 | 34 | 44 |
| J2 | 5 | モンテディオ山形モンテディオ山形 | 67 | 42 | 21 | 4 | 17 | 64 | 54 | 10 |
| J2 | 6 | ジェフユナイテッド千葉ジェフユナイテッド千葉 | 67 | 42 | 19 | 10 | 13 | 61 | 53 | 8 |
| J2 | 7 | V・ファーレン長崎V・ファーレン長崎 | 65 | 42 | 18 | 11 | 13 | 70 | 56 | 14 |
| J2 | 8 | ヴァンフォーレ甲府ヴァンフォーレ甲府 | 64 | 42 | 18 | 10 | 14 | 60 | 50 | 10 |
| J2 | 9 | 大分トリニータ大分トリニータ | 62 | 42 | 17 | 11 | 14 | 54 | 56 | -2 |
| J2 | 10 | ファジアーノ岡山ファジアーノ岡山 | 58 | 42 | 13 | 19 | 10 | 49 | 49 | 0 |
| J2 | 11 | ザスパクサツ群馬ザスパクサツ群馬 | 57 | 42 | 14 | 15 | 13 | 44 | 44 | 0 |
| J2 | 12 | 藤枝MYFC藤枝MYFC | 52 | 42 | 14 | 10 | 18 | 61 | 72 | -11 |
| J2 | 13 | ブラウブリッツ秋田ブラウブリッツ秋田 | 51 | 42 | 12 | 15 | 15 | 37 | 44 | -7 |
| J2 | 14 | ロアッソ熊本ロアッソ熊本 | 49 | 42 | 13 | 10 | 19 | 52 | 53 | -1 |
| J2 | 15 | 徳島ヴォルティス徳島ヴォルティス | 49 | 42 | 10 | 19 | 13 | 43 | 53 | -10 |
| J2 | 16 | ベガルタ仙台ベガルタ仙台 | 48 | 42 | 12 | 12 | 18 | 48 | 61 | -13 |
| J2 | 17 | 水戸ホーリーホック水戸ホーリーホック | 47 | 42 | 11 | 14 | 17 | 49 | 66 | -17 |
| J2 | 18 | いわきFCいわきFC | 47 | 42 | 12 | 11 | 19 | 45 | 69 | -24 |
| J2 | 19 | 栃木SC栃木SC | 44 | 42 | 10 | 14 | 18 | 39 | 47 | -8 |
| J2 | 20 | レノファ山口FCレノファ山口FC | 44 | 42 | 10 | 14 | 18 | 37 | 67 | -30 |
| J2 | 21 | 大宮アルディージャ大宮アルディージャ | 39 | 42 | 11 | 6 | 25 | 37 | 71 | -34 |
| J2 | 22 | ツエーゲン金沢ツエーゲン金沢 | 35 | 42 | 9 | 8 | 25 | 41 | 70 | -29 |
| J3 | 1 | 愛媛FC愛媛FC | 73 | 38 | 21 | 10 | 7 | 59 | 48 | 11 |
| J3 | 2 | 鹿児島ユナイテッドFC鹿児島ユナイテッドFC | 62 | 38 | 18 | 8 | 12 | 58 | 41 | 17 |
| J3 | 3 | カターレ富山カターレ富山 | 62 | 38 | 19 | 5 | 14 | 59 | 48 | 11 |
| J3 | 4 | FC今治FC今治 | 59 | 38 | 16 | 11 | 11 | 54 | 42 | 12 |
| J3 | 5 | 奈良クラブ奈良クラブ | 57 | 38 | 15 | 12 | 11 | 45 | 32 | 13 |
| J3 | 6 | ガイナーレ鳥取ガイナーレ鳥取 | 56 | 38 | 14 | 14 | 10 | 57 | 52 | 5 |
| J3 | 7 | ヴァンラーレ八戸ヴァンラーレ八戸 | 56 | 38 | 15 | 11 | 12 | 49 | 47 | 2 |
| J3 | 8 | FC岐阜FC岐阜 | 54 | 38 | 14 | 12 | 12 | 44 | 35 | 9 |
| J3 | 9 | 松本山雅FC松本山雅FC | 54 | 38 | 15 | 9 | 14 | 51 | 47 | 4 |
| J3 | 10 | いわてグルージャ盛岡いわてグルージャ盛岡 | 54 | 38 | 15 | 9 | 14 | 48 | 49 | -1 |
| J3 | 11 | FC大阪FC大阪 | 53 | 38 | 14 | 11 | 13 | 41 | 38 | 3 |
| J3 | 12 | Y.S.C.C.横浜Y.S.C.C.横浜 | 52 | 38 | 14 | 10 | 14 | 48 | 50 | -2 |
| J3 | 13 | アスルクラロ沼津アスルクラロ沼津 | 51 | 38 | 15 | 6 | 17 | 48 | 48 | 0 |
| J3 | 14 | AC長野パルセイロAC長野パルセイロ | 50 | 38 | 13 | 11 | 14 | 52 | 60 | -8 |
| J3 | 15 | 福島ユナイテッドFC福島ユナイテッドFC | 47 | 38 | 12 | 11 | 15 | 37 | 42 | -5 |
| J3 | 16 | カマタマーレ讃岐カマタマーレ讃岐 | 44 | 38 | 11 | 11 | 16 | 29 | 45 | -16 |
| J3 | 17 | FC琉球FC琉球 | 43 | 38 | 12 | 7 | 19 | 43 | 61 | -18 |
| J3 | 18 | SC相模原SC相模原 | 41 | 38 | 9 | 14 | 15 | 44 | 48 | -4 |
| J3 | 19 | テゲバジャーロ宮崎テゲバジャーロ宮崎 | 39 | 38 | 9 | 12 | 17 | 31 | 52 | -21 |
| J3 | 20 | ギラヴァンツ北九州ギラヴァンツ北九州 | 31 | 38 | 7 | 10 | 21 | 33 | 45 | -12 |
クラブ名が「FC矢内FC矢内」のようになっていることが分かる。元のページを見ると、チームのエンブレムが表示されるが、これらの画像には代替テキスト(alt)が付与されており、スクレイピングのように画像が読み込めない場合は、その代替テキストが取得されるのが原因である。
解決方法はいくつかあるが、ここでは事後的な解決方法を採用する。具体的にはクラブ名列内の文字列を半分だけ残せば良い。たとえば、「FC矢内FC矢内」は8文字であるため、1番目の文字から8文字の半分である4文字まで残す。文字列から一部を取り出す関数はstr_sub()であり、str_sub(文字列, スタート位置, 終了位置)を指定する。スタート位置は1固定であり、終了位置は文字列の長さ(nchar(文字列))の半分だからnchar(文字列) / 2で良い。
処理が終わったら、リーグ列でグルーピングして表として出力する。
| 順位 | クラブ名 | 勝点 | 試合数 | 勝 | 分 | 負 | 得点 | 失点 | 得失点 |
|---|---|---|---|---|---|---|---|---|---|
| J1 | |||||||||
| 1 | ヴィッセル神戸 | 71 | 34 | 21 | 8 | 5 | 60 | 29 | 31 |
| 2 | 横浜F・マリノス | 64 | 34 | 19 | 7 | 8 | 63 | 40 | 23 |
| 3 | サンフレッチェ広島 | 58 | 34 | 17 | 7 | 10 | 42 | 28 | 14 |
| 4 | 浦和レッズ | 57 | 34 | 15 | 12 | 7 | 42 | 27 | 15 |
| 5 | 鹿島アントラーズ | 52 | 34 | 14 | 10 | 10 | 43 | 34 | 9 |
| 6 | 名古屋グランパス | 52 | 34 | 14 | 10 | 10 | 41 | 36 | 5 |
| 7 | アビスパ福岡 | 51 | 34 | 15 | 6 | 13 | 37 | 43 | -6 |
| 8 | 川崎フロンターレ | 50 | 34 | 14 | 8 | 12 | 51 | 45 | 6 |
| 9 | セレッソ大阪 | 49 | 34 | 15 | 4 | 15 | 39 | 34 | 5 |
| 10 | アルビレックス新潟 | 45 | 34 | 11 | 12 | 11 | 36 | 40 | -4 |
| 11 | FC東京 | 43 | 34 | 12 | 7 | 15 | 42 | 46 | -4 |
| 12 | 北海道コンサドーレ札幌 | 40 | 34 | 10 | 10 | 14 | 56 | 61 | -5 |
| 13 | 京都サンガF.C. | 40 | 34 | 12 | 4 | 18 | 40 | 45 | -5 |
| 14 | サガン鳥栖 | 38 | 34 | 9 | 11 | 14 | 43 | 47 | -4 |
| 15 | 湘南ベルマーレ | 34 | 34 | 8 | 10 | 16 | 40 | 56 | -16 |
| 16 | ガンバ大阪 | 34 | 34 | 9 | 7 | 18 | 38 | 61 | -23 |
| 17 | 柏レイソル | 33 | 34 | 6 | 15 | 13 | 33 | 47 | -14 |
| 18 | 横浜FC | 29 | 34 | 7 | 8 | 19 | 31 | 58 | -27 |
| J2 | |||||||||
| 1 | FC町田ゼルビア | 87 | 42 | 26 | 9 | 7 | 79 | 35 | 44 |
| 2 | ジュビロ磐田 | 75 | 42 | 21 | 12 | 9 | 74 | 44 | 30 |
| 3 | 東京ヴェルディ | 75 | 42 | 21 | 12 | 9 | 57 | 31 | 26 |
| 4 | 清水エスパルス | 74 | 42 | 20 | 14 | 8 | 78 | 34 | 44 |
| 5 | モンテディオ山形 | 67 | 42 | 21 | 4 | 17 | 64 | 54 | 10 |
| 6 | ジェフユナイテッド千葉 | 67 | 42 | 19 | 10 | 13 | 61 | 53 | 8 |
| 7 | V・ファーレン長崎 | 65 | 42 | 18 | 11 | 13 | 70 | 56 | 14 |
| 8 | ヴァンフォーレ甲府 | 64 | 42 | 18 | 10 | 14 | 60 | 50 | 10 |
| 9 | 大分トリニータ | 62 | 42 | 17 | 11 | 14 | 54 | 56 | -2 |
| 10 | ファジアーノ岡山 | 58 | 42 | 13 | 19 | 10 | 49 | 49 | 0 |
| 11 | ザスパクサツ群馬 | 57 | 42 | 14 | 15 | 13 | 44 | 44 | 0 |
| 12 | 藤枝MYFC | 52 | 42 | 14 | 10 | 18 | 61 | 72 | -11 |
| 13 | ブラウブリッツ秋田 | 51 | 42 | 12 | 15 | 15 | 37 | 44 | -7 |
| 14 | ロアッソ熊本 | 49 | 42 | 13 | 10 | 19 | 52 | 53 | -1 |
| 15 | 徳島ヴォルティス | 49 | 42 | 10 | 19 | 13 | 43 | 53 | -10 |
| 16 | ベガルタ仙台 | 48 | 42 | 12 | 12 | 18 | 48 | 61 | -13 |
| 17 | 水戸ホーリーホック | 47 | 42 | 11 | 14 | 17 | 49 | 66 | -17 |
| 18 | いわきFC | 47 | 42 | 12 | 11 | 19 | 45 | 69 | -24 |
| 19 | 栃木SC | 44 | 42 | 10 | 14 | 18 | 39 | 47 | -8 |
| 20 | レノファ山口FC | 44 | 42 | 10 | 14 | 18 | 37 | 67 | -30 |
| 21 | 大宮アルディージャ | 39 | 42 | 11 | 6 | 25 | 37 | 71 | -34 |
| 22 | ツエーゲン金沢 | 35 | 42 | 9 | 8 | 25 | 41 | 70 | -29 |
| J3 | |||||||||
| 1 | 愛媛FC | 73 | 38 | 21 | 10 | 7 | 59 | 48 | 11 |
| 2 | 鹿児島ユナイテッドFC | 62 | 38 | 18 | 8 | 12 | 58 | 41 | 17 |
| 3 | カターレ富山 | 62 | 38 | 19 | 5 | 14 | 59 | 48 | 11 |
| 4 | FC今治 | 59 | 38 | 16 | 11 | 11 | 54 | 42 | 12 |
| 5 | 奈良クラブ | 57 | 38 | 15 | 12 | 11 | 45 | 32 | 13 |
| 6 | ガイナーレ鳥取 | 56 | 38 | 14 | 14 | 10 | 57 | 52 | 5 |
| 7 | ヴァンラーレ八戸 | 56 | 38 | 15 | 11 | 12 | 49 | 47 | 2 |
| 8 | FC岐阜 | 54 | 38 | 14 | 12 | 12 | 44 | 35 | 9 |
| 9 | 松本山雅FC | 54 | 38 | 15 | 9 | 14 | 51 | 47 | 4 |
| 10 | いわてグルージャ盛岡 | 54 | 38 | 15 | 9 | 14 | 48 | 49 | -1 |
| 11 | FC大阪 | 53 | 38 | 14 | 11 | 13 | 41 | 38 | 3 |
| 12 | Y.S.C.C.横浜 | 52 | 38 | 14 | 10 | 14 | 48 | 50 | -2 |
| 13 | アスルクラロ沼津 | 51 | 38 | 15 | 6 | 17 | 48 | 48 | 0 |
| 14 | AC長野パルセイロ | 50 | 38 | 13 | 11 | 14 | 52 | 60 | -8 |
| 15 | 福島ユナイテッドFC | 47 | 38 | 12 | 11 | 15 | 37 | 42 | -5 |
| 16 | カマタマーレ讃岐 | 44 | 38 | 11 | 11 | 16 | 29 | 45 | -16 |
| 17 | FC琉球 | 43 | 38 | 12 | 7 | 19 | 43 | 61 | -18 |
| 18 | SC相模原 | 41 | 38 | 9 | 14 | 15 | 44 | 48 | -4 |
| 19 | テゲバジャーロ宮崎 | 39 | 38 | 9 | 12 | 17 | 31 | 52 | -21 |
| 20 | ギラヴァンツ北九州 | 31 | 38 | 7 | 10 | 21 | 33 | 45 | -12 |
32.3.4 表以外の内容
続いて、表のように見えて表ではないものをスクレイピングしてみよう。OpenCriticというゲームの口コミサイトから2021年発売されたPCゲームのランキングを取得してみよう。対象ページは以下のURLだ。
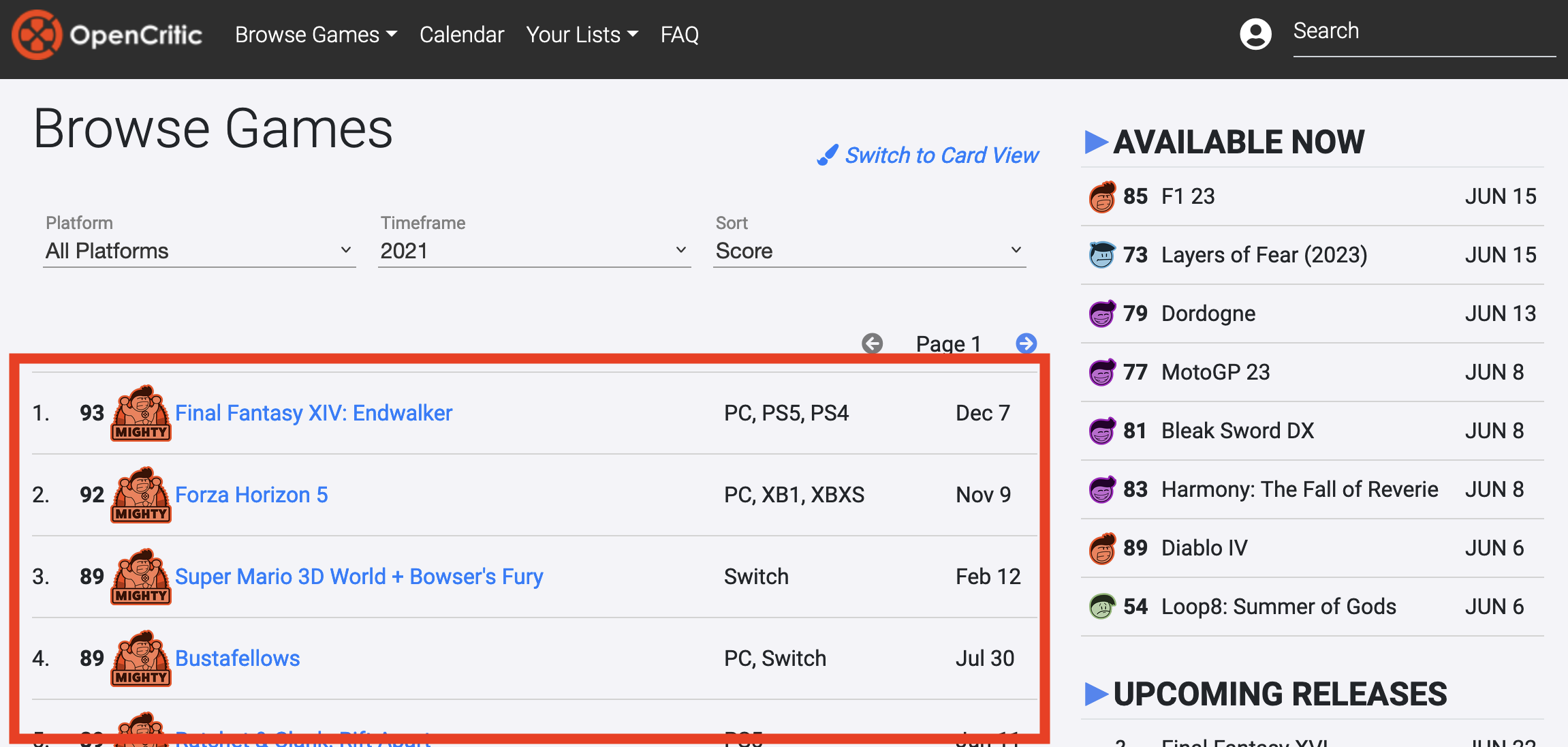
ここには上位20位までのゲームのリストがあり、20行86列9の表のように見える。まず、このページを読み込んだものをoc_htmlに格納する。
{html_document}
<html lang="en">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
[2] <body>\n<script type="text/javascript">\n if (document && document.cooki ... 続いてoc_htmlからhtml_table()を使用し、表を抽出してみよう。
どうみても表があるように見えるものの、html_table()から表は抽出されていない。実はこのページの順位表、<table>タグで記述された表ではない。100個以上の<div>要素を表のように並べたものである。開発者メニューからこの表のようなもののコードを確認してみよう。
<div _ngcontent-serverapp-c79="" class="desktop-game-display">
<div _ngcontent-serverapp-c79="">
<div _ngcontent-serverapp-c79="" class="row no-gutters py-2 game-row align-items-center">
<div _ngcontent-serverapp-c79="" class="rank"> 1. </div>
<div _ngcontent-serverapp-c79="" class="score col-auto"> 93 </div>
<div _ngcontent-serverapp-c79="" class="tier col-auto"><app-tier-display _ngcontent-serverapp-c79="" display="man" _nghost-serverapp-c65=""><img _ngcontent-serverapp-c65="" src="//img.opencritic.com/mighty-man/mighty-man.png" alt="Mighty" width="45" height="42"></app-tier-display></div>
<div _ngcontent-serverapp-c79="" class="game-name col"><a _ngcontent-serverapp-c79="" href="/game/11626/final-fantasy-xiv-endwalker">Final Fantasy XIV: Endwalker</a></div>
<div _ngcontent-serverapp-c79="" class="platforms col-auto"> PC, PS5, PS4 </div>
<div _ngcontent-serverapp-c79="" class="first-release-date col-auto"><span _ngcontent-serverapp-c79="">Dec 7</span></div>
</div>
<div _ngcontent-serverapp-c79="" class="row no-gutters py-2 game-row align-items-center">
<div _ngcontent-serverapp-c79="" class="rank"> 2. </div>
<div _ngcontent-serverapp-c79="" class="score col-auto"> 92 </div>
... 数百の<div>タグが入れ子構造でなっていることが分かる。この<div>タグそのものに特別な機能はない。<span>が文中の文章に対してクラスやIDを割り当てるために使われるということは既に説明したが、<div>もほぼ同じ役割をする。違いがあれば、<span>は文中の文章が対象であり、<div>は領域が対象とすることだ。この構造を実際のページに対応すると以下のようになる。
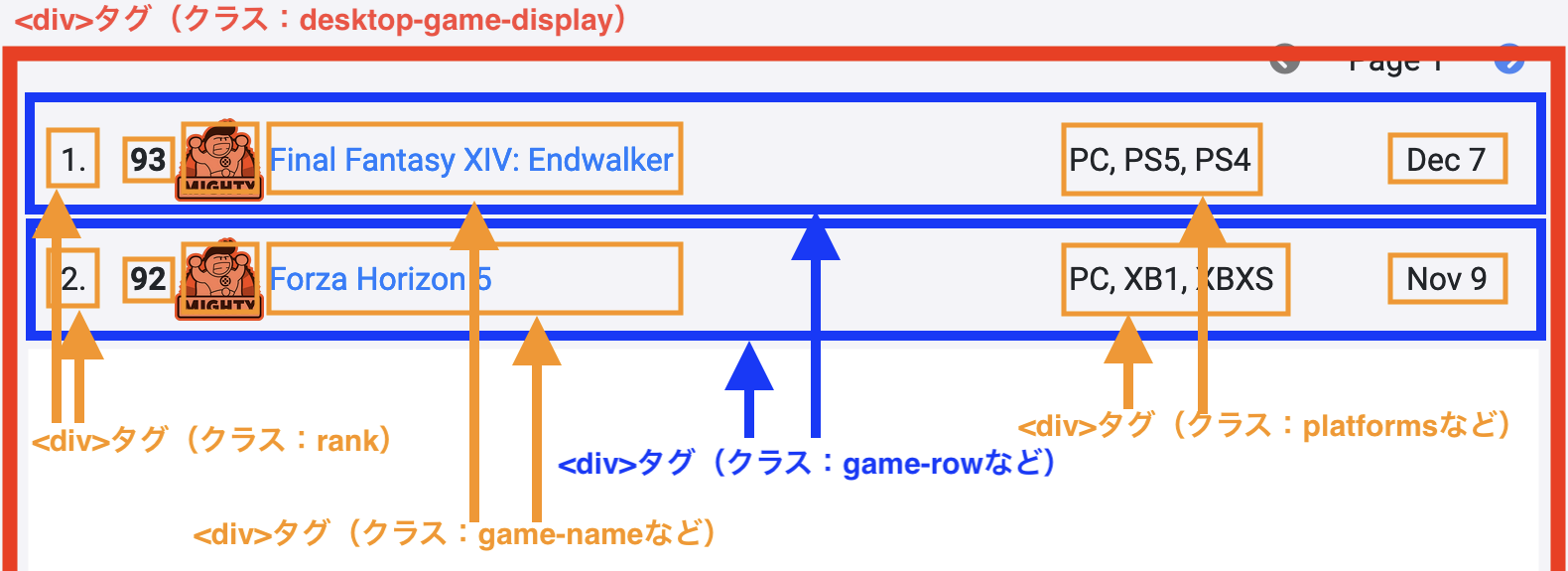
まず、この順位表全体はクラス名がdesktop-game-displayの<div>タグに囲まれている。この中に、各行はrow、no-gutters、py-2、game-row、align-items-center計5つのクラスを持つ<div>タグで囲まれている。そしてこの中に順位(クラス名:rank)やスコア(クラス名:score、col-auto)、ティア(クラス名:tier、col-auto)の<div>があり、それぞれのセルを構成している。
ここからランクを取り出してみよう。まずはクラスがdesktop-game-displayである<div>タグに限定するために、html_element("div.desktop-game-display")で当該<div>のみを残し、oc_htmlを上書きする。このようにクラス名とタグを同時に指定する場合のセレクターはタグ名.クラス名と表記する。
{html_node}
<div _ngcontent-sc166="" class="desktop-game-display">
[1] <div _ngcontent-sc166="">\n<div _ngcontent-sc166="" class="row no-gutters ... 続いて、oc_htmlからクラス名がrankの<div>タグを抽出する。今回は抽出対象が20個あるため、html_element()でなく、html_elements()を使用する。
{xml_nodeset (20)}
[1] <div _ngcontent-sc166="" class="rank"> 1. </div>\n
[2] <div _ngcontent-sc166="" class="rank"> 2. </div>\n
[3] <div _ngcontent-sc166="" class="rank"> 3. </div>\n
[4] <div _ngcontent-sc166="" class="rank"> 4. </div>\n
[5] <div _ngcontent-sc166="" class="rank"> 5. </div>\n
[6] <div _ngcontent-sc166="" class="rank"> 6. </div>\n
[7] <div _ngcontent-sc166="" class="rank"> 7. </div>\n
[8] <div _ngcontent-sc166="" class="rank"> 8. </div>\n
[9] <div _ngcontent-sc166="" class="rank"> 9. </div>\n
[10] <div _ngcontent-sc166="" class="rank"> 10. </div>\n
[11] <div _ngcontent-sc166="" class="rank"> 11. </div>\n
[12] <div _ngcontent-sc166="" class="rank"> 12. </div>\n
[13] <div _ngcontent-sc166="" class="rank"> 13. </div>\n
[14] <div _ngcontent-sc166="" class="rank"> 14. </div>\n
[15] <div _ngcontent-sc166="" class="rank"> 15. </div>\n
[16] <div _ngcontent-sc166="" class="rank"> 16. </div>\n
[17] <div _ngcontent-sc166="" class="rank"> 17. </div>\n
[18] <div _ngcontent-sc166="" class="rank"> 18. </div>\n
[19] <div _ngcontent-sc166="" class="rank"> 19. </div>\n
[20] <div _ngcontent-sc166="" class="rank"> 20. </div>\n さらにここからhtml_text()を使用してテキストのみ抽出してみよう。
[1] " 1. " " 2. " " 3. " " 4. " " 5. " " 6. " " 7. " " 8. " " 9. "
[10] " 10. " " 11. " " 12. " " 13. " " 14. " " 15. " " 16. " " 17. " " 18. "
[19] " 19. " " 20. " 前後の空白が気になる。この場合、html_text2()を使うと無駄な空白や改行、タブなどを除去することができる。
[1] "1." "2." "3." "4." "5." "6." "7." "8." "9." "10." "11." "12."
[13] "13." "14." "15." "16." "17." "18." "19." "20." これでランキングの抽出ができた。まだ数字の後に付いている点が気になるが、こちらは後ほどまとめて除去しよう。つづいて、ティアーの画像URLを取得してみよう。既にクラスがdesktop-game-displayである<div>タグに限定されたoc_htmlからクラス名がtierの<div>を選択し、さらにそこから<img>タグを抽出し、画像のURLが指定されている"src"属性を抽出してみよう。
20個の画像が抽出された。URLなのに"//"で始まるのが不自然だと感じるかも知れないが、これはpaste0()やstr_replace()などを使用し、"//"を"https://"やhttp://に修正すれば良い。あとはこれらの作業を他のセル(ゲーム名、スコアなど)にも適用し、一つの表としてまとめるだけだ。oc_dfという名のオブジェクトとして格納しよう。
oc_df <- tibble(Rank = html_elements(oc_html, "div.rank") |>
html_text2(),
Score = html_elements(oc_html, "div.score") |>
html_text2(),
Name = html_elements(oc_html, "div.game-name") |>
html_text2(),
Platforms = html_elements(oc_html, "div.platforms") |>
html_text2(),
Date = html_elements(oc_html, "div.first-release-date") |>
html_text2())
oc_df# A tibble: 20 × 5
Rank Score Name Platforms Date
<chr> <chr> <chr> <chr> <chr>
1 1. 93 Final Fantasy XIV: Endwalker PC, PS5, PS4 Dec 7
2 2. 92 Forza Horizon 5 PC, XB1, XBXS Nov 9
3 3. 89 Super Mario 3D World + Bowser's Fury Switch Feb …
4 4. 89 Bustafellows PC, Switch Jul …
5 5. 89 Swarm Quest Apr 8
6 6. 89 Psychonauts 2 PC, XB1, XBXS, PS4 Aug …
7 7. 88 Ratchet & Clank: Rift Apart PS5, PC Jun …
8 8. 88 Death's Door XB1, PC, XBXS, PS4, P… Jul …
9 9. 88 Overboard! Switch, PC Jun 2
10 10. 88 Vampire Survivors PC, Switch, PS4, PS5,… Dec …
11 11. 88 Chicory: A Colorful Tale PS5, PS4, PC, Switch,… Jun …
12 12. 88 Deathloop PS5, PC, XBXS Sep …
13 13. 88 It Takes Two PC, XB1, PS5, XBXS, P… Mar …
14 14. 88 Moving Out: Movers in Paradise PC, PS4, XB1, Switch Feb …
15 15. 87 Monster Hunter Rise Switch, PC, PS5, PS4,… Mar …
16 16. 87 Metroid Dread Switch Oct 8
17 17. 87 Mass Effect Legendary Edition PS4, PC, XBXS, PS5, X… May …
18 18. 87 Tales of Arise PS5, PC, XBXS, XB1, P… Sep …
19 19. 87 Quake XBXS, PS5, XB1, PS4, … Aug …
20 20. 87 Ghost of Tsushima Director's Cut PS5, PS4, PC Aug … 後はこの表の細かいところを修正しよう。たとえば、Rank列から"."を除去し、numeric型に変換したり、Date列をdate型に変換する。
- 1
-
Rank列から.を除去する。 - 2
-
Rank列をnumeric型に変換する。 - 3
-
Score列をnumeric型に変換する。 - 4
-
Date列の後に", 2021"を付ける。 - 5
-
Date列がmonth-day-yearで記述されていることを伝え、date型に変換する。
# A tibble: 20 × 5
Rank Score Name Platforms Date
<dbl> <dbl> <chr> <chr> <date>
1 1 93 Final Fantasy XIV: Endwalker PC, PS5, PS4 2021-12-07
2 2 92 Forza Horizon 5 PC, XB1, XBXS 2021-11-09
3 3 89 Super Mario 3D World + Bowser's Fury Switch 2021-02-12
4 4 89 Bustafellows PC, Switch 2021-07-30
5 5 89 Swarm Quest 2021-04-08
6 6 89 Psychonauts 2 PC, XB1, XBXS, P… 2021-08-25
7 7 88 Ratchet & Clank: Rift Apart PS5, PC 2021-06-11
8 8 88 Death's Door XB1, PC, XBXS, P… 2021-07-20
9 9 88 Overboard! Switch, PC 2021-06-02
10 10 88 Vampire Survivors PC, Switch, PS4,… 2021-12-17
11 11 88 Chicory: A Colorful Tale PS5, PS4, PC, Sw… 2021-06-10
12 12 88 Deathloop PS5, PC, XBXS 2021-09-14
13 13 88 It Takes Two PC, XB1, PS5, XB… 2021-03-26
14 14 88 Moving Out: Movers in Paradise PC, PS4, XB1, Sw… 2021-02-25
15 15 87 Monster Hunter Rise Switch, PC, PS5,… 2021-03-26
16 16 87 Metroid Dread Switch 2021-10-08
17 17 87 Mass Effect Legendary Edition PS4, PC, XBXS, P… 2021-05-14
18 18 87 Tales of Arise PS5, PC, XBXS, X… 2021-09-10
19 19 87 Quake XBXS, PS5, XB1, … 2021-08-19
20 20 87 Ghost of Tsushima Director's Cut PS5, PS4, PC 2021-08-20 最後にoc_dfを{gt}パッケージを使って表として出力してみよう。
| Rank | Score | Name | Platforms | First release date |
|---|---|---|---|---|
| 1 | 93 | Final Fantasy XIV: Endwalker | PC, PS5, PS4 | 2021-12-07 |
| 2 | 92 | Forza Horizon 5 | PC, XB1, XBXS | 2021-11-09 |
| 3 | 89 | Super Mario 3D World + Bowser's Fury | Switch | 2021-02-12 |
| 4 | 89 | Bustafellows | PC, Switch | 2021-07-30 |
| 5 | 89 | Swarm | Quest | 2021-04-08 |
| 6 | 89 | Psychonauts 2 | PC, XB1, XBXS, PS4 | 2021-08-25 |
| 7 | 88 | Ratchet & Clank: Rift Apart | PS5, PC | 2021-06-11 |
| 8 | 88 | Death's Door | XB1, PC, XBXS, PS4, PS5, Switch | 2021-07-20 |
| 9 | 88 | Overboard! | Switch, PC | 2021-06-02 |
| 10 | 88 | Vampire Survivors | PC, Switch, PS4, PS5, XB1, XBXS | 2021-12-17 |
| 11 | 88 | Chicory: A Colorful Tale | PS5, PS4, PC, Switch, XB1, XBXS | 2021-06-10 |
| 12 | 88 | Deathloop | PS5, PC, XBXS | 2021-09-14 |
| 13 | 88 | It Takes Two | PC, XB1, PS5, XBXS, PS4, Switch | 2021-03-26 |
| 14 | 88 | Moving Out: Movers in Paradise | PC, PS4, XB1, Switch | 2021-02-25 |
| 15 | 87 | Monster Hunter Rise | Switch, PC, PS5, PS4, XBXS, XB1 | 2021-03-26 |
| 16 | 87 | Metroid Dread | Switch | 2021-10-08 |
| 17 | 87 | Mass Effect Legendary Edition | PS4, PC, XBXS, PS5, XB1 | 2021-05-14 |
| 18 | 87 | Tales of Arise | PS5, PC, XBXS, XB1, PS4 | 2021-09-10 |
| 19 | 87 | Quake | XBXS, PS5, XB1, PS4, Switch, PC | 2021-08-19 |
| 20 | 87 | Ghost of Tsushima Director's Cut | PS5, PS4, PC | 2021-08-20 |
32.4 スクレイピングの注意事項
スクレイピングの対象は自分が作成したページでなく、自分以外の個人(有志)、集団、機関などが作成したページであろう。そしてそのページ内にはその個人、集団、機関などが収集、作成、整理した資料とデータが含まれる。したがって、スクレイピングをする前に著作権を気にする必要があろう。もし、利用規約(「Terms and conditions」や「Terms of service」など)がある場合は予め読んでおこう。スクレイピングは禁止されている可能性もある。非商業的利用(教育・研究を含む)や個人利用の場合、利用が許されるケースもあるが、筆者らは弁護士でもなく、著作権に関する知識が皆無であるため、断言はできない。また、これらの法律は国によっても異なる。スクレイピングして良いかどうかが不安な場合は、そのページを作成した個人、集団、機関などに問い合わせてみるのが確実だろう。
また、サイトによっては「ここは取得しちゃダメ」というのがある可能性もある。全てのサイトに置いてあるわけではないが、多くのサイトにはrobots.txtというファイルが置かれている10。これはウェブ・クローラー(web crawler)と呼ばれる一種のボット(Bot)向けに書かれたものであるが、スクレイピング時にも参考になろう。たとえば、OpenCriticの場合、https://opencritic.com/robots.txtにrobots.txtがある。以下はその中身だ。
https://opencritic.com/robots.txt
User-agent: *は「以下の内容はすべてのクローラー(*)に該当する」ことを意味し、Disallow: /profileは「profileページは取得してはいけない」ことを意味する(もし/profile/になっている場合は、profileとその以下のフォルダー全体を意味する)。ちなみにDisallow: /となっている場合は、サイト全体がクローリング禁止を意味する。Disallowとは逆のAllowもあり、AllowがDisallowに優先する。また、Sitemapは当該サイトのサイトマップ(ページ等の全体構造が記述されているファイル)のURLだ。以下のrobots.txtはGoogleのもの(の一部)であり、ボットの種類に応じて許可範囲が異なるケースもある。
https://www.google.com/robots.txt
# AdsBot
User-agent: AdsBot-Google
Disallow: /maps/api/js/
Allow: /maps/api/js
Disallow: /maps/api/place/js/
Disallow: /maps/api/staticmap
Disallow: /maps/api/streetview
# Crawlers of certain social media sites are allowed to access page markup when google.com/imgres* links are shared. To learn more, please contact images-robots-allowlist@google.com.
User-agent: Twitterbot
Allow: /imgres
Allow: /search
Disallow: /groups
Disallow: /hosted/images/
Disallow: /m/
User-agent: facebookexternalhit
Allow: /imgres
Allow: /search
Disallow: /groups
Disallow: /hosted/images/
Disallow: /m/
Sitemap: https://www.google.com/sitemap.xml robots.txtに関するネット記事も多いが、筆者(宋)はGoogleのページをおすすめする。
そしてもう一つ重要なのは、サーバーに負担をかけないことだ。今回の例は1ページのみ、Jリーグの順位表の場合は3ページのスクレイピングであったため、サーバーへの負担はほぼないと考えられる。しかし、数百〜数千のページをスクレイピングをするケースも珍しくもない。むしろ、スクレイピングの醍醐味はそこにあろう。しかし、パソコンの動きは我々の想像をはるかに凌駕する。場合によっては1秒に数回、当該サーバーへのアクセスを試みるかも知れない。集団で特定のページをリフレッシュし続けると、サーバーへの負担が増加し、結果としてサーバーが止まることは聞いたことがあるかも知れない。何も考えずに大量のスクレイピングをすることは、そのサーバーに対し、分散型サービス妨害攻撃(DDoS攻撃)を行っていることと同じだ。したがって、ループ時にSys.sleep()などを使って(時間的)間隔を空けたり、{polite}パッケージを使ってサーバーへの負担を緩和したりすることも考える必要がある。また、サーバーごとに1日に許容されるトラフィックにも限度があるため、大量のデータであれば、数日に分けてスクレイピングすることも一つの方法だろう。
スクレイピングをする時にはそのデータを作成した人や機関に敬意を払う必要があろう。
通常、タグはカッコのように開いたら(
<タグ名>)閉じる(</タグ名>)必要がある。しかし、タグの中には閉じる必要のないものもある。たとえば、改行を意味するタグとして<br>があるが、これは<br>、または<br/>のみで良い。↩︎属性セレクターはいくつかのバリエーションがある。たとえば、
a[href$=".net"]はhrefの値が".net"で終わる<a>タグ、a[href^="www"]はhrefの値が"www"で始まる<a>タグ、a[href~="jaysong"]はhrefの値に"jaysong"が含まれていない<a>タグ、a[href*="rbook"]はhrefの値に"rbook"が含まれている<a>タグを意味する。↩︎もっと深く入ると、セレクターの親子関係など様々な書き方がある。↩︎
似たような名前の
html_element()がある。ほぼ同じものであるが、html_element()は1ページ内に当該セレクターが複数回ある場合、最初のものだけを抽出する。一方、html_elements()はすべての要素を抽出する。↩︎似たような関数として
html_text2()があるが、これは前後の不要なスペースやタブ、改行などを除外した上でテキストを取得する関数だ。↩︎似たようなものとして
<div>がある。<span>は主に文章の一部(=インライン; inline)に対して使用することで当該箇所にクラスやIDを割り当てる。一方、<div>は領域に対してクラスやIDを割り当てる際に使用する。↩︎今回の場合、
"ul > li > ul > li"のような書き方もできる。空白で区切る方法を子孫結合子(descendant combinator)、>で区切る方法を子結合子(child combinator)と呼ぶ。タグの構造が<a><b><c></c></b></a>の構造になっている場合、<c>タグを指定するケースを考えてみよう。子孫結合子だと"a c"のように表記することができるが、<a>が持つ全ての子孫から<c>タグを探索することになる。つまり、<a>の子だけでなく、孫、曾孫(やそれ以上)までも探索の対象となる。一方、子結合子は自分の子のみ探索することになるため、"a > b > c"のように孫を指定するためには、まずは自分の子を経由する必要がある。↩︎20ゲーム↩︎
順位、スコア、ティア(Tier)の画像、ゲーム名、機種、発売日↩︎
宋の個人ホームページにも
robots.txtは置かれているが、サイトマップ情報のみとなっている。↩︎