[1] 1512 関数の自作
12.1 関数の作成
これまでclass()や、sum()、print()など、様々な関数 (functions) を使ってきた。「Rで起こるあらゆることは関数の呼び出しである (Everything that happens in R is a function call)」(Chambers 2016) と言われるように、「Rを使う」ということは、「Rの関数を使う」ということである。
関数は関数名() ように括弧とセットで表記されることが多い。1つの関数でも、括弧の中に異なる引数を指定することで、さまざまな結果を出すことができる。例として、第7章でも説明したseq()関数について考えてみよう。この関数を使うと、一連の数字からなるベクトルを作ることができる。from で数列の初項を、to で数列の最終項を指定し、by で要素間の差(第2要素は第1要素に by を加えた値になる )を指定するか、length.out で最終的にできるベクトルの要素の数を指定する。
Rを含むプログラミングにおける関数は、何かを入力すると何かを出力する箱のようなものである。関数を使うだけなら、関数という箱の中で何が起こっているかを理解する必要はない。例えば、mean() という関数に実数のベクトルを入力すると、平均値を実数として返すということを知っていれば、mean() が具体的にどのような計算を行っているかを知らなくても、実用上は問題ない。つまり、関数をブラックボックスとして扱うことができる。
このように1つの関数でも指定する内容は、by になったりlength.out になったりする。by や length.out、from、to などのように、関数で指定する対象になっているもののことを 仮引数 (parameter) と呼ぶ。また、by = 1 の1や、length.out = 10 の10のように、仮引数に実際に渡される値のことを実引数 (argument) と呼ぶ。特に誤解が生じないと思われる場合には、仮引数と実引数を区別せずに引数(ひきすう)と呼ぶ。 Rでは、1つの関数で使う引数の数が複数あることが多いので、仮引数を明示する習慣を身につけたほうがよい。 ただし、第1引数(関数で最初に指定する引数)として必ず入力すべきものは決められている場合がほとんどなので、第1引数の仮引数は省略されることが多い。仮引数が省略される代わりに、第1引数の実引数はほぼ必ず入力する(いくつかの例外もある)。
関数とは()内の引数のデータを関数内部の手続きに沿って処理し、その結果を返すものです。あるデータを引数として受け付ける関数であれば、その引数を変えるだけで「先ほどとは異なるデータに対し、同じ処理を行う」ことが可能となり、コーディングの労力が省けます。
ここでは、ベクトルc(1, 2, 3, 4, 5)の総和を計算する方法について考えてみましょう。まず、1つ目は単純に足し算をする方法があります。
他にも反復処理を使うことも可能です。とりわけ、1:100のようなベクトルを1つ目の方法で記述するのは時間の無駄でしょう。for()文を使った方法は以下のようになります。
数個の数字を足すだけなら方法1の方が楽でしょうし、数百個の数字の場合は方法2の方が効率的です。それでもやはりsum()関数の方が数倍は効率的です。また、関数を使うことで、スクリプトの量をへらすこともできます。1から100までの総和なら、方法2のfor (i in 1:5)をfor (i in 1:100)に変えることで対応可能ですが、それでも全体としては数行のコードで書かなくてもなりません。一方、sum(1:100)なら一行で済みます。
sum()はまだマシな方です。たとえば、回帰分析をしたい場合、毎回回帰分析のコードを一から書くのはあまりにも非効率的です。lm()関数を使うと、データや回帰式などを指定するだけで、一連の作業を全て自動的に行い、その結果を返してくれます。中には回帰式の係数も計算してくれますが、他にも残差や決定係数なども計算してくれます。その意味で、lm()という関数は複数の機能を一つの関数としてまとめたものでもあります。
これらの関数は既にR開発チームが書いた関数ですが、ユーザー側から関数を作成することも可能です。長いコードを書く、同じ作業を繰り返す場合、関数の作成はほぼ必須とも言えます。ここではまず、簡単な関数を作成してみましょう。与えられた数字を二乗し、その結果を返すmyPower()関数を作ってみましょう。
それではコードを解説します。関数は以下のように定義されます。
まず、関数名をmyPowerとし、それが関数であることを宣言します。そして、この関数の引数の名前はxとします。それが
の部分です。続いて、{}内に処理内容を書きます。今回はx^2であり、これはxの2乗を意味します。そして、関数の処理結果が返されますが、{}内の最後の行が結果として返されます。x^2の部分はreturn(x^2)と書き換えることも可能です。return()は「この結果を返せよ」という意味の関数ですが、返す結果が最後の行である場合、省略可能であり、Hadely先生もこのような書き方を推奨しています。
それでは、もうちょっと複雑な関数を作成してみましょう。ベクトルを引数とし、その和を計算するmySum()という関数です。要するにsum()関数を再現したものです。
普通のsum()関数と同じ動きをする関数が出来上がりました。よく見ると、上で説明した総和を計算する方法2のコードを丸ごと関数内に入っているだけです。変わったところがあるとすれば、for()文であり、for (i in 1:5)がfor (i in x)に変わっただけです。ここのxはmySum <- function (x)のxを意味します。このように関数を一回作成しておくと、これからは総和を出す作業を1行に短縮することができます。
このmySum()ですが、一つ問題があります。それはxに欠損値が含まれている場合、結果がNAになることです。
実際、R内蔵関数であるsum()も同じですが、sum()にはna.rm =というもう一つの引数があり、これをTRUEにすることで欠損値を除いた総和が計算できます。つまり、関数は複数の引数を持つことができます。それでは、mySum()を改良してみましょう。ここにもna.rmという関数を追加し、na.rm引数がTRUEの場合、xから欠損値を除いた上で総和を計算するようにしましょう。
[1] NA[1] NA[1] 11変わったところは、まずfunction (x)がfunction (x, na.rm = FALSE)になりました。これはxとna.rmの引数が必要であるが、na.rmのデフォルト値はFALSEであることを意味します。デフォルト値が指定されている場合、関数を使用する際、その引数は省略できます。実際、sum()関数のna.rm引数もFALSEがデフォルトとなっており、省略可能となっています。
次は最初に条件分岐が追加されました。ここではna.rmがTRUEの場合、xから欠損値を抜いたベクトルをxに上書きするように指定しました。もし、FALSEならこの処理は行いません。
これでR開発チームが作成したsum()関数と同じものが出来上がりました。それでは引数の順番について簡単に解説し、もうちょっと複雑な関数を作ってみましょう。引数の順番は基本的にfunction()の()内で定義した順番であるなら、引数名を省略することも可能です。
ただし、順番を逆にすると、以下のようにわけのわからない結果が返されます。
任意の順番で引数を指定する場合、引数名を指定する必要があります。
自分で関数を作成し、他の人にも使ってもらう場合、引数名、順番、デフォルト値を適切に設定しておくことも大事です。
12.2 ちょっと複雑な関数
それではちょっとした遊び心を込めた関数を作ってみましょう。その名もドラクエ戦闘シミュレーターです。
以下はドラクエ11のダメージ公式です。
- ダメージの基礎値 = (攻撃力 / 2) - (守備力 / 4)
- 0未満の場合、基礎値は0とする
- ダメージの幅 = (ダメージの基礎値 / 16) + 1
- 端数は切り捨てます (
floor()関数使用)
- 端数は切り捨てます (
ダメージの最小値は「ダメージの基礎値 - ダメージの幅」、最大値は「ダメージの基礎値 - ダメージの幅」となります。この最小値が負になることもありますが、その場合は0扱いになります。実際のダメージはこの範囲内でランダムに決まります (runif()関数使用)。
# DQ_Attack関数を定義
DQ_Attack <- function(attack, defence, hp, enemy) {
## 引数一覧
## attack: 勇者の力 + 武器の攻撃力 (長さ1の数値型ベクトル)
## defence: 敵の守備力 (長さ1の数値型ベクトル)
## hp: 敵のHP (長さ1の数値型ベクトル)
## enemy: 敵の名前 (長さ1の文字型ベクトル)
# ダメージの基礎値
DefaultDamage <- (attack / 2) - (defence / 4)
# ダメージの基礎値が負の場合、0とする
DefaultDamage <- ifelse(DefaultDamage < 0, 0, DefaultDamage)
# ダメージの幅
DamageWidth <- floor(DefaultDamage / 16) + 1
# ダメージの最小値
DamageMin <- DefaultDamage - DamageWidth
# ダメージの最小値が負の場合、0とする
DamageMin <- ifelse(DamageMin < 0, 0, DamageMin)
# ダメージの最大値
DamageMax <- DefaultDamage + DamageWidth
# 敵の残りHPを格納する
CurrentHP <- hp
# 残りHPが0より大きい場合、以下の処理を繰り返す
while (CurrentHP > 0) {
# ダメージの最小値から最大値の間の数値を1つ無作為に抽出する
Damage <- runif(n = 1, min = DamageMin, max = DamageMax)
# 小数点1位で丸める
Damage <- round(Damage, 0)
# 残りのHPを更新する
CurrentHP <- CurrentHP - Damage
# メッセージを表示
print(paste0(enemy, "に", Damage, "のダメージ!!"))
}
# 上記の反復処理が終わったら勝利メッセージを出力
paste0(enemy, "をやっつけた!")
}初めて見る関数が3つありますね。まず、floor()関数は引数の端数は切り捨てる関数です。たとえば、floor(2.1)もfloor(2.6)も結果は2です。続いて、runif()関数は指定された範囲の一様分布から乱数を生成する関数です。引数は生成する乱数の個数 (n)、最小値 (min)、最大値 (max)の3つです。runif(5, 3, 10)なら最小値3、最大値10の乱数を5個生成するという意味です。正規分布は平均値周辺の値が生成されやすい一方、一様分布の場合、ある値が抽出される確率は同じです。最後にround()関数は四捨五入の関数です。引数は2つあり、1つ目の引数は数値型のベクトルです。2つ目は丸める小数点です。たとえば、round(3.127, 1)の結果は3.1であり、round(3.127, 2)の結果は3.13となります。
それでは「ひのきのぼう」を装備したレベル1の勇者を考えてみましょう。ドラクエ5の場合、Lv1勇者の力は11、「ひのきのぼう」の攻撃力は2ですので、攻撃力は13です。まずは定番のスライムから狩ってみましょう。スライムのHPと守備力は両方7です。
[1] "スライムに4のダメージ!!"
[1] "スライムに5のダメージ!!"[1] "スライムをやっつけた!"まぁ、こんなもんでしょう。それではスライムナイト (=ピエール)はどうでしょう。スライムナイトのHPのは40、守備力は44です。
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"
[1] "スライムナイトに0のダメージ!!"
[1] "スライムナイトに1のダメージ!!"[1] "スライムナイトをやっつけた!"これだと「なんと スライムナイトが おきあがりなかまに なりたそうに こちらをみている!」のメッセージを見る前に勇者ご一行が全滅しますね。エスターク (HP: 9000 / 守備力: 250)は計算するまでもないでしょう…
以上の関数に条件分岐を追加することで「かいしんの いちげき!」を入れることもできますし1、逆に敵からの攻撃を計算して誰が先に倒れるかをシミュレーションすることも可能でしょうね。色々遊んでみましょう。
12.3 関数 in 関数
当たり前かも知れまっせんが、自作関数を他の自作関数に含めることもできます。ここでは乱数を生成する関数を作ってみましょう。パソコンだけだと完全な乱数を作成することは不可能ですが2、乱数に近いものは作れます。このようにソフトウェアで生成された乱数は擬似乱数と呼ばれ、様々なアルゴリズムが提案されています。天才、フォン・ノイマン大先生も乱数生成では天才ではなかったらしく、彼が提案した平方採中法 (middle-square method)は使い物になりませんので、ここではもうちょっとマシな方法である線形合同法 (linear congruential generators; 以下、LCG)を採用します。平方採中法よりは式が複雑ですが、それでも非常に簡単な式で乱数が生成可能であり、Rによる実装に関しては平方採中法より簡単です。ちなみに、線形合同法にも様々な問題があり、Rのデフォルトは広島大学の松本眞先生と山形大学の西村拓士先生が開発しましたメルセンヌ・ツイスタ (Mersenne twister)を採用しています。それでは、LCGのアルゴリズムから見ましょう。
乱数の列があるとし、\(n\)番目の乱数を\(X_n\)とします。この場合、\(X_{n+1}\)は以下のように生成されます。
\[ X_{n+1} = (aX_n + c) \text{ mod } m \]
\(\text{mod}\)は余りを意味し、\(5 \text{mod} 3\)は5を3で割った際の余りですので、2となります。\(a\)と\(c\)、\(m\)は以下の条件を満たす任意の数です。
\[\begin{align} 0 < & m, \\ 0 < & a < m, \\ 0 \leq & c < m. \end{align}\]
ベストな\(a\)、\(c\)、\(m\)も決め方はありませんが、ここではTurbo Cの設定を真似て\(a = 22695477\)、\(c = 1\)、\(m = 2^{32}\)をデフォルト値として設定します3。そして、もう一つ重要なのが最初の数、つまり\(X_n\)をどう決めるかですが、これは自由に決めて問題ありません。最初の数 (\(X_0\))はシード (seed)と呼ばれ、最終的には使わない数字となります。それではseedという引数からある乱数を生成する関数rng_number()を作ってみましょう。
簡単な四則演算のみで構成された関数ですね。ちなみに%%は余りを計算する演算子です。とりあえず、seedを12345に設定し、一つの乱数を生成してみましょう。
かなり大きい数字が出ました。ちなみに線形合同法で得られる乱数の最大値は\(m\)、最小値は0です。次は、今回得られた乱数1.0027893^{9}を新しいseedとし、新しい乱数を作ってみましょう。
この作業を繰り返すと、(疑似)乱数の数列が得られます。続いて、この作業をn回繰り返し、長さnの乱数ベクトルを返す関数LCGを作ってみましょう。いかがコードになります。
LCG <- function(n, seed, a = 22695477, c = 1, m = 2^32) {
rng_vec <- rep(NA, n + 1) # seedも入るので長さn+1の空ベクトルを生成
rng_vec[1] <- seed # 1番目の要素にseedを入れる
# iに2からn+1までの値を順次的に投入しながら、反復処理
for (i in 2:(n+1)) {
# rng_vecのi番目にi-1番目の要素をseedにした疑似乱数を格納
rng_vec[i] <- rng_number(rng_vec[i - 1], a, c, m)
}
rng_vec <- rng_vec[-1] # 1番目の要素 (seed)を捨てる
rng_vec <- rng_vec / m # 最小値0、最大値1になるように、mで割る
rng_vec # 結果を返す
}それでは、詳細に解説します。
- 1行目: 関数
LCGを定義し、必要な引数としてnとseedを設定する。 - 2行目: 結果を格納する空ベクトル
rng_vecを生成。ただし、1番目にはseedが入るので、長さをn+1とする。 - 3行目:
rng_vecの1番目にseedを格納する。 - 6行目: 疑似乱数を
n回生成し、格納するように反復作業を行う。任意の変数はiとし、iに代入される値は2からn+1までである。 - 8行目:
rng_vecのi-1番目要素をseedにした疑似乱数を生成し、rng_vecのi番目に格納する。1回目の処理だとi=2であるため、rng_vec[1](=seed)をseedにした疑似乱数が生成され、rng_vec[2]に格納される。 - 11行目:
rng_vecの1番目の要素はseedであるため、捨てる。 - 12行目: 乱数が最小値0、最大値1になるように、調整する。具体的には得られた乱数を
m(デフォルトは\(2^{32}\))で割るだけである。 - 14行目: 結果ベクトルを返す。
それでは、seedを19861008とした疑似乱数10000個を生成し、LCG_Numbersという名のベクトルに格納してみましょう。結果を全て表示させるのは無理があるので、最初の20個のみを確認してみます。
[1] 0.58848246 0.09900449 0.21707060 0.89462981 0.23421890 0.72341249
[7] 0.55965400 0.59552685 0.96594972 0.69050965 0.98383344 0.20136551
[13] 0.25856502 0.37569497 0.50086451 0.03986446 0.89291806 0.24760102
[19] 0.27912510 0.24493750正直、これが乱数かどうかは見るだけでは分かりませんね。簡単な確認方法としては、これらの乱数列のヒストグラムを見れば分かります。得られた数列が本当に乱数(に近いもの)なら、その分布は一様分布に従っているからです。ただし、一様分布に従っていることが乱数を意味するものではありません。
可視化については第19章以降で解説しますが、ここでは簡単にhist()関数を使ってみましょう。必要な引数はnumeric型のベクトルのみです。以下のコードにあるxlab =などはラベルを指定する引数ですが、省略しても構いません。
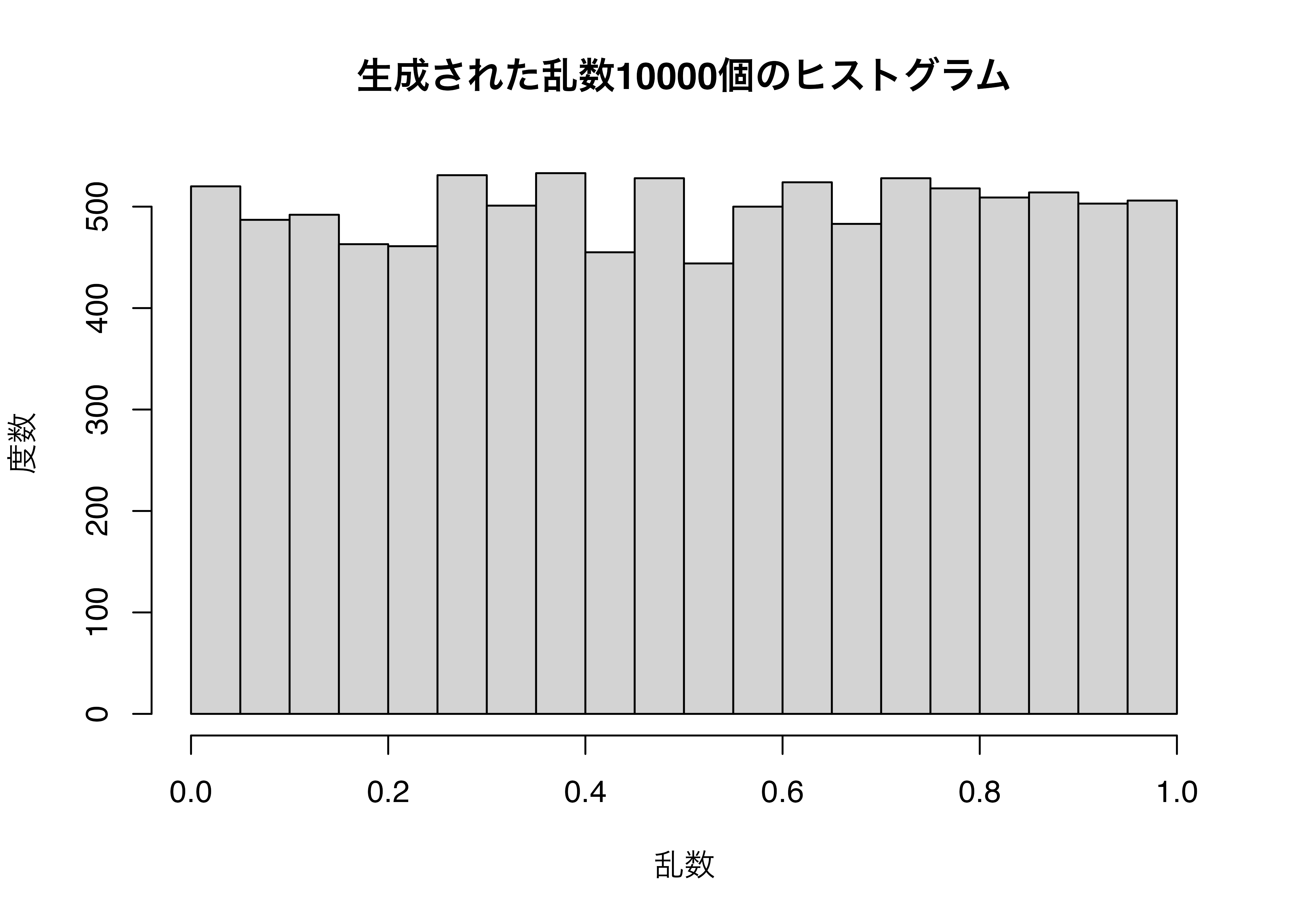
ややギザギザしているように見えますが4、これなら一様分布だと考えて良いでしょう。
12.4 練習問題
問1
- 長さ2のnumericベクトル
Dataについて考える。条件分岐を用いてDataの1番目の要素(Data[1])が2番目の要素(Data[2])より大きい場合、1番目の要素と2番目の順番を逆転させる条件分岐を作成せよ。たとえば、Data <- c(5, 3)なら、条件分岐後のDataの値がc(3, 5)になること。
問2
- 与えられた正の実数の平方根を求める
my_sqrt()を作成する。平方根を計算する方法はHero of Alexandriaの近似法5を使用する。- 平方根を求める
x、任意の初期値g、非常に小さい正の実数eを入力する。eの既定値は0.001とする。 gの2乗を計算し、x - g^2の絶対値をgapとする(gapの初期値はInfとする)。gapがeより小さい場合、gをxの平方根として返す。gapがeより大きい場合、g + (x / g)を新しいgとする。- 2へ戻る。
- 平方根を求める
while()関数を使えば簡単である。
[1] 5.385165[1] 5.385185[1] 5.385165Error in my_sqrt(-3, 5, e = 1e-05): xは正の実数でなければなりません。問3
- 問1ではベクトルの1番目要素と2番目の要素を比較し、前者が大きい場合において順番を入れ替える条件分岐を行った。これを長さ3以上のベクトルにも適用したい。長さ4のnumeric型ベクトル
Dataがある場合の計算手順について考えてみよう。Data[1]とData[2]の要素を比較し、Data[1] > Data[2]の場合、入れ替える。Data[2]とData[3]の要素を比較し、Data[2] > Data[3]の場合、入れ替える。Data[3]とData[4]の要素を比較し、Data[3] > Data[4]の場合、入れ替える。この段階でData[4]はDataの最大値が格納される。- 続いて、
Data[1]とData[2]の要素を比較し、Data[1] > Data[2]の場合、入れ替える。 Data[2]とData[3]の要素を比較し、Data[2] > Data[3]の場合、入れ替える。この段階でData[3]にはDataの2番目に大きい数値が格納される。- 最後に
Data[1]とData[2]の要素を比較し、Data[1] > Data[2]の場合、入れ替える。ここで並び替えは終了
- ヒント: 2つの
for()文が必要となる。これは「バブルソート」と呼ばれる最も簡単なソートアルゴリズムである。イメージとしては、長さNのベクトルの場合、n番目の要素とn+1番目の要素を比較しながら、大きい方を後ろの方に追い込む形である。最初は、Data[4]最後の要素に最大値を格納し、続いて、Data[3]に次に大きい数値を、Data[2]に次に大きい数値を入れる仕組みである。- 最初は
Data[1]とData[2]、Data[2]とData[3]、Data[3]とData[4]の3ペアの比較を行う。 - 続いて、
Data[1]とData[2]、Data[2]とData[3]の2ペアの比較を行う - 最後に、
Data[1]とData[2]の1ペアの比較を行う - つまり、外側の
for()文は「Dataの長さ-1」回繰り返すことになる。 - 内側の
for()文は3, 2, 1ペアの比較を行うことになる。
- 最初は
問4
- 「問3」で作成したコードを関数化せよ。関数名は
mySort()であり、引数は長さ2以上のnumeric型ベクトルのみである。引数名は自由に決めても良いし、dataやxなどを使っても良い。
問5
- 既に作成した
DQ_Attack関数を修正してみよう。今の関数は通常攻撃のみであるが、稀に「会心の一撃」が発生するように修正する。- 会心の一撃が発生する確率は1/32とする(ヒント:0から1の間の乱数を生成し、その乱数が1/32以下であるか否かで条件分岐させる)。乱数の生成は
runif()または、自作関数のLCG()でも良い。 - 会心の一撃のダメージの最小値は攻撃力の95%、最大値は105%とする。
- 会心の一撃が発生したら、
"かいしんのいちげき! スライムに10のダメージ!!"のようなメッセージを出力させること。
- 会心の一撃が発生する確率は1/32とする(ヒント:0から1の間の乱数を生成し、その乱数が1/32以下であるか否かで条件分岐させる)。乱数の生成は
問6
- 与えられたベクトル
xからn個の要素を無作為に抽出する関数、mySample()を定義せよ。mySample()の引数はxとn、seedとし、xは長さ1以上のベクトルとする。nは長さ1の整数型ベクトルである。- 以下の場合、エラーメッセージを出力し、処理を中止させること。
nとseedが長さ1ベクトルでない場合、seedがnumeric型でない場合nが整数でない場合(floor(n) == nで判定)
- ヒント:
LCG()関数を用いて乱数を生成した場合、生成された擬似乱数は0以上1以下である。ベクトルxの長さをlength(x)とした場合、擬似乱数にlength(x)を掛けると、擬似乱数は0以上length(x)以下になる。これらの値を切り上げると(ceiling()関数)、その値は1以上length(x)以下の整数となる。
- 以下の場合、エラーメッセージを出力し、処理を中止させること。