16 データハンドリング [factor型]
16.1 名目変数を含むグラフを作成する際の注意点
ここからは楽しい可視化、つまりグラフの作成について解説します。ただし、その前に、名目変数の扱いと簡潔データ構造について話したいと思います。本章では名目変数の扱いについて解説し、次章は簡潔データ構造について解説します。
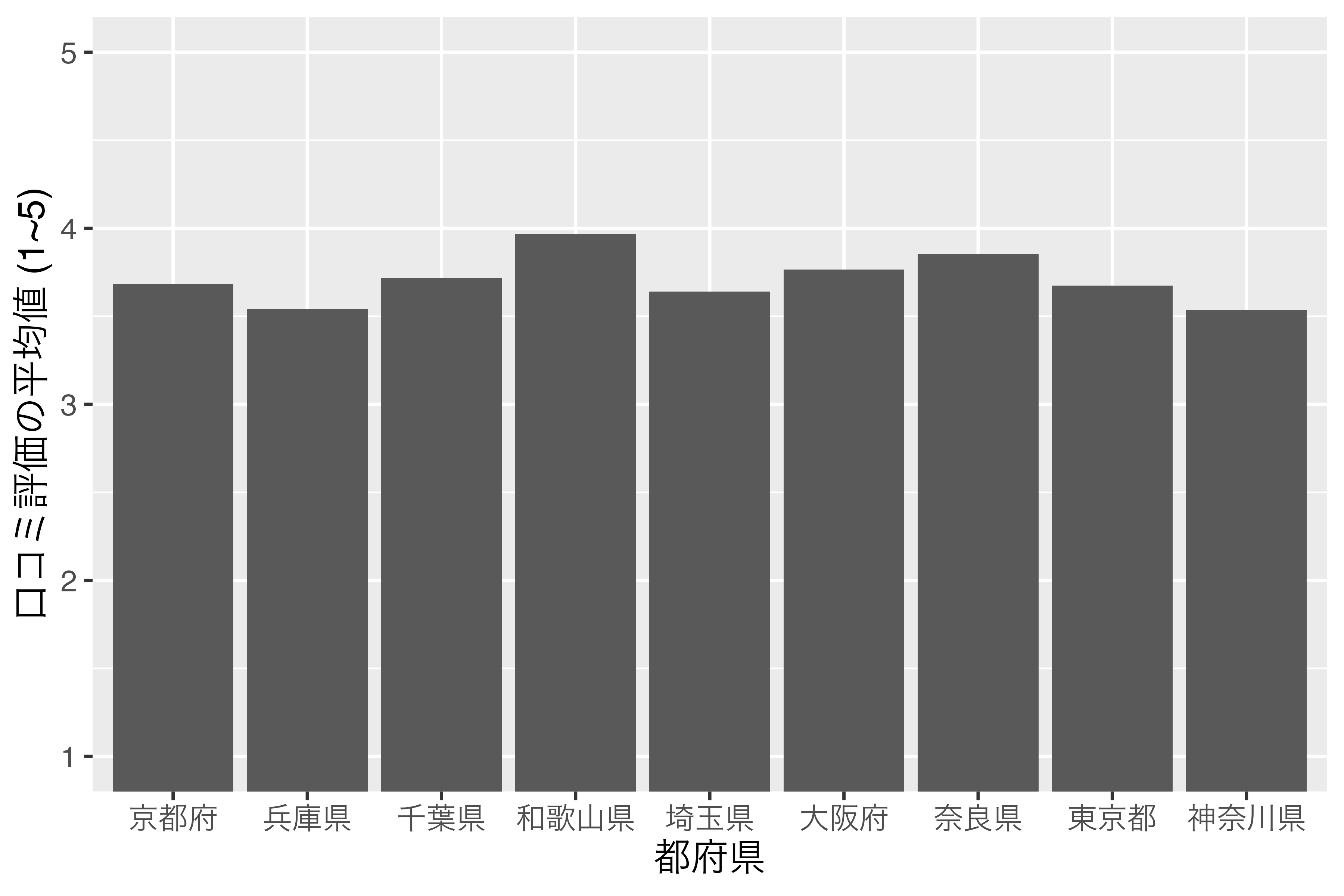
横軸、または縦軸が気温、成績、身長のような連続変数ではなく、都道府県や国、企業のような名目変数になる場合があります。たとえば、棒グラフの横軸は 図 16.1 のように、一般的に名目変数になる場合が多いです。
ここでは横軸の順番に注目してください。京都府、埼玉県、神奈川県、…の順番になっていますね。「この順番で大満足だよ!」という方がいるかも知れませんが、そうでない方もおおいでしょう。普通考えられるものとしては、都道府県コードの順か、縦軸が高い順 (低い順)でしょう。都道府県コードの順だと、埼玉県、千葉県、東京都、神奈川県、京都府、大阪府、兵庫県、奈良県、和歌山県の順番になります。または、縦軸 (口コミ評価の平均値)が高い順なら和歌山県、奈良県、大阪府、…の順番になります。あるいは50音順も考えられるでしょう。アメリカの場合、州を並べる際、アルファベット順で並べます。
自分でこの順番をコントロールするには可視化の前の段階、つまりデータハンドリングの段階で順番を決めなくてはなりません。これを決めておかない場合、Rが勝手に順番を指定します。具体的にはロケール (locale)というパソコン内の空間に文字情報が含まれているわけですが、そこに保存されている文字の順番となります。たとえば、日本語ロケールには「京」が「埼」よりも先に保存されているわけです。
したがって、名目変数がグラフに含まれる場合は、名目変数の表示順番を決める必要があり、そこで必要なのがfactor型です。名目変数がcharacter型の場合、ロケールに保存されている順でソートされますが、factor型の場合、予め指定した順番でソートされます。
たとえば、前章で使用したデータを用いて、都道府県ごとの口コミ評価の平均値を計算し、その結果をScore_dfとして保存します。
Score_df <- df |>
group_by(Pref) |>
summarise(Score = mean(Score, na.rm = TRUE),
.groups = "drop")
Score_df# A tibble: 9 × 2
Pref Score
<chr> <dbl>
1 京都府 3.68
2 兵庫県 3.54
3 千葉県 3.72
4 和歌山県 3.97
5 埼玉県 3.64
6 大阪府 3.77
7 奈良県 3.85
8 東京都 3.67
9 神奈川県 3.53この時点で勝手にロケール順になります。実際、表示されたScore_dfを見るとPrefの下に<chr>と表記されており1、Prefはcharacter型であることが分かります。これをこのまま棒グラフに出してみましょう。可視化の方法はこれから詳細に解説するので、ここでは結果だけに注目してください。
Score_df |>
ggplot() +
geom_bar(aes(x = Pref, y = Score), stat = "identity") +
labs(x = "都府県", y = "口コミ評価の平均値 (1~5)") +
theme(text = element_text(size = 12))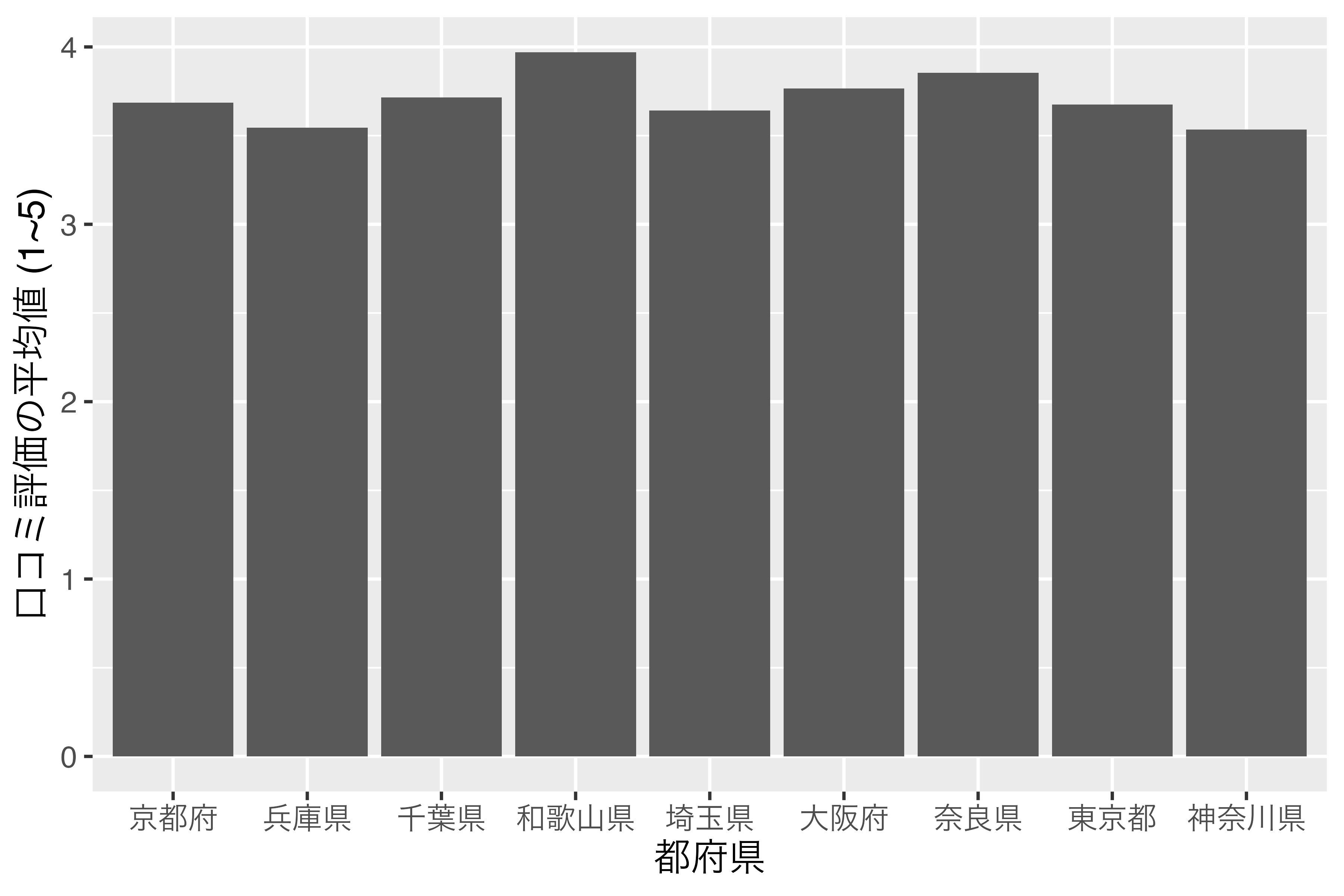
横軸の順番があまり直感的ではありませんね。それでは、Score_dfをScoreが高い順にソートし、Score_df2で保存してから、もう一回試してみます。
# A tibble: 9 × 2
Pref Score
<chr> <dbl>
1 和歌山県 3.97
2 奈良県 3.85
3 大阪府 3.77
4 千葉県 3.72
5 京都府 3.68
6 東京都 3.67
7 埼玉県 3.64
8 兵庫県 3.54
9 神奈川県 3.53ここでもPrefはcharacter型ですが、とりあえず、これで図を出してみます。
Score_df2 |>
ggplot() +
geom_bar(aes(x = Pref, y = Score), stat = "identity") +
labs(x = "都府県", y = "口コミ評価の平均値 (1~5)") +
theme(text = element_text(size = 12))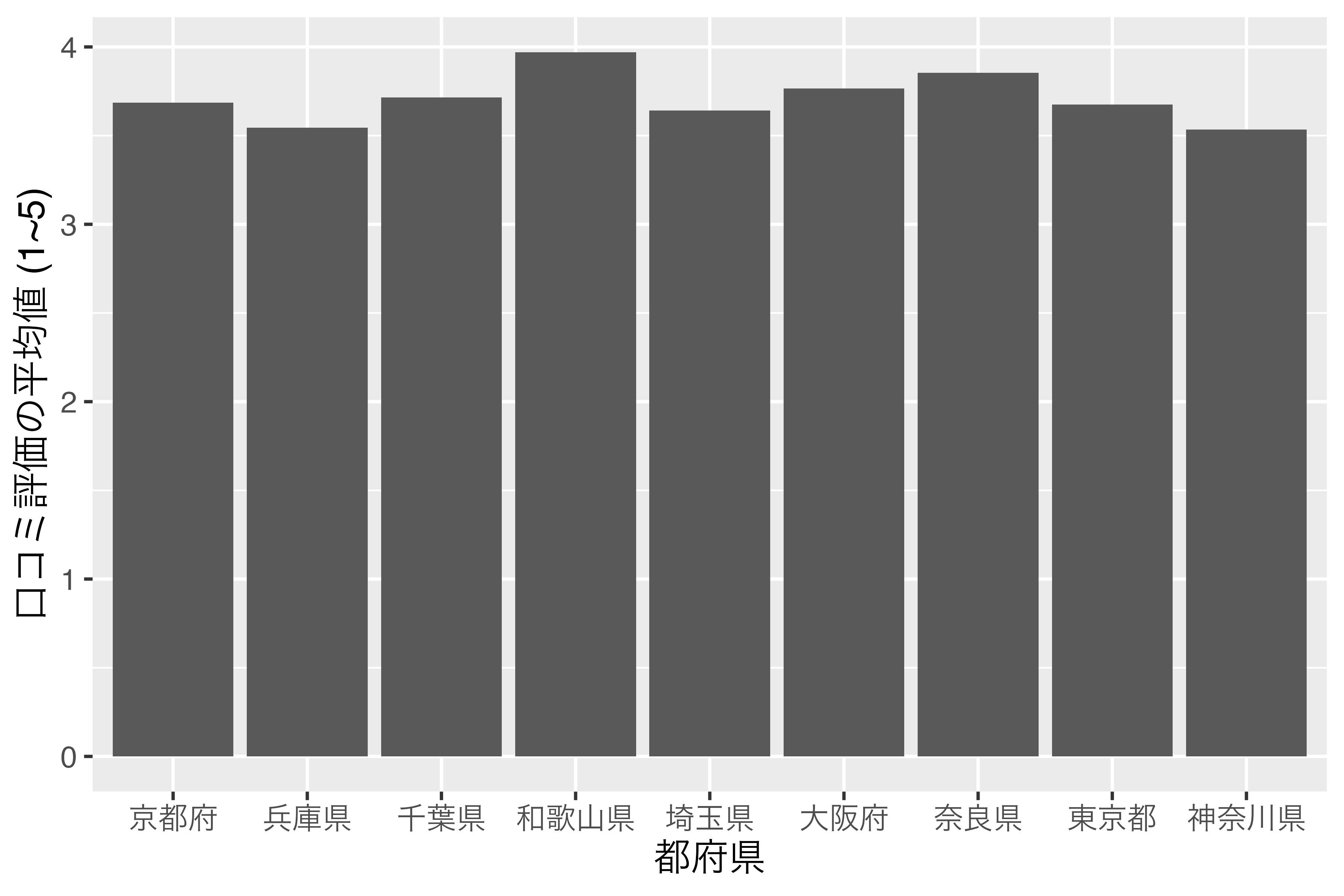
結果は全く変わっておりません。それでは、Score_dfのPref列をfactor型に変換し、順番は口コミ評価の平均値が高い順番にしてみましょう。結果はScore_df_f1という名で保存します。
Score_df_f1 <- Score_df |>
mutate(Pref = factor(Pref, levels = c("和歌山県", "奈良県", "大阪府",
"千葉県", "京都府", "東京都",
"埼玉県", "兵庫県", "神奈川県")))
Score_df_f1# A tibble: 9 × 2
Pref Score
<fct> <dbl>
1 京都府 3.68
2 兵庫県 3.54
3 千葉県 3.72
4 和歌山県 3.97
5 埼玉県 3.64
6 大阪府 3.77
7 奈良県 3.85
8 東京都 3.67
9 神奈川県 3.53表示される順番はScore_dfとScore_df_f1も同じですが、Prefのデータ型が<fct>、つまりfactor型であることが分かります。実際、Pref列だけ抽出した場合、factor型として、和歌山県から神奈川県の順になっていることが確認できます。
[1] 京都府 兵庫県 千葉県 和歌山県 埼玉県 大阪府 奈良県 東京都
[9] 神奈川県
9 Levels: 和歌山県 奈良県 大阪府 千葉県 京都府 東京都 埼玉県 ... 神奈川県このScore_df_f1データを使って、 図 16.2 と全く同じコードを実行した結果が 図 16.4 です。
Score_df_f1 |>
ggplot() +
geom_bar(aes(x = Pref, y = Score), stat = "identity") +
labs(x = "都府県", y = "口コミ評価の平均値 (1~5)") +
theme(text = element_text(size = 12))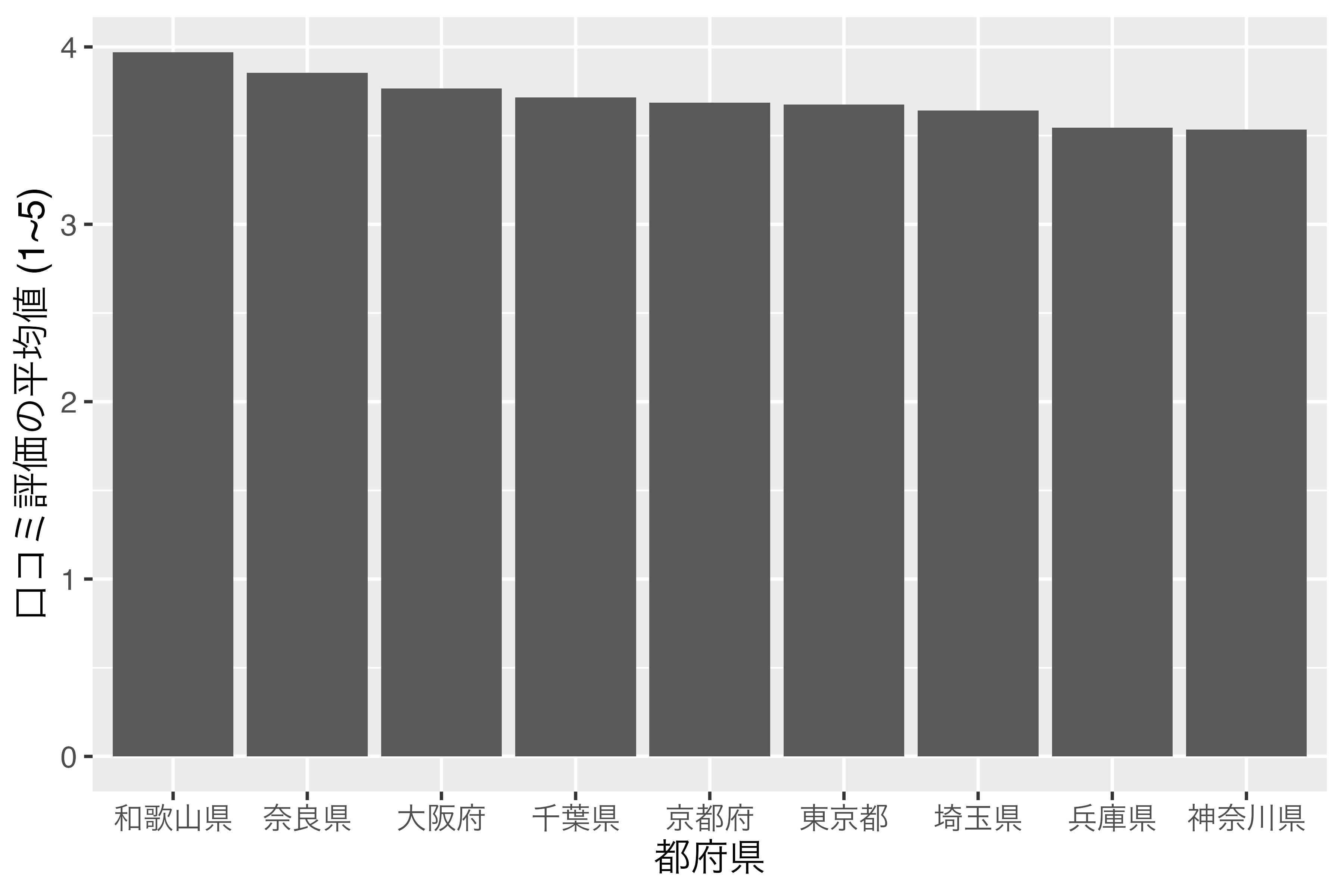
これまでの話をまとめるの以下の2点が分かります。
- 変数がcharacter型である場合、自動的にロケール順でソートされる。
- 変数がfactor型である場合、データ内の順番やロケール順と関係なく、指定されたレベル (水準)の順でソートされる。
とくに2番目の点についてですが、これは必ずしも順序付きfactorである必要はありません。順序付きfactor型でなくても、factor()内で指定した順にソートされます。むろん、順序付きfactor型なら指定された順序でソートされます。
これからはfactor型変換の際に便利な関数をいくつか紹介しますが、その前に数値として表現された名目変数について話します。たとえば、Score_df_f1に関東地域なら1を、その他の地域なら0を付けたKantoという変数があるとします。
Score_df_f1 <- Score_df_f1 |>
mutate(Kanto = ifelse(Pref %in% c("東京都", "神奈川県", "千葉県", "埼玉県"), 1, 0))
Score_df_f1# A tibble: 9 × 3
Pref Score Kanto
<fct> <dbl> <dbl>
1 京都府 3.68 0
2 兵庫県 3.54 0
3 千葉県 3.72 1
4 和歌山県 3.97 0
5 埼玉県 3.64 1
6 大阪府 3.77 0
7 奈良県 3.85 0
8 東京都 3.67 1
9 神奈川県 3.53 1Kanto変数のデータ型は、<dbl>、つまりnumeric型です。しかし、これは明らかに名目変数ですね。これをこのままKantoを横軸にした図を出すと 図 16.5 のようになります。
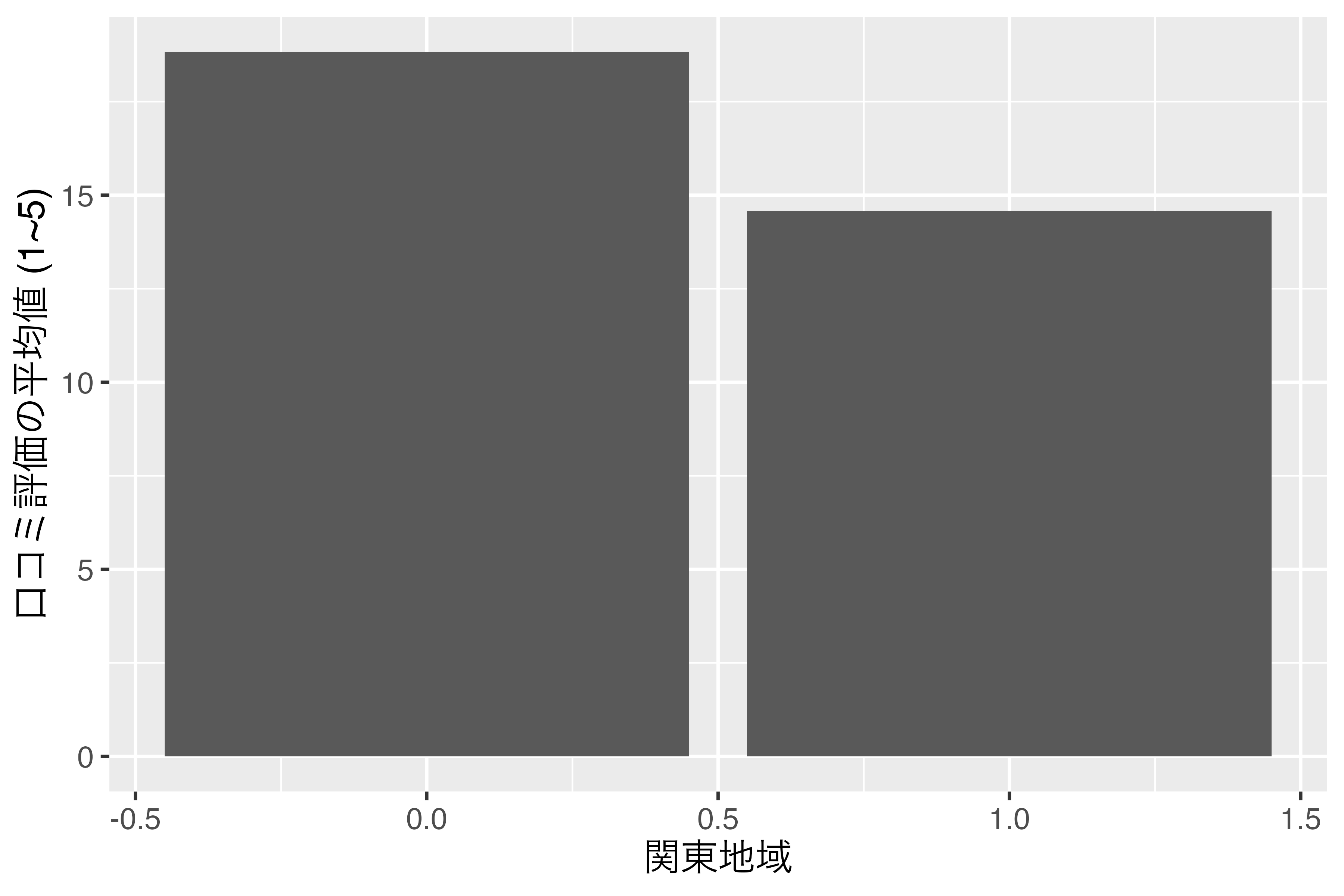
この場合、図の横軸はKantoの値が小さい順でソートされます。ただし、このような図は非常に見にくいため、1に"関東"、0に"関西"とラベルを付けたfactor型に変換した方が望ましいです。numeric型をラベル付きのfactor型にするためには、levels引数には元の数値を、labels引数にはそれぞれの数値に対応したラベルを指定します。また、関東の方を先に出したいので、factor()内のlevels引数はc(0, 1)でなく、c(1, 0)にします。
Score_df_f1 <- Score_df_f1 |>
mutate(Kanto = factor(Kanto, levels = c(1, 0), labels = c("関東", "その他")))
Score_df_f1# A tibble: 9 × 3
Pref Score Kanto
<fct> <dbl> <fct>
1 京都府 3.68 その他
2 兵庫県 3.54 その他
3 千葉県 3.72 関東
4 和歌山県 3.97 その他
5 埼玉県 3.64 関東
6 大阪府 3.77 その他
7 奈良県 3.85 その他
8 東京都 3.67 関東
9 神奈川県 3.53 関東 Kanto変数がfactor型に変換されたことが分かります。
また、"関東"、"その他"の順になっていますね。これを図として出力した結果が 図 16.6 です。
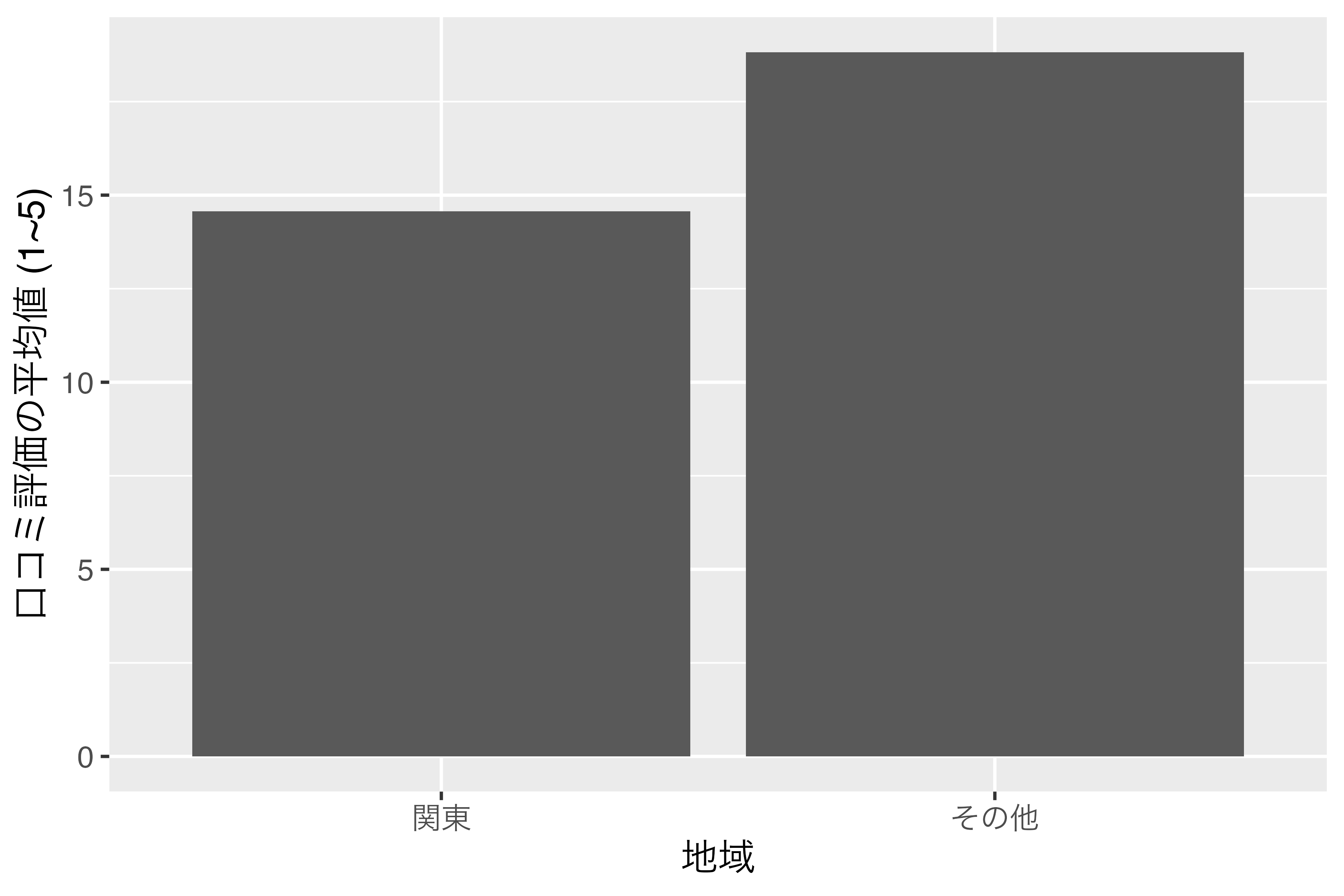
このように数値型名目変数でも、factor化することによって、自由に横軸の順番を変えることができます。それでは、factor化に使える便利な関数をいくつか紹介します。
16.2 {forcats}パッケージについて
実はfactor型への変換や、順番に変更などは全てR内蔵のfactor()関数で対応可能ですが、ここでは{forcats}パッケージが提供しているfct_*()関数を使用します。{forcats}パッケージは{tidyverse}を読み込む際、自動的に読み込まれるため、既に{tidyverse}を読み込んでいる場合、別途のコードは要りません。
16.2.1 fct_relevel(): 水準の順番を変更する
Score_df_f1のf1はScoreが高い順になっています。これを50音順に変更する際、fct_relevel()関数を使います。
ここでは、Pref変数を再調整したPref2変数を作ってみましょう。
Score_df_f1 <- Score_df_f1 |>
mutate(Pref2 = fct_relevel(Pref, "大阪府", "神奈川県", "京都府",
"埼玉県", "千葉県", "東京都",
"奈良県", "兵庫県", "和歌山県"))
Score_df_f1# A tibble: 9 × 4
Pref Score Kanto Pref2
<fct> <dbl> <fct> <fct>
1 京都府 3.68 その他 京都府
2 兵庫県 3.54 その他 兵庫県
3 千葉県 3.72 関東 千葉県
4 和歌山県 3.97 その他 和歌山県
5 埼玉県 3.64 関東 埼玉県
6 大阪府 3.77 その他 大阪府
7 奈良県 3.85 その他 奈良県
8 東京都 3.67 関東 東京都
9 神奈川県 3.53 関東 神奈川県一見、PrefとPref2変数は同じように見えますが、水準はどうなっているでしょうか。
[1] "和歌山県" "奈良県" "大阪府" "千葉県" "京都府" "東京都" "埼玉県"
[8] "兵庫県" "神奈川県"[1] "大阪府" "神奈川県" "京都府" "埼玉県" "千葉県" "東京都" "奈良県"
[8] "兵庫県" "和歌山県"問題なく50音順になっていることが分かります。他にもfct_relevel()には全ての水準名を指定する必要がありません。一部の水準名も可能です。たとえば、「関東が関西の先に来るなんでけしからん!」と思う読者もいるでしょう。この場合、関西の府県名を入れると、指定した水準が最初に位置するようになります。
Score_df_f1 <- Score_df_f1 |>
mutate(Pref3 = fct_relevel(Pref, "京都府", "大阪府",
"兵庫県", "奈良県", "和歌山県"))
levels(Score_df_f1$Pref3) # Pref3の水準[1] "京都府" "大阪府" "兵庫県" "奈良県" "和歌山県" "千葉県" "東京都"
[8] "埼玉県" "神奈川県"一部の水準名のみを指定するとその水準が最初に移動されますが、after引数を指定すると、位置を調整することも可能です。after = 2の場合、元となる変数の1、3番目の水準は維持され、3番目以降に指定した水準、それに続いて指定されていない水準の順番になります。Prefは和歌山、奈良、大阪の順ですが、ここで京都と東京を、奈良と大阪の間に移動するなら、
Score_df_f1 <- Score_df_f1 |>
mutate(Pref4 = fct_relevel(Pref, "京都府", "東京都", after = 2))
levels(Score_df_f1$Pref4) # Pref4の水準[1] "和歌山県" "奈良県" "京都府" "東京都" "大阪府" "千葉県" "埼玉県"
[8] "兵庫県" "神奈川県"のように書きます。afterを指定しない場合のデフォルト値は0であるため、最初に移動します。
16.2.2 fct_recode(): 水準のラベルを変更する
fct_recode()は水準のラベルを変更する時に使う関数で、以下のように使います。
注意点としては新しいラベルは"で囲まず、既存のラベルは"で囲む点です。それでは、Prefのラベルをローマ字に変更してみましょう。
Score_df_f1 <- Score_df_f1 |>
mutate(Pref5 = fct_recode(Pref,
Saitama = "埼玉県",
Wakayama = "和歌山県",
Kyoto = "京都府",
Osaka = "大阪府",
Tokyo = "東京都",
Nara = "奈良県",
Kanagawa = "神奈川県",
Hyogo = "兵庫県",
Chiba = "千葉県"))
Score_df_f1# A tibble: 9 × 7
Pref Score Kanto Pref2 Pref3 Pref4 Pref5
<fct> <dbl> <fct> <fct> <fct> <fct> <fct>
1 京都府 3.68 その他 京都府 京都府 京都府 Kyoto
2 兵庫県 3.54 その他 兵庫県 兵庫県 兵庫県 Hyogo
3 千葉県 3.72 関東 千葉県 千葉県 千葉県 Chiba
4 和歌山県 3.97 その他 和歌山県 和歌山県 和歌山県 Wakayama
5 埼玉県 3.64 関東 埼玉県 埼玉県 埼玉県 Saitama
6 大阪府 3.77 その他 大阪府 大阪府 大阪府 Osaka
7 奈良県 3.85 その他 奈良県 奈良県 奈良県 Nara
8 東京都 3.67 関東 東京都 東京都 東京都 Tokyo
9 神奈川県 3.53 関東 神奈川県 神奈川県 神奈川県 Kanagawafct_recode()の中に指定する水準の順番は無視されます。つまり、水準の順番はそのまま維持されるため、好きな順番で結構です。また、全ての水準を指定せず、一部のみ変更することも可能です。それではPref5の順番がPrefの順番と同じかを確認してみましょう。
16.2.3 fct_rev(): 水準の順番を反転させる
水準の順番を反転することは非常によくあります。たとえば、グラフの読みやすさのために、左右または上下を反転するケースがあります。既に何回も強調しましたように、名目変数は基本的にfactor型にすべきであり、ここでfct_rev()関数が非常に便利です。たとえば、Pref2の水準は50音順でありますが、これを反転し、Pref6という名の列として追加してみましょう。
[1] "和歌山県" "兵庫県" "奈良県" "東京都" "千葉県" "埼玉県" "京都府"
[8] "神奈川県" "大阪府" 関数一つで水準の順番が反転されました。
16.2.4 fct_infreq(): 頻度順に順番を変更する
続いて、水準の順番を頻度順に合わせるfct_infreq()関数です。たとえば、Scoreが欠損でないケースのみで構成されたdf2を考えてみましょう。
そして、都府県ごとのケース数を計算します。
ここでPrefをfactor化しますが、水準の順番を店舗数が多い方を先にするにはどうすれば良いでしょうか。fct_infreq()関数は指定された変数の各値の個数を計算し、多い順にfactorの水準を調整します。
df2 <- df2 |>
# 多く出現した値順でfactor化する
mutate(Pref = fct_infreq(Pref))
levels(df2$Pref) # df2のPref変数の水準を出力[1] "東京都" "神奈川県" "大阪府" "埼玉県" "千葉県" "兵庫県" "京都府"
[8] "奈良県" "和歌山県""東京都"、"神奈川県"、"大阪府"、…の順で水準の順番が調整され、これはtable(df$Pref2)の順位とも一致します。
16.2.5 fct_inorder(): データ内の出現順番に順番を変更する
続いて、fct_inorder()ですが、これは意外と頻繁に使われる関数です。たとえば、自分でデータフレームなどを作成し、ケースの順番も綺麗に整えたとします。しかし、既に指摘した通り、データフレーム (または、tibble)での順番とグラフにおける順番は一致するとは限りません。データフレームに格納された順番でfactorの水準が設定できれば非常に便利でしょう。そこで使うのがfct_inorder()です。
たとえば、dfのPrefは"東京都"が1000個並び、続いて"神奈川県"が1000個、"千葉県"が1000個、…の順番で格納されています。この順番をそのままfactorの順番にするには以下のように書きます。
16.2.6 fct_shift(): 水準の順番をずらす
続いて、水準の順番をずらすfct_shift()関数を紹介します。たとえば、「1:そう思う」〜「5:そう思わない」、「9:答えたくない」の6水準で構成された変数があるとします。
df4 <- tibble(
ID = 1:10,
Q1 = c(1, 5, 3, 2, 9, 2, 4, 9, 5, 1)
)
df4 <- df4 |>
mutate(Q1 = factor(Q1, levels = c(1:5, 9),
labels = c("そう思う",
"どちらかと言えばそう思う",
"どちらとも言えない",
"どちらかと言えばそう思わない",
"そう思わない",
"答えたくない")))
df4# A tibble: 10 × 2
ID Q1
<int> <fct>
1 1 そう思う
2 2 そう思わない
3 3 どちらとも言えない
4 4 どちらかと言えばそう思う
5 5 答えたくない
6 6 どちらかと言えばそう思う
7 7 どちらかと言えばそう思わない
8 8 答えたくない
9 9 そう思わない
10 10 そう思う 水準の順番も「そう思う」〜「答えたくない」順で綺麗に整っています。この水準を反転するにはfct_rev()関数が便利です。Q1の水準を反転した変数をQ1_Rという新しい列として追加し、水準を確認してみましょう。
# A tibble: 10 × 3
ID Q1 Q1_R
<int> <fct> <fct>
1 1 そう思う そう思う
2 2 そう思わない そう思わない
3 3 どちらとも言えない どちらとも言えない
4 4 どちらかと言えばそう思う どちらかと言えばそう思う
5 5 答えたくない 答えたくない
6 6 どちらかと言えばそう思う どちらかと言えばそう思う
7 7 どちらかと言えばそう思わない どちらかと言えばそう思わない
8 8 答えたくない 答えたくない
9 9 そう思わない そう思わない
10 10 そう思う そう思う [1] "答えたくない" "そう思わない"
[3] "どちらかと言えばそう思わない" "どちらとも言えない"
[5] "どちらかと言えばそう思う" "そう思う" 「答えたくない」が最初の順番に来ましてね。できれば、「そう思わない」〜「そう思う」、「答えたくない」の順番にしたいところです。ここで使うのがfct_shift()ですが、書き方がややこしいので、噛み砕いて解説します。
問題はn =引数ですが、その挙動については 表 16.1 を参照してください。
fct_shift()の仕組み
| 1番目 | 2番目 | 3番目 | 4番目 | 5番目 | 6番目 | |
|---|---|---|---|---|---|---|
n = -2 |
E |
F |
A |
B |
C |
D |
n = -1 |
F |
A |
B |
C |
D |
E |
n = 0 |
A |
B |
C |
D |
E |
F |
n = 1 |
B |
C |
D |
E |
F |
A |
n = 2 |
C |
D |
E |
F |
A |
B |
具体的には水準は左方向へn個移動します。元の水準がA, B, C, …, Fの順で、n = 1の場合、AがFの後ろへ移動し、B, C, D, E, Fが前の方へ1つずつ移動します。逆に右側へ1つ移動したい場合はn = -1のように書きます。今回は最初の水準を最後に移動させたいので、n = 1と指定します。
[1] "そう思わない" "どちらかと言えばそう思わない"
[3] "どちらとも言えない" "どちらかと言えばそう思う"
[5] "そう思う" "答えたくない" これで水準の反転が完了しました。fct_shift()はこのように世論調査データの処理に便利ですが、他にも曜日の処理に使えます。例えば、1週間の始まりを月曜にするか日曜にするかによって、fct_shift()を使うケースがあります。
16.2.7 fct_shuffle(): 水準の順番をランダム化する
あまり使わない機能ですが、水準の順番をランダム化することも可能です。使い方は非常に簡単で、fct_shuffle()に元の変数名を入れるだけです。たとえば、Score_dfのPrefの順番をランダム化し、Pref2として追加します。同じことをもう2回繰り返し、それぞれPref3とPref4という名前で追加してみましょう。
Score_df <- Score_df |>
mutate(Pref2 = fct_shuffle(Pref),
Pref3 = fct_shuffle(Pref),
Pref4 = fct_shuffle(Pref))
Score_df# A tibble: 9 × 5
Pref Score Pref2 Pref3 Pref4
<chr> <dbl> <fct> <fct> <fct>
1 京都府 3.68 京都府 京都府 京都府
2 兵庫県 3.54 兵庫県 兵庫県 兵庫県
3 千葉県 3.72 千葉県 千葉県 千葉県
4 和歌山県 3.97 和歌山県 和歌山県 和歌山県
5 埼玉県 3.64 埼玉県 埼玉県 埼玉県
6 大阪府 3.77 大阪府 大阪府 大阪府
7 奈良県 3.85 奈良県 奈良県 奈良県
8 東京都 3.67 東京都 東京都 東京都
9 神奈川県 3.53 神奈川県 神奈川県 神奈川県[1] "大阪府" "和歌山県" "埼玉県" "奈良県" "兵庫県" "東京都" "千葉県"
[8] "神奈川県" "京都府" [1] "埼玉県" "兵庫県" "奈良県" "大阪府" "和歌山県" "京都府" "神奈川県"
[8] "東京都" "千葉県" [1] "奈良県" "和歌山県" "神奈川県" "東京都" "京都府" "埼玉県" "千葉県"
[8] "兵庫県" "大阪府" PrefからPref4まで同じように見えますが、水準の順番が異なります (Prefはcharacter型だから水準がありません)。
16.2.8 fct_reorder(): 別の1変数の値を基準に水準の順番を変更する
fct_infreq()は出現頻度順に並び替える関数でしたが、それと似たような関数としてfct_reorder()があります。ただし、これは出現頻度を基準にするのではなく、ある変数の平均値が低い順、中央値が高い順などでソートされます。まずは使い方から確認します。
必要な引数が多いですね。解説よりも実際の例を見ながら説明します。今回もPrefをfactor変数にし、Pref_Rという列で格納しますが、平均予算が安い順でfactorの水準を決めたいと思います。
Warning: There was 1 warning in `mutate()`.
ℹ In argument: `Pref_R = fct_reorder(Pref, Budget, mean, na.rm = TRUE)`.
Caused by warning:
! `fct_reorder()` removing 5141 missing values.
ℹ Use `.na_rm = TRUE` to silence this message.
ℹ Use `.na_rm = FALSE` to preserve NAs.[1] "千葉県" "埼玉県" "奈良県" "兵庫県" "大阪府" "神奈川県" "和歌山県"
[8] "東京都" "京都府" Pref_Rの水準は千葉県、埼玉県、奈良県、…の順ですが、本当にそうでしょうか。group_by()とsummarise()などを使って確認してみましょう。
df |>
group_by(Pref) |>
summarise(Budget = mean(Budget, na.rm = TRUE),
.groups = "drop") |>
arrange(Budget)# A tibble: 9 × 2
Pref Budget
<chr> <dbl>
1 千葉県 1124.
2 埼玉県 1147.
3 奈良県 1169.
4 兵庫県 1197.
5 大阪府 1203.
6 神奈川県 1239.
7 和歌山県 1252
8 東京都 1283.
9 京都府 1399.問題なくソートされましたね。注意点としてはfct_reorder()内に関数名を書く際、()は不要という点です。関数名の次の引数としてはその関数に別途必要な引数を指定します。引数が省略可能、あるいは不要な関数を使う場合は、省略しても構いませんし、数に制限はありません。
また、低い順ではなく、高い順にすることも可能です。次はScoreの中央値が高い順に水準を設定したPref_R2を作ってみましょう。
Warning: There was 1 warning in `mutate()`.
ℹ In argument: `Pref_R2 = fct_reorder(Pref, Score, median, na.rm = TRUE, .desc
= TRUE)`.
Caused by warning:
! `fct_reorder()` removing 5158 missing values.
ℹ Use `.na_rm = TRUE` to silence this message.
ℹ Use `.na_rm = FALSE` to preserve NAs.[1] "和歌山県" "奈良県" "千葉県" "大阪府" "東京都" "埼玉県" "京都府"
[8] "兵庫県" "神奈川県"変わったのはmeanの代わりにmedianを使ったこと、そして.desc引数が追加された点です。fct_reorder()には.desc = FALSEがデフォルトとして指定されており、省略した場合は昇順でfactorの水準が決まります。ここで.desc = TRUEを指定すると、降順となります。実際、Scoreの中央値順になっているかを確認してみましょう。
16.2.9 fct_reorder2(): 別の2変数の値を基準に水準の順番を変更する
この関数は別の変数を基準に水準が調整される点ではfct_reorder()と類似しています。ただし、よく誤解されるのは「変数Aの値が同じなら変数Bを基準に…」といったものではありません。たとえば、fct_reorder(x, y, mean)の場合、yの平均値 (mean())の順でxの水準を調整するという意味です。このmean()関数に必要なデータはベクトル1つです。しかし、関数によっては2つの変数が必要な場合があります。
これは頻繁に直面する問題ではありませんが、このfct_reorder2()関数が活躍するケースを紹介します。以下は6月27日から7月1日までの5日間、5地域におけるCOVID-19新規感染者数を表したデータです2。入力が面倒な方はここからダウンロードして読み込んでください。
# 入力が面倒ならデータをダウンロードし、
# Reorder2_df <- read_csv("Data/COVID19.csv")
Reorder2_df <- tibble(
Country = rep(c("日本", "韓国", "中国 (本土)", "台湾", "香港"),
each = 5),
Date = rep(c("2020/06/27", "2020/06/28", "2020/06/29",
"2020/06/30", "2020/07/01"), 5),
NewPat = c(100, 93, 86, 117, 130,
62, 42, 43, 50, 54,
17, 12, 19, 3, 5,
0, 0, 0, 0, 0,
1, 2, 4, 2, 28)
)
Reorder2_df <- Reorder2_df |>
mutate(Date = as.Date(Date))
Reorder2_df# A tibble: 25 × 3
Country Date NewPat
<chr> <date> <dbl>
1 日本 2020-06-27 100
2 日本 2020-06-28 93
3 日本 2020-06-29 86
4 日本 2020-06-30 117
5 日本 2020-07-01 130
6 韓国 2020-06-27 62
7 韓国 2020-06-28 42
8 韓国 2020-06-29 43
9 韓国 2020-06-30 50
10 韓国 2020-07-01 54
# ℹ 15 more rows可視化のコードはとりあえず無視し、グラフを出力してみましょう。
Reorder2_df |>
ggplot() +
geom_line(aes(x = Date, y = NewPat, color = Country),
size = 1) +
scale_x_date(date_labels = "%Y年%m月%d日") +
labs(x = "年月日", y = "新規感染者数 (人)", color = "")Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.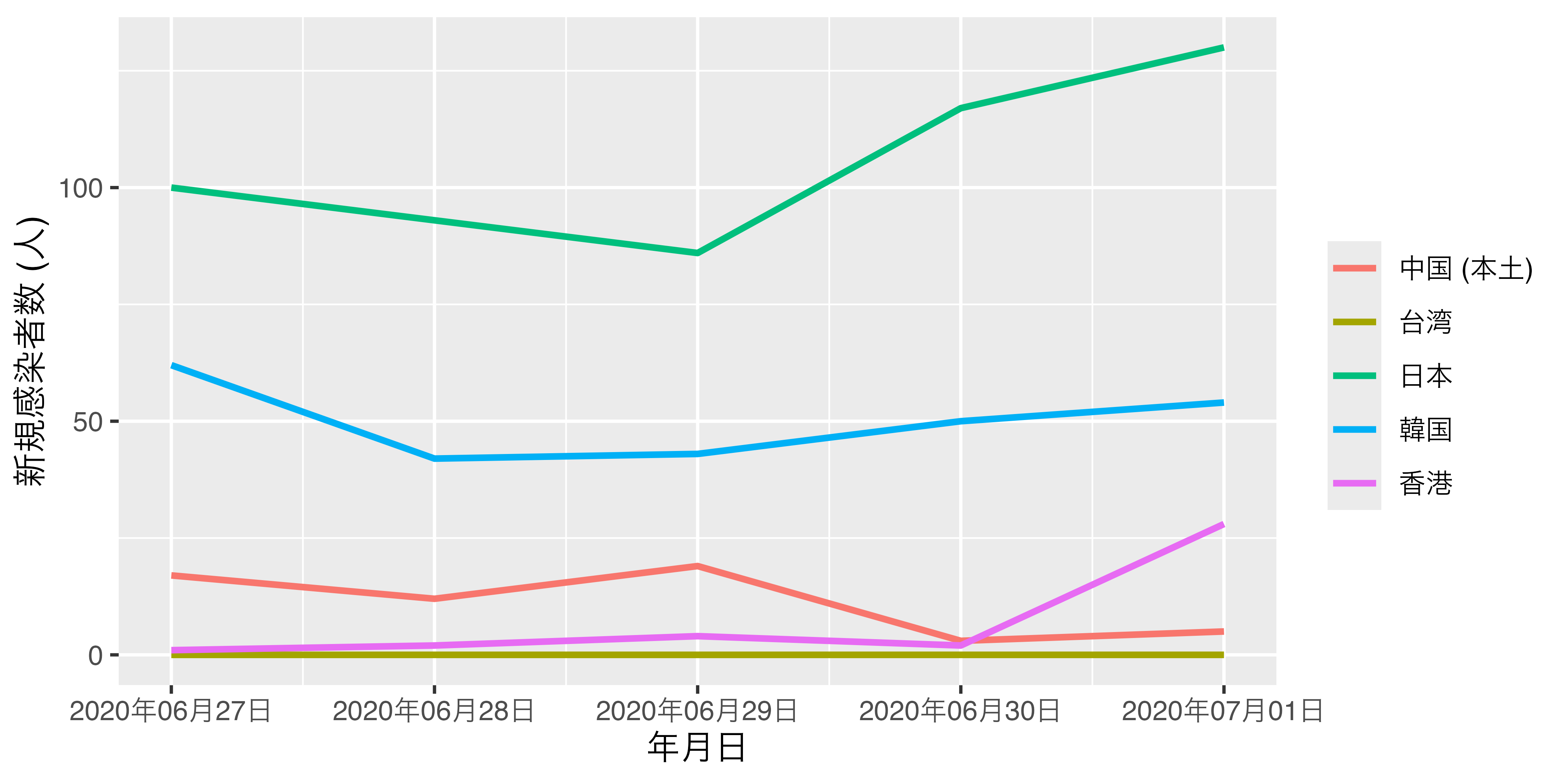
このグラフに違和感はあまりありませんが、「読みやすさ」の麺では改善の余地があります。たとえば、7月1日の時点で、新規感染者数が多いのは日本、韓国、香港、中国 (本土)、台湾の順です。しかし、右側の凡例の順番はそうではありません。この順番が一致すれば、更に図は読みやすくなるでしょう。
[1] 日本 日本 日本 日本 日本 韓国
[7] 韓国 韓国 韓国 韓国 中国 (本土) 中国 (本土)
[13] 中国 (本土) 中国 (本土) 中国 (本土) 台湾 台湾 台湾
[19] 台湾 台湾 香港 香港 香港 香港
[25] 香港
Levels: 中国 (本土) 台湾 日本 韓国 香港実際、何も指定せずにReorder2_dfのCountryをfactor化すると、韓国、香港、台湾、…の順であり、これは上のグラフと一致します。これをグラフにおける7月1日の新規感染者数の順で並べるためには、Dateを昇順にソートし、そして最後の要素 ("2020/07/01")内で新規感染者数 (NewPat)を降順に並べ替えた場合の順番にする必要があります。実際、Reorder2_dfをDateで昇順、NewPatで降順にソートし、最後の5行を抽出した結果が以下のコードです。
# A tibble: 5 × 3
Country Date NewPat
<chr> <date> <dbl>
1 日本 2020-07-01 130
2 韓国 2020-07-01 54
3 香港 2020-07-01 28
4 中国 (本土) 2020-07-01 5
5 台湾 2020-07-01 0このように、水準を調整する際に2つの変数 (DateとNewPat)が使用されます。fct_reorder2()はfct_reorder()と買い方がほぼ同じですが、基準となる変数がもう一つ加わります。
重要なのはここの関数のところですが、fct_reorder2()はデフォルトでlast2()という関数が指定されており、まさに私たちに必要な関数です。したがって、ここでは関数名も省略できますが、ここでは一応明記しておきます。
それでは新しく出来たCountry2の水準を確認してみましょう。
ちゃんと7月1日の新規感染者数基準で水準の順番が調整されましたので、これを使ってグラフをもう一回作ってみます。
Reorder2_df |>
ggplot() +
geom_line(aes(x = Date, y = NewPat, color = Country2),
size = 1) +
scale_x_date(date_labels = "%Y年%m月%d日") +
labs(x = "年月日", y = "新規感染者数 (人)", color = "")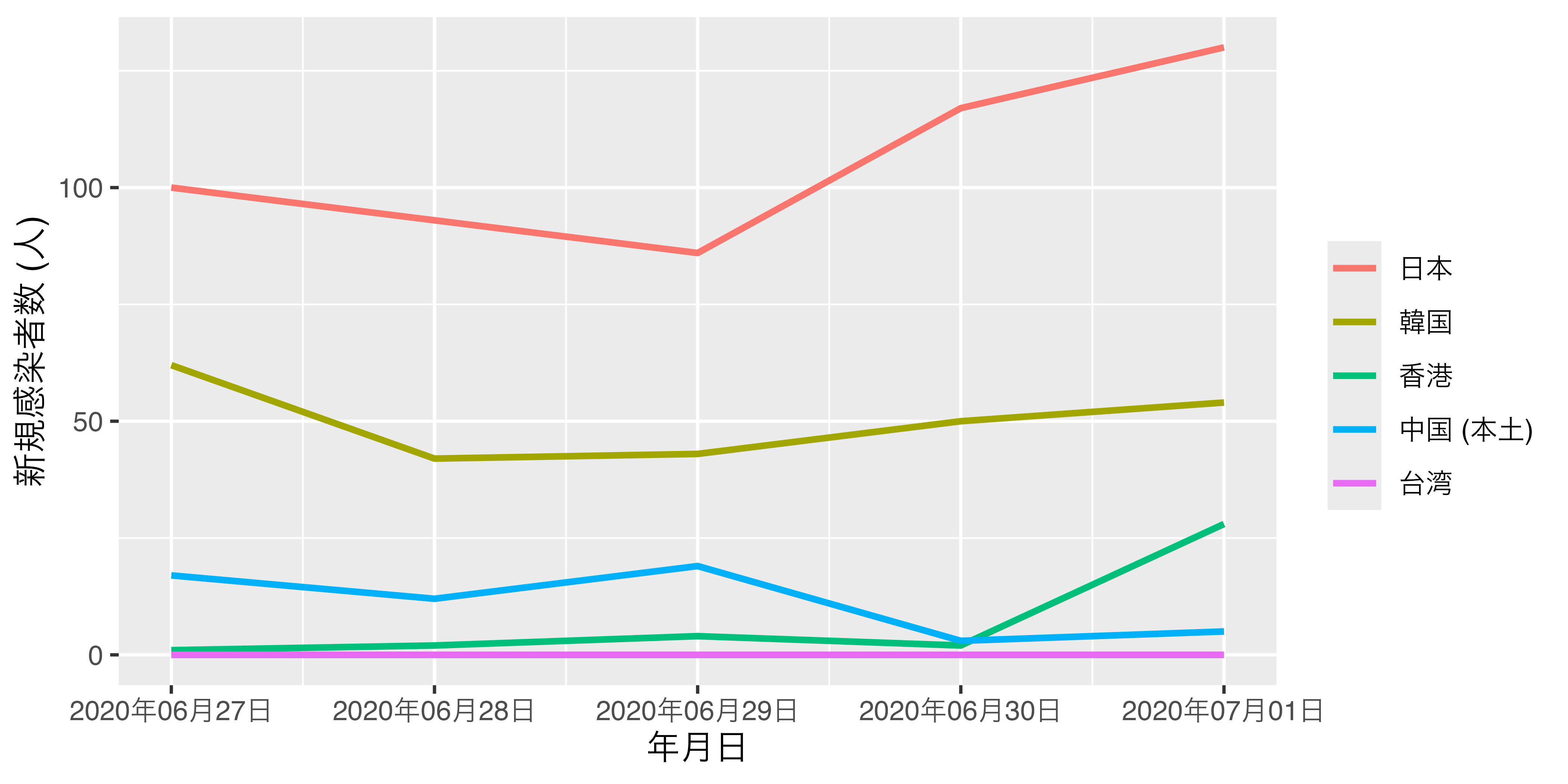
これで図がさらに読みやすくなりました。ちなみに、{forcatsパッケージはlast2()以外にもfirst2()という関数も提供しております。これを使うと、7月1日でなく、6月27日の新規感染者数の降順で水準の順番が調整されます。他にも引数を2つ使用する自作関数も使えますが、fct_reorder2()の主な使いみちはlast2()で十分でしょう。
16.2.10 fct_collapse(): 水準を統合する
水準数をより水準数に減らすためには、fct_recode()を使います。先ほど、fct_shift()で使ったdf4の例を考えてみましょう。df4のQ1の水準数は6つです。
これを4つに減らして見ましょう。具体的には「そう思う」と「どちらかと言えばそう思う」を「そう思う」に、「そう思わない」と「どちらかと言えばそう思わない」を「そう思わない」に統合します。これをfct_recode()で処理したのが以下のコードです。
# fct_recode()を使った例
df4 <- df4 |>
mutate(Q1_R2 = fct_recode(Q1,
そう思う = "そう思う",
そう思う = "どちらかと言えばそう思う",
どちらとも言えない = "どちらとも言えない",
そう思わない = "どちらかと言えばそう思わない",
そう思わない = "そう思わない",
答えたくない = "答えたくない"))
df4# A tibble: 10 × 4
ID Q1 Q1_R Q1_R2
<int> <fct> <fct> <fct>
1 1 そう思う そう思う そう思う
2 2 そう思わない そう思わない そう思わない
3 3 どちらとも言えない どちらとも言えない どちらとも言…
4 4 どちらかと言えばそう思う どちらかと言えばそう思う そう思う
5 5 答えたくない 答えたくない 答えたくない
6 6 どちらかと言えばそう思う どちらかと言えばそう思う そう思う
7 7 どちらかと言えばそう思わない どちらかと言えばそう思わない そう思わない
8 8 答えたくない 答えたくない 答えたくない
9 9 そう思わない そう思わない そう思わない
10 10 そう思う そう思う そう思う [1] "そう思う" "どちらとも言えない" "そう思わない"
[4] "答えたくない" しかし、水準を統合するに特化したfct_collapse()を使えばより便利です。使い方は、fct_recode()に非常に似ているため省略しますが、=の右側をc()でまとめることが出来ます。
# fct_collapse()を使った例
df4 <- df4 |>
mutate(Q1_R3 = fct_collapse(Q1,
そう思う = c("そう思う", "どちらかと言えばそう思う"),
どちらとも言えない = "どちらとも言えない",
そう思わない = c( "どちらかと言えばそう思わない", "そう思わない"),
答えたくない = "答えたくない"))
df4# A tibble: 10 × 5
ID Q1 Q1_R Q1_R2 Q1_R3
<int> <fct> <fct> <fct> <fct>
1 1 そう思う そう思う そう思… そう…
2 2 そう思わない そう思わない そう思… そう…
3 3 どちらとも言えない どちらとも言えない どちら… どち…
4 4 どちらかと言えばそう思う どちらかと言えばそう思う そう思… そう…
5 5 答えたくない 答えたくない 答えた… 答え…
6 6 どちらかと言えばそう思う どちらかと言えばそう思う そう思… そう…
7 7 どちらかと言えばそう思わない どちらかと言えばそう思わない そう思… そう…
8 8 答えたくない 答えたくない 答えた… 答え…
9 9 そう思わない そう思わない そう思… そう…
10 10 そう思う そう思う そう思… そう…[1] "そう思う" "どちらとも言えない" "そう思わない"
[4] "答えたくない" fct_recode()の結果と同じ結果が得られました。元の水準数や、減らされる水準数などによっては書く手間があまり変わらないので、好きな方を使っても良いでしょう。
16.2.11 fct_drop(): 使われていない水準を除去する
水準としては存在するものの、データとしては存在しないケースもあります。これをここでは「空水準 (empty levels)」と呼びます。たとえば、以下のコードはPrefをfactor化してからPref == "奈良県"のケースを落としたものです。
Score_df_f2 <- df |>
mutate(Pref = fct_inorder(Pref)) |>
filter(Pref != "奈良県") |>
group_by(Pref) |>
summarise(Score = mean(Score, na.rm = TRUE),
.groups = "drop")
Score_df_f2# A tibble: 8 × 2
Pref Score
<fct> <dbl>
1 東京都 3.67
2 神奈川県 3.53
3 千葉県 3.72
4 埼玉県 3.64
5 大阪府 3.77
6 京都府 3.68
7 兵庫県 3.54
8 和歌山県 3.97このように結果としては、奈良県のデータを除外したため空水準である奈良県は表示されませんが、Pref変数はどうでしょうか。
このように水準としては残っていることが分かります。使われていない水準が分析や可視化に影響を与えないケースもありますが、与えるケースもあります。これもこれまで勉強してきたfct_*()関数群で対応可能ですが、fct_drop()関数を使えば一発で終わります。実際にやってみましょう。
水準から奈良県が消えました。同じ機能をする関数としてはR内蔵関数であるdroplevels()関数があり、使い方はfct_drop()と同じです。
16.2.12 fct_expand(): 水準を追加する
一方、空水準を追加することも可能です。fct_expand()関数には元の変数名に加え、追加する水準名を入れるだけです。たとえば、dfのPrefの水準は関東と関西の9都府県名となっていますが、ここに"滋賀県"という水準を追加してみます。。
[1] "京都府" "兵庫県" "千葉県" "和歌山県" "埼玉県" "大阪府"
[7] "奈良県" "東京都" "神奈川県" "滋賀県" "滋賀県"という新しい水準が出来ましたね。ただし、新しく追加された水準は最後の順番になりますので、修正が必要な場合はfct_relevel()などを使って適宜修正してください。
新しく水準が追加されることによって、何かの変化はあるでしょうか。まずは都府県ごとにScoreの平均値とケース数を計算してみましょう。
# A tibble: 9 × 3
Pref Score N
<fct> <dbl> <int>
1 京都府 3.68 414
2 兵庫県 3.54 591
3 千葉県 3.72 1000
4 和歌山県 3.97 140
5 埼玉県 3.64 1000
6 大阪府 3.77 1000
7 奈良県 3.85 147
8 東京都 3.67 1000
9 神奈川県 3.53 1000見た目は全く変わらず、滋賀県の行が新しく出来たわけでもありません。{dplyr}のgroup_by()の場合、空水準はグループ化の対象になりません。一方、多くのR内蔵関数はケースとして存在しなくても計算の対象となります。たとえば、ベクトル内のある値が何個格納されているか確認するtable()関数の例を見てみましょう。
京都府 兵庫県 千葉県 和歌山県 埼玉県 大阪府 奈良県 東京都
414 591 1000 140 1000 1000 147 1000
神奈川県 滋賀県
1000 0 "滋賀県"という列があり、合致するケースが0と表示されます。group_by()でも空の水準まで含めて出力する引数.dropがあります。デフォルトはTRUEですが、これをFALSEに指定してみます。
df5 |>
group_by(Pref, .drop = FALSE) |>
summarise(Score = mean(Score, na.rm = TRUE),
N = n(),
.groups = "drop")# A tibble: 10 × 3
Pref Score N
<fct> <dbl> <int>
1 京都府 3.68 414
2 兵庫県 3.54 591
3 千葉県 3.72 1000
4 和歌山県 3.97 140
5 埼玉県 3.64 1000
6 大阪府 3.77 1000
7 奈良県 3.85 147
8 東京都 3.67 1000
9 神奈川県 3.53 1000
10 滋賀県 NaN 0空水準も出力され、Scoreの平均値は計算不可 (NaN)、ケース数は0という結果が得られました。
16.2.13 fct_explicit_na(): 欠損値に水準を与える
まずは、実習用データdf6を作ってみまます。X1はnumeric型変数ですが、これをfactor化します。最初からtibble()内でfactor化しておいても問題ありませんが、練習だと思ってください。
df6 <- tibble(
ID = 1:10,
X1 = c(1, 3, 2, NA, 2, 2, 1, NA, 3, NA)
)
df6 <- df6 |>
mutate(X1 = factor(X1,
levels = c(1, 2, 3),
labels = c("ラーメン", "うどん", "そば")))
df6# A tibble: 10 × 2
ID X1
<int> <fct>
1 1 ラーメン
2 2 そば
3 3 うどん
4 4 <NA>
5 5 うどん
6 6 うどん
7 7 ラーメン
8 8 <NA>
9 9 そば
10 10 <NA> それではX1をグループ化変数とし、ケース数を計算してみましょう。
# A tibble: 4 × 2
X1 N
<fct> <int>
1 ラーメン 2
2 うどん 3
3 そば 2
4 <NA> 3NAもグループ化の対象となります。以下はこの欠損値も一つの水準として指定する方法について紹介します。欠損値を欠損値のままにするケースが多いですが、欠損値が何らかの意味を持つ場合、分析の対象になります。たとえば、多項ロジスティック回帰の応答変数として「分からない/答えたくない」を含めたり、「分からない/答えたくない」を選択する要因を分析したい場合は、欠損値に値を与える必要があります。なぜなら、一般的な分析において欠損値は分析対象から除外されるからです。
まずは、これまで紹介した関数を使ったやり方から紹介します。
df6 |>
# まず、X1をcharacter型に変換し、X2という列に保存
mutate(X2 = as.character(X1),
# X2がNAなら"欠損値"、それ以外なら元のX2の値に置換
X2 = ifelse(is.na(X2), "欠損値", X2),
# X2を再度factor化する
X2 = factor(X2,
levels = c("ラーメン", "うどん", "そば", "欠損値")))# A tibble: 10 × 3
ID X1 X2
<int> <fct> <fct>
1 1 ラーメン ラーメン
2 2 そば そば
3 3 うどん うどん
4 4 <NA> 欠損値
5 5 うどん うどん
6 6 うどん うどん
7 7 ラーメン ラーメン
8 8 <NA> 欠損値
9 9 そば そば
10 10 <NA> 欠損値 X1をcharacter型に戻す理由3は、水準にない値が入るとfactor化が解除されるからです。factor型をcharacter型に戻さずにdf6$X1のNAを"欠損値"に置換すると、以下のようになります。
[1] "1" "3" "2" "欠損値" "2" "2" "1" "欠損値"
[9] "3" "欠損値""ラーメン"と"うどん"、"そば"がfactor化前の1, 2, 3に戻っただけでなく、NAが"欠損値"というcharacter型に置換されたため、全体がcharacter型に変換されました。このように欠損値に水準を与える作業は難しくはありませんが、面倒な作業です。そこで登場する関数がfct_exlpicit_na()関数です。使い方は、元の変数に加え、欠損値の水準名を指定するna_levelです。
Warning: There was 1 warning in `mutate()`.
ℹ In argument: `X2 = fct_explicit_na(X1, na_level = "欠損値")`.
Caused by warning:
! `fct_explicit_na()` was deprecated in forcats 1.0.0.
ℹ Please use `fct_na_value_to_level()` instead.# A tibble: 10 × 3
ID X1 X2
<int> <fct> <fct>
1 1 ラーメン ラーメン
2 2 そば そば
3 3 うどん うどん
4 4 <NA> 欠損値
5 5 うどん うどん
6 6 うどん うどん
7 7 ラーメン ラーメン
8 8 <NA> 欠損値
9 9 そば そば
10 10 <NA> 欠損値 欠損値が一つの水準になったことが分かります。
# A tibble: 4 × 2
X2 N
<fct> <int>
1 ラーメン 2
2 うどん 3
3 そば 2
4 欠損値 3むろん、group_by()を使ってもちゃんと出力されます。