[1] 6[1] 16 ここからは実際にRを使ってみよう。まず、新しい R Script を開くために、Cmd/Ctrl + Shift + N を入力する1(“File” メニューから “New File” - “R Script” を選んでも良い)。すると、 左上の Source Pane に “Untitled1” というタブが登場し、その pane 上でコードが入力できるようになる。ここで 3 + 3 と入力し、その行にカーソルを留めたまま command + return(Mac)または Ctrl + Enter を押してみよう。command + return というのは、command キーを押したまま、return キーも押すという意味である。
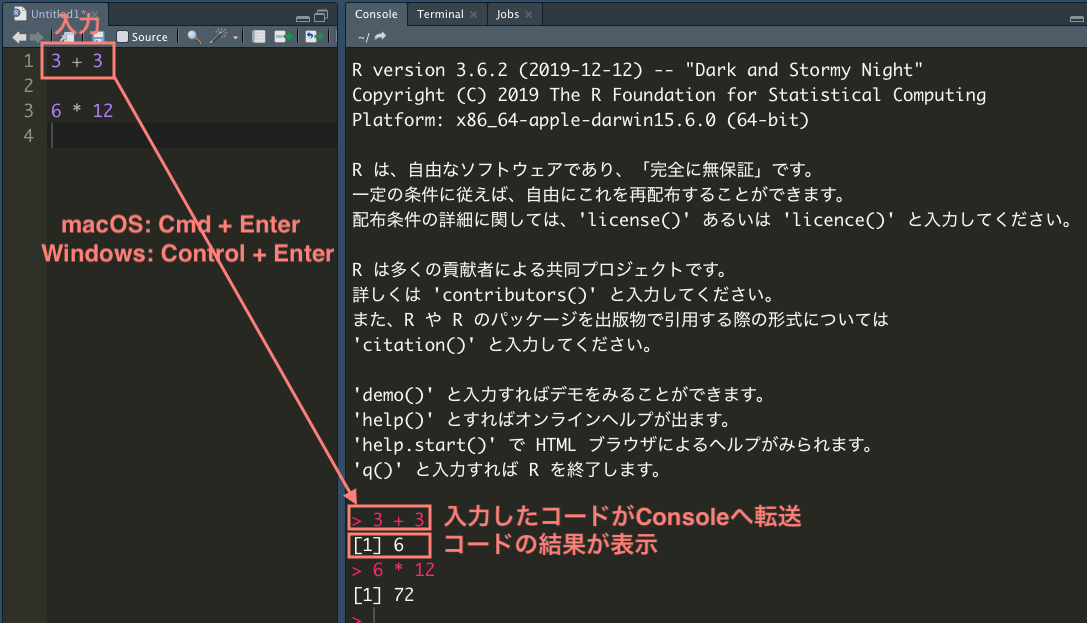
Source ペイン (Untitled1) に入力したコードが Console(本書第4章の説明どおりにカスタマイズしていれば、RStudio 内の右上画面)に転送され、計算結果が表示される。Rのコードは Console に直接打ち込むこともできるが、Sourceペインに入力してから Console に転送する方法が基本である2。 Source ペインの内容をファイルに保存すれば、後でもう1度同じコードを実行したり、コードを他のプロジェクトで再利用することができるようになる。先ほど 3 + 3 を入力した画面にカーソルを合わせ、Cmd/Ctrl + S を押してみよう。ファイルの保存を促されるので、ファイル名をつけて保存しよう。このとき、.R というファイル名拡張子を付ける。これにより、ファイルがRスクリプトとして認識される。例えば、“practice01.R” という名前をつけて保存しよう。Sourceペインの上部に表示されるタブの名前が、“Untitled1” から “practice01.R” に変わることが確認できるはずだ。
以下にRで計算する例を示すので、コードを practice01.R に入力し、command + return (Ctrl + Enter) で Console に送り、実行結果を確認しよう。背景が灰色になっている部分に示されているのが、Rのコマンドである。ただし、##から始まる部分は計算結果である。また、コードブロックのうち、 #(ハッシュ記号)で始まる部分はコメントであり、Rで評価(計算)されない。コメントの使い方については第F章で詳しく解説する。
まずは、簡単な足し算と掛け算を実行してみよう。
これ以外の基本的な演算に使う記号とその簡単な使い方は以下のとおりである。
| 演算子 | 意味 | 例 | 結果 |
|---|---|---|---|
+ |
和 | 2 + 5 |
7 |
- |
差 | 2 - 8 |
-6 |
* |
積 | 7 * 3 |
21 |
/ |
商 | 16 / 5 |
3.2 |
^、** |
累乗(べき乗) | 2^3または2 ** 3 |
8 |
%% |
剰余 (モジュロ) | 18 %% 7 |
4 |
%/% |
整数商 | 18 %/% 7 |
2 |
論理演算子とは、入力した式が真か偽かを判定する演算子である。返り値(戻り値)は TRUE(真の場合)または FALSE(偽の場合)のいずれかとなる。たとえば、「3 > 2」は真なので、TRUE が返される。しかし、「2 + 3 = 1」は偽なので、FALSEが返される。実際にやってみよう。
このように、等しいかどうかを表す記号は = ではなく ==(二重等号)なので注意されたい。
論理演算子にも、いくつかの種類がある。
| 演算子 | 意味 | 例 | 結果 | |
|---|---|---|---|---|
| 1 | x < y |
xはyより小さい |
3 < 1 |
FALSE |
| 2 | x <= y |
xはyと等しいか、小さい |
2 <= 2 |
TRUE |
| 3 | x > y |
xはyより大きい |
6 > 5 |
TRUE |
| 4 | x >= y |
xはyと等しいか、大きい |
4 >= 5 |
FALSE |
| 5 | x == y |
xとyは等しい |
(2 + 3) == (4 + 1) |
TRUE |
| 6 | x != y |
xとyは等しくない |
((2 * 3) + 1) != (2 * (3 + 1)) |
TRUE |
6番目の例について少し説明する。通常の数式同様、Rも括弧()内の記述を優先的に計算する。したがって、!=左側の((2 * 3) + 1) は 6 + 1 = 7 であり、右側の (2 * (3 + 1)) は 2 * 4 = 8 である。したがって、7 != 8 が判定対象となり、TRUEが返される。! 記号は、「否定」を表すために使われるもので、!= は左右が等しくないときに TRUE を返す
上に挙げた論理演算子は基本的に数字を対象に使うが、TRUEとFALSE を対象に使うものもある。それが and を表す & と or を表す| である。。& は、& を挟む左右の両側が TRUE の場合のみ TRUE を返し、| は少なくとも一方が TRUE なら TRUE を返す。
| 演算子 | 意味 | 例 | 結果 | |
|---|---|---|---|---|
| 1 | x | y |
xまたはy |
(2 + 3 == 5) | (1 * 2 == 3) |
TRUE |
| 2 | x & y |
xかつy |
(2 + 3 == 5) & (1 * 2 == 3) |
FALSE |
1番の例では、|の左側は(2 + 3 == 5)であり、TRUE である。一方、右側の(1 * 2 == 3) は FALSE だ。判定対象はTRUE | FALSE となり、TRUE が返される。 2番目の例は TRUE & FALSE なので、返り値は FALSE になる。
123454321 * 2 を計算しよう。123454321 * 3 を計算しよう。123454321 * 4 を計算しよう。 これらの計算は簡単にできるだろう。しかし、123454321を3回入力するのが面倒だっただろう3。123454321という数字をxとかaに代入し、数字の代わりに x や a が使えるなら、上の計算は楽になる。ここではその方法を説明する。
xというものに123454321という数字を入れるには、<- という演算子を使う。この演算子により、xという名のもの (オブジェクト)に123454321という数字を代入することができる。ここでは「代入」という表現を使ったが4、<-の役割は代入よりも広いので、これからは「格納」という表現を使う。
<- は、< と- という2つの記号をスペースなしで入力することで作ることができる。 RStudioでは、 option + - [マイナス, ハイフン] (macOS の場合) または Alt + - (Windows の場合)で、<- が入力できる。その際、演算子の前後に半角スペースが1つずつ挿入されるので、このショートカットは必ず使うべきである。
Rを起動した時点では、x というオブジェクトは存在しない。RStudio 右下のペインにある Environment タブを開くと、現時点では何も表示されていないはずだ。しかし、x に何かを格納することで、x というオブジェクトができる。 実際に xに、123454321を格納してみよう。
Environment タブに、x が登場し、格納した数字が右側に表示されていることが確認できるだろう。
オブジェクトの中身は、オブジェクト名をそのまま入力することで表示できる。
print(x) でも同じ結果が得られるが、タイプする文字数を減らしたいので xのみにする。ただし、状況やオブジェクトの型(型については後で詳しく説明する)によっては、print() を使わないと中身が表示されない(あるいは意図したとおりに見えない)場合もあるので、R Markdown やQuarto ファイルで論文などを作成していて、結果を確実に表示したい場合には print(x) とするほうが安全である。
ちなみに、格納と同時にそのオブジェクトの中身を表示することもできる。そのためには、格納コマンド全体を() で囲む。例えば、次のようにする。
値が格納されたオブジェクトは計算に利用できるので、先ほどの計算は、次のようにできる。
文字列を格納することもできる。ただし、文字列は必ず "" か '' で囲む必要がある。
オブジェクトに格納できるのは1つの数値や文字列だけではない。複数の数値や文字列を格納することもできる。そのためには c() という関数を使う。c() のc は concatenate または combine の頭文字で、複数の要素からベクトル (vector) を作るのに使われる関数である。 c() に含む要素はカンマ (,) で区切る。
[1] 73 6 5 3 99 10 22 9 7複数の文字列を格納することもできる。
[1] "cat" "cheetah" "lion" "tiger" ひとつひとつの要素を指定する代わりに、様々な方法でベクトルを作ることが可能である。 たとえば、seq() 関数を使うと、一連の数字からなるベクトルを作ることができる。from で数列の初項を、to で数列の最終項を指定し、by で要素間の差(第2要素は第1要素に by を加えた値になる )を指定するか、length.out で最終的にできるベクトルの要素の数を指定する。Rのベクトルの length(長さ) とは、要素の数のことなので、注意されたい。
いくつか例を挙げる。
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20[1] 11 13 15 17 19 [1] 2 4 6 8 10 12 14 16 18 20[1] 20 15 10 5 [1] 1 12 23 34 45 56 67 78 89 100[1] 73 72 71 70 69 68 67 66 このように1つの関数でも指定する内容は、by になったりlength.out になったりする。by や length.out、from、to などのように、関数で指定する対象になっているもののことを 仮引数 (parameter) と呼ぶ。また、by = 1 の1や、length.out = 10 の10のように、仮引数に実際に渡される値のことを実引数 (argument) と呼ぶ。特に誤解が生じないと思われる場合には、仮引数と実引数を区別せずに引数(ひきすう)と呼ぶ。 Rでは、1つの関数で使う引数の数が複数あることが多いので、仮引数を明示する習慣を身につけたほうがよい。 ただし、第1引数(関数で最初に指定する引数)として必ず入力すべきものは決められている場合がほとんどなので、第1引数の仮引数は省略されることが多い。仮引数が省略される代わりに、第1引数の実引数はほぼ必ず入力する(いくつかの例外もある)。
seq(from = x, to = y, by = 1) の場合はより単純に x:y とすることができる。
[1] 21 22 23 24 25 26 27 28 29 30 [1] 10 9 8 7 6 5 4 3 2 1 また、rep() 関数も便利である。例を挙げよう。
[1] 3 3 3 3 3 3 3 3 3 3[1] "a" "a" "a" "b" "c" "c"[1] "C" "C" "A" "A" "T" "T"アルファベットのベクトルは、あらかじめ用意されている。
オブジェクト名(ベクトル)の後に [抽出する要素のインデクス] を付けると、ベクトルの特定の要素を抽出することができる。ちなみに [ は関数である。Console にhelp("[") と打てば、これが Extract と言う名前の関数であることがわかる(help("[]") ではないので注意)。
ベクトルの要素を取り出してみよう。Rのインデクスは、他の多くのプログラミング言語(例えば、C, C++, Pythonなど)とは異なり「1」から始まるので注意されたい。
[1] 99[1] 6 3 10[1] 6 5 99 10 22 9 7[1] 99 10 22 c()や:だけでなく、seq()も使える。
[1] 1 3 5 7 9 11 13 15 17 19 さらに、TRUEとFALSEを使うこともできる。この場合、抽出したい要素の場所を指定するのではなく、それぞれの場所について抽出する (TRUE) か、しない (FALSE) かを指定する。たとえば、character_vecから1, 3, 4番目の要素を抽出するなら、[c(TRUE, FALSE, TRUE, TRUE)]と指定する。
TRUEとFALSEが使えるので、論理演算子を[]の中で使うこともできる。たとえば、numeric_vec1の各要素が偶数かどうかを判定するためには、インデックスが2で割り切れるかどうか(2で割った余りが0かどうか)を確認すれば良い。
これを利用すれば、numeric_vec1から偶数のみを抽出できる。
[ と格納(代入)を組み合わせれば、「ベクトルの一部の要素を書き換える」ことができる。たとえば、numeric_vec1の2番目の要素は5だが、これを100に書き換えたい場合、置換したい要素の場所を[]で指定し、<-で代入すれば良い。
複数の要素を置換することもできる。たとえば、偶数を全て0に置換したい場合、以下のようにする。