# A tibble: 3,000 × 48
USER_ID Q1 Q2 Q3 Q4 Q5_1 Q5_2 Q5_3 Q5_4 Q5_5 Q5_6 Q5_7 Q5_8 Q5_9 Q5_10 Q5_11
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 3 3 1 1 80 80 70 50 40 20 50 45 20 30 30
2 2 2 2 2 8 0 25 30 30 60 30 10 20 20 10 50
3 3 3 1 1 8 80 10 0 0 0 0 75 0 0 0 0
4 4 3 3 1 1 100 50 0 0 50 0 100 50 0 0 50
5 5 3 3 2 3 70 40 40 50 30 20 70 40 40 50 30
6 6 3 1 1 1 100 0 0 0 0 0 100 0 0 0 0
7 7 3 3 1 6 100 10 20 10 10 10 50 10 20 20 10
8 8 3 1 1 6 80 0 60 55 0 0 90 0 5 10 0
9 9 3 1 1 1 100 50 100 75 50 25 100 50 75 75 50
10 10 3 3 1 8 25 25 25 25 55 50 50 20 25 30 55
# ℹ 2,990 more rows
# ℹ 32 more variables: Q5_12 <dbl>, Q6_1 <dbl>, Q6_2 <dbl>, Q6_3 <dbl>, Q6_4 <dbl>, Q6_5 <dbl>,
# Q7 <dbl>, Q8 <dbl>, Q9 <dbl>, Q10_1 <dbl>, Q10_2 <dbl>, Q10_3 <dbl>, Q10_4 <dbl>, Q10_5 <dbl>,
# Q10_6 <dbl>, Q10_7 <dbl>, Q10_8 <dbl>, Q11 <dbl>, Q12 <dbl>, Q12S1 <dbl>, Q13 <dbl>,
# Q13S1 <dbl>, Q13S2 <dbl>, Q14 <dbl>, Q14S1 <dbl>, Q15 <dbl>, Q15S1 <dbl>, Q15S2 <dbl>,
# Q61 <dbl>, gender <dbl>, age <dbl>, chiiki <dbl>マクロ政治データ分析実習
3/ 記述統計
宋 財泫
関西大学総合情報学部
本日の内容
- 記述統計とは何か。
- どの変数にどの記述統計量を求めるべきか。
- 記述統計量をどう報告するか。
- Rの復習
- 前期履修者でも数ヶ月はRを触っていないはずなので、ウォーミングアップ
- ゼロベースの解説ではない(Rの導入やデータの読み込みなどは解説しない)。
変数の種類と記述統計
記述統計
記述統計量(descriptive statistics)
- ある変数が持つ情報を要約した数値
- データ分析を用いる論文、レポートにはデータ分析の結果を紹介する前に必ず分析に用いる変数の記述統計量が必要
- 記述統計量の種類
- 各変数を代表する値:平均値、中央値、最頻値
- 値の散らばり具合:標準偏差、分散、範囲(最大値 - 最小値)、四分位範囲など
記述統計量の必要性
通常、データ分析で用いるケースは数百〜数万であるため、一つずつ列挙することはほぼ不可能であり、記述統計量を用いた方が効率的
- 例1) あるクラス(3人)の数学成績が82点、45点、69点なら
- 「うちのクラスの数学成績は82点、45点、69点です!」で良い
- 例2) あるクラス(30人)の数学成績が82点、45点、69点、94点、…、63点なら
- 「うちのクラスの数学成績は82点、45点、69点、94点、…、63点です!」は長い
- こんな人と友達になりたくない。
- 「うちのクラスの数学成績は平均して75点で、標準偏差は8点です。」
- 「うちのクラスの数学成績は82点、45点、69点、94点、…、63点です!」は長い
実習の準備
パッケージとデータの読み込み(データはLMSから入手可能)
データの確認
データの大きさ(行数と列数)の確認
変数名の確認
[1] "USER_ID" "Q1" "Q2" "Q3" "Q4" "Q5_1" "Q5_2" "Q5_3" "Q5_4"
[10] "Q5_5" "Q5_6" "Q5_7" "Q5_8" "Q5_9" "Q5_10" "Q5_11" "Q5_12" "Q6_1"
[19] "Q6_2" "Q6_3" "Q6_4" "Q6_5" "Q7" "Q8" "Q9" "Q10_1" "Q10_2"
[28] "Q10_3" "Q10_4" "Q10_5" "Q10_6" "Q10_7" "Q10_8" "Q11" "Q12" "Q12S1"
[37] "Q13" "Q13S1" "Q13S2" "Q14" "Q14S1" "Q15" "Q15S1" "Q15S2" "Q61"
[46] "gender" "age" "chiiki" データの加工(変数の抽出)
分析に使用する変数だけを残し、新しいオブジェクトとして格納
select()関数で列(=変数)抽出と変数名変更を同時に行う。
# A tibble: 3,000 × 8
ID Gender Age Education Voted VotedParty T_Jimin T_Minshin
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 2 69 4 1 7 50 30
2 2 2 47 3 2 NA 10 50
3 3 2 37 99 1 1 75 0
4 4 1 51 4 1 1 100 50
5 5 1 38 99 2 NA 70 30
6 6 1 71 2 1 1 100 0
7 7 1 47 3 1 7 50 10
8 8 1 71 2 1 1 90 0
9 9 1 75 4 1 1 100 50
10 10 2 66 3 1 2 50 55
# ℹ 2,990 more rows連続変数の記述統計
連続変数(continuous variable)
間隔尺度、または比率尺度で測定された変数
- 量的変数の例: 年齢 (
Age)、感情温度 (T_JiminとT_Minshin)- 変数の尺度についてはミクロ政治データ分析実習の第6回を参照
- 量的変数の記述統計量(太字は掲載がほぼ必須の記述統計量)
- 平均値 (
mean()) - 中央値 (
median()) - 標準偏差 (
sd()) - 分散 (
var()) - 最小値 (
min()) - 最大値 (
max()) - 欠損値を除く有効ケース数 (Observation; Obs)
- 一部の変数に欠損値が含まれている場合は必須
- ただし、分析を行う場合、予め欠損値を含む行を削除 or 補完する場合が多い
- その他
- 平均値 (
記述統計の計算: Base Rの場合
記述統計の計算: {dplyr}を利用する
summarise()関数を使用
一つの表としてまとめる
論文、レポートに記述統計を掲載する際は一つの表としてまとめること
| 平均値 | 標準偏差 | 最小値 | 最大値 | |
|---|---|---|---|---|
| 年齢 | 47.340 | 15.628 | 18 | 75 |
| 感情温度: 自由民主党 | 41.130 | 28.015 | 0 | 100 |
| 感情温度: 民進党 | 34.248 | 25.947 | 0 | 100 |
{summarytools}の利用(1)
- {summarytools}の
descr()関数descr()内には記述統計を確認するdata.frame / tibbleのオブジェクト名- 数値型変数のみ記述統計量が出力される。
- 文字型変数(character型、factor型)の場合、予めダミー変数に変換しておく(後述)
Descriptive Statistics
df2
N: 3000
Age Education Gender T_Jimin T_Minshin Voted VotedParty
----------------- --------- ----------- --------- --------- ----------- --------- ------------
Mean 47.34 5.90 1.50 41.13 34.25 1.30 2.94
Std.Dev 15.63 16.12 0.50 28.02 25.95 0.53 2.21
Min 18.00 1.00 1.00 0.00 0.00 1.00 1.00
Q1 34.00 2.00 1.00 20.00 10.00 1.00 1.00
Median 47.00 3.00 2.00 50.00 40.00 1.00 2.00
Q3 61.00 4.00 2.00 60.00 50.00 2.00 5.00
Max 75.00 99.00 2.00 100.00 100.00 3.00 7.00
MAD 19.27 1.48 0.00 29.65 29.65 0.00 1.48
IQR 27.00 2.00 1.00 40.00 40.00 1.00 4.00
CV 0.33 2.73 0.33 0.68 0.76 0.41 0.75
Skewness -0.03 5.58 -0.01 0.02 0.16 1.56 0.82
SE.Skewness 0.04 0.04 0.04 0.04 0.04 0.04 0.05
Kurtosis -1.14 29.30 -2.00 -0.83 -0.81 1.53 -0.82
N.Valid 3000.00 3000.00 3000.00 3000.00 3000.00 3000.00 2208.00
N 3000.00 3000.00 3000.00 3000.00 3000.00 3000.00 3000.00
Pct.Valid 100.00 100.00 100.00 100.00 100.00 100.00 73.60{summarytools}の利用(2)
- 主要統計量のみ(
stats = ...)、行と列の交換(transpose = TRUE)、変数の順番は固定(order = "p")- 平均値(
mean)、標準偏差(sd)、最小値(min)、最大値(max)、有効ケース数(n.valid)
- 平均値(
Descriptive Statistics
df2
N: 3000
Mean Std.Dev Min Max N.Valid
---------------- ------- --------- ------- -------- ---------
Gender 1.50 0.50 1.00 2.00 3000.00
Age 47.34 15.63 18.00 75.00 3000.00
Education 5.90 16.12 1.00 99.00 3000.00
Voted 1.30 0.53 1.00 3.00 3000.00
VotedParty 2.94 2.21 1.00 7.00 2208.00
T_Jimin 41.13 28.02 0.00 100.00 3000.00
T_Minshin 34.25 25.95 0.00 100.00 3000.00欠損値の扱いについて
最終学歴(Education)は1〜4で測定されているものの、最大値が99(超高学歴の人ではない)
- ここでの99は欠損値(missing value)であり、必ず欠損値に変えておく必要がある(そうでないと分析結果がとんでもないものになってしまう)。
Educationの値が99ならNAに変更し、それ以外の場合は元の値とする。
- 事前に欠損値処理されているデータもあれば、そうでないデータもある。データを入手した場合は必ずコードブックに目を通しておくこと!
# A tibble: 3,000 × 8
ID Gender Age Education Voted VotedParty T_Jimin T_Minshin
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 2 69 4 1 7 50 30
2 2 2 47 3 2 NA 10 50
3 3 2 37 NA 1 1 75 0
4 4 1 51 4 1 1 100 50
5 5 1 38 NA 2 NA 70 30
6 6 1 71 2 1 1 100 0
7 7 1 47 3 1 7 50 10
8 8 1 71 2 1 1 90 0
9 9 1 75 4 1 1 100 50
10 10 2 66 3 1 2 50 55
# ℹ 2,990 more rows欠損値処理後の記述統計
Descriptive Statistics
df2
N: 3000
Mean Std.Dev Min Max N.Valid
---------------- ------- --------- ------- -------- ---------
Gender 1.50 0.50 1.00 2.00 3000.00
Age 47.34 15.63 18.00 75.00 3000.00
Education 3.11 0.89 1.00 4.00 2913.00
Voted 1.30 0.53 1.00 3.00 3000.00
VotedParty 2.94 2.21 1.00 7.00 2208.00
T_Jimin 41.13 28.02 0.00 100.00 3000.00
T_Minshin 34.25 25.95 0.00 100.00 3000.00カテゴリ変数の記述統計
カテゴリ変数(categorical variable)
カテゴリ変数:名目尺度で測定された変数(=名目変数)
- カテゴリ変数の例: 性別 (
Gender)、投票参加 (Voted)、投票先 (VotedParty)- 教育水準(
Education)のような順序変数は、連続変数としてもカテゴリ変数としても扱うことが可能
- 教育水準(
- 名目尺度は足し算、掛け算などができないため、平均値や標準偏差のような概念が存在しない。
カテゴリ変数の可視化
- 方法1: 度数分布表を作成する
- 事前にfactor化する
- 方法2: ダミー変数に変換し、量的変数と同じ扱い
- 記述統計の表を作成する場合は、ダミー変換後、量的変数同様に扱う
度数分布表の作成
Voted(投票有無)変数の度数分布表
- 値 (1, 2, 3, …)の意味は質問票、またはコードブックを参照
- カテゴリ変数が複数ある場合、一つ一つの変数に対し、度数分布表を作成する必要がある。
- \(\Rightarrow\) できれば、連続変数の記述統計表と一つにまとめたい。
カテゴリ変数のfactor化
VotedとVotedParty変数のfactor化(factor型変数:順序付きの文字型変数)
factor()関数を使用levels =には元の値を、labels =には各値に対応するラベルを指定
# A tibble: 3,000 × 10
ID Gender Age Education Voted VotedParty T_Jimin T_Minshin Voted_F VotedParty_F
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <fct> <fct>
1 1 2 69 4 1 7 50 30 投票 不明
2 2 2 47 3 2 NA 10 50 棄権 <NA>
3 3 2 37 NA 1 1 75 0 投票 自民
4 4 1 51 4 1 1 100 50 投票 自民
5 5 1 38 NA 2 NA 70 30 棄権 <NA>
6 6 1 71 2 1 1 100 0 投票 自民
7 7 1 47 3 1 7 50 10 投票 不明
8 8 1 71 2 1 1 90 0 投票 自民
9 9 1 75 4 1 1 100 50 投票 自民
10 10 2 66 3 1 2 50 55 投票 民進
# ℹ 2,990 more rowsカテゴリ変数のfactor化
投票 棄権 選挙権なし
2208 687 105
投票 棄権 選挙権なし
73.6 22.9 3.5
自民 民進 公明 維新 共産 その他 不明
880 439 113 220 173 24 359
自民 民進 公明 維新 共産 その他 不明
39.855072 19.882246 5.117754 9.963768 7.835145 1.086957 16.259058 論文・レポートでの掲載方法
値、度数、割合、累積割合を掲載
| 度数 (人) | 割合 (%) | 累積割合 (%) | |
|---|---|---|---|
| 1. 投票 | 2208 | 73.6 | 73.6 |
| 2. 棄権 | 687 | 22.9 | 96.5 |
| 3. 投票権なし | 105 | 3.5 | 100.0 |
ダミー変数
ある属性を備えているかどうかを示す変数
- 特定のカテゴリの属している場合は1、属さない場合は0の値をとる二値変数
ダミー変換前
| ID | Voted_F |
|---|---|
| 39 | 投票 |
| 40 | 選挙権なし |
| 41 | 投票 |
| 42 | 投票 |
| 46 | 投票 |
| 47 | 棄権 |
| 48 | 投票 |
| 53 | 選挙権なし |
| 54 | 棄権 |
ダミー変換後
| ID | Voted_F | 投票 | 棄権 | 選挙権なし |
|---|---|---|---|---|
| 39 | 投票 | 1 | 0 | 0 |
| 40 | 選挙権なし | 0 | 0 | 1 |
| 41 | 投票 | 1 | 0 | 0 |
| 42 | 投票 | 1 | 0 | 0 |
| 46 | 投票 | 1 | 0 | 0 |
| 47 | 棄権 | 0 | 1 | 0 |
| 48 | 投票 | 1 | 0 | 0 |
| 53 | 選挙権なし | 0 | 0 | 1 |
| 54 | 棄権 | 0 | 1 | 0 |
ダミー変数の作成(if_else()使用)
mutate()内にif_else()で作成
# A tibble: 3,000 × 6
ID Voted_F VotedParty_F Voted_F_Vote Voted_F_Absent Voted_F_Ineligible
<dbl> <fct> <fct> <dbl> <dbl> <dbl>
1 1 投票 不明 1 0 0
2 2 棄権 <NA> 0 1 0
3 3 投票 自民 1 0 0
4 4 投票 自民 1 0 0
5 5 棄権 <NA> 0 1 0
6 6 投票 自民 1 0 0
7 7 投票 不明 1 0 0
8 8 投票 自民 1 0 0
9 9 投票 自民 1 0 0
10 10 投票 民進 1 0 0
# ℹ 2,990 more rowsダミー変数の作成({fastDummies}使用)
if_else()を使う場合、ダミー変数名を自分で指定できるが、dummy_cols()の場合は「元の変数名_値」になるため、必要に応じてrename()を使用し、変数名を修正すること。
# A tibble: 3,000 × 6
ID Voted_F VotedParty_F Voted_F_投票 Voted_F_棄権 Voted_F_選挙権なし
<dbl> <fct> <fct> <int> <int> <int>
1 1 投票 不明 1 0 0
2 2 棄権 <NA> 0 1 0
3 3 投票 自民 1 0 0
4 4 投票 自民 1 0 0
5 5 棄権 <NA> 0 1 0
6 6 投票 自民 1 0 0
7 7 投票 不明 1 0 0
8 8 投票 自民 1 0 0
9 9 投票 自民 1 0 0
10 10 投票 民進 1 0 0
# ℹ 2,990 more rows順序変数
順序尺度で測定された変数
- 例) 最終学歴
- カテゴリー変数のように扱うことも、連続変数のように扱うことも可能
- 記述統計の表としてまとめる場合は、連続変数同様に扱う
記述統計掲載の例
| 平均値 | 中央値 | 標準偏差 | 最小値 | 最大値 | 有効ケース数 | |
|---|---|---|---|---|---|---|
| 女性 | 0.503 | 1 | 0.500 | 0 | 1 | 3000 |
| 年齢 | 47.340 | 47 | 15.628 | 18 | 75 | 3000 |
| 最終学歴 | 0.018 | 0 | 0.133 | 0 | 1 | 3000 |
| 投票有無: 投票 | 0.736 | 1 | 0.441 | 0 | 1 | 3000 |
| 投票有無: 棄権 | 0.229 | 0 | 0.420 | 0 | 1 | 3000 |
| 投票有無: 選挙権なし | 0.035 | 0 | 0.184 | 0 | 1 | 3000 |
| 投票先: 自民 | 0.399 | 0 | 0.490 | 0 | 1 | 2208 |
| 投票先: 民進 | 0.199 | 0 | 0.399 | 0 | 1 | 2208 |
| 投票先: 公明 | 0.051 | 0 | 0.220 | 0 | 1 | 2208 |
| 投票先: 維新 | 0.100 | 0 | 0.300 | 0 | 1 | 2208 |
| 投票先: 共産 | 0.078 | 0 | 0.269 | 0 | 1 | 2208 |
| 投票先: その他 | 0.011 | 0 | 0.104 | 0 | 1 | 2208 |
| 投票先: 不明 | 0.163 | 0 | 0.369 | 0 | 1 | 2208 |
| 感情温度: 自民 | 41.130 | 50 | 28.015 | 0 | 100 | 3000 |
| 感情温度: 民進 | 34.248 | 40 | 25.947 | 0 | 100 | 3000 |
グループごとの記述統計量
投票有無ごとの平均年齢
グループごとの記述統計量(可視化)
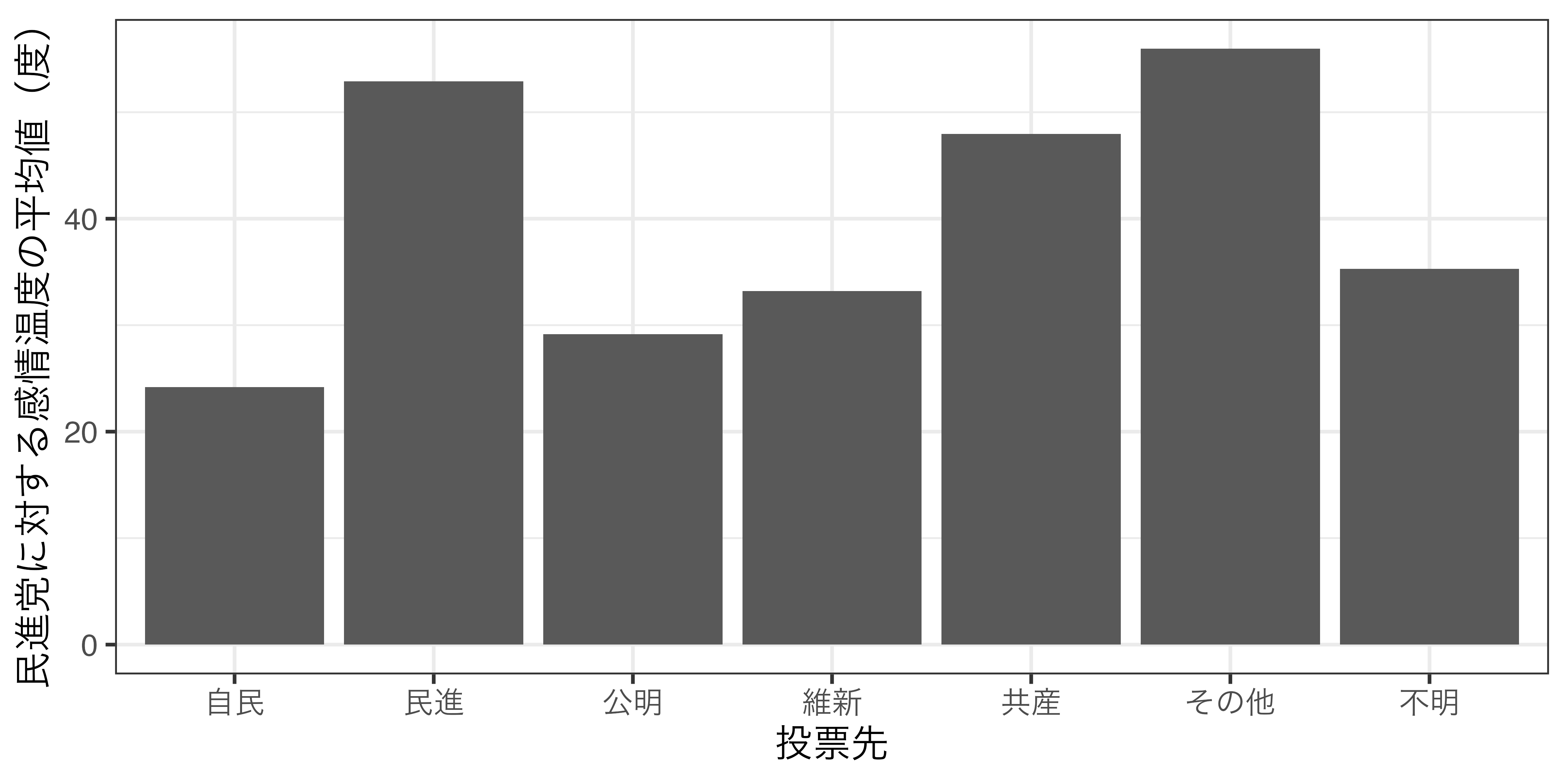
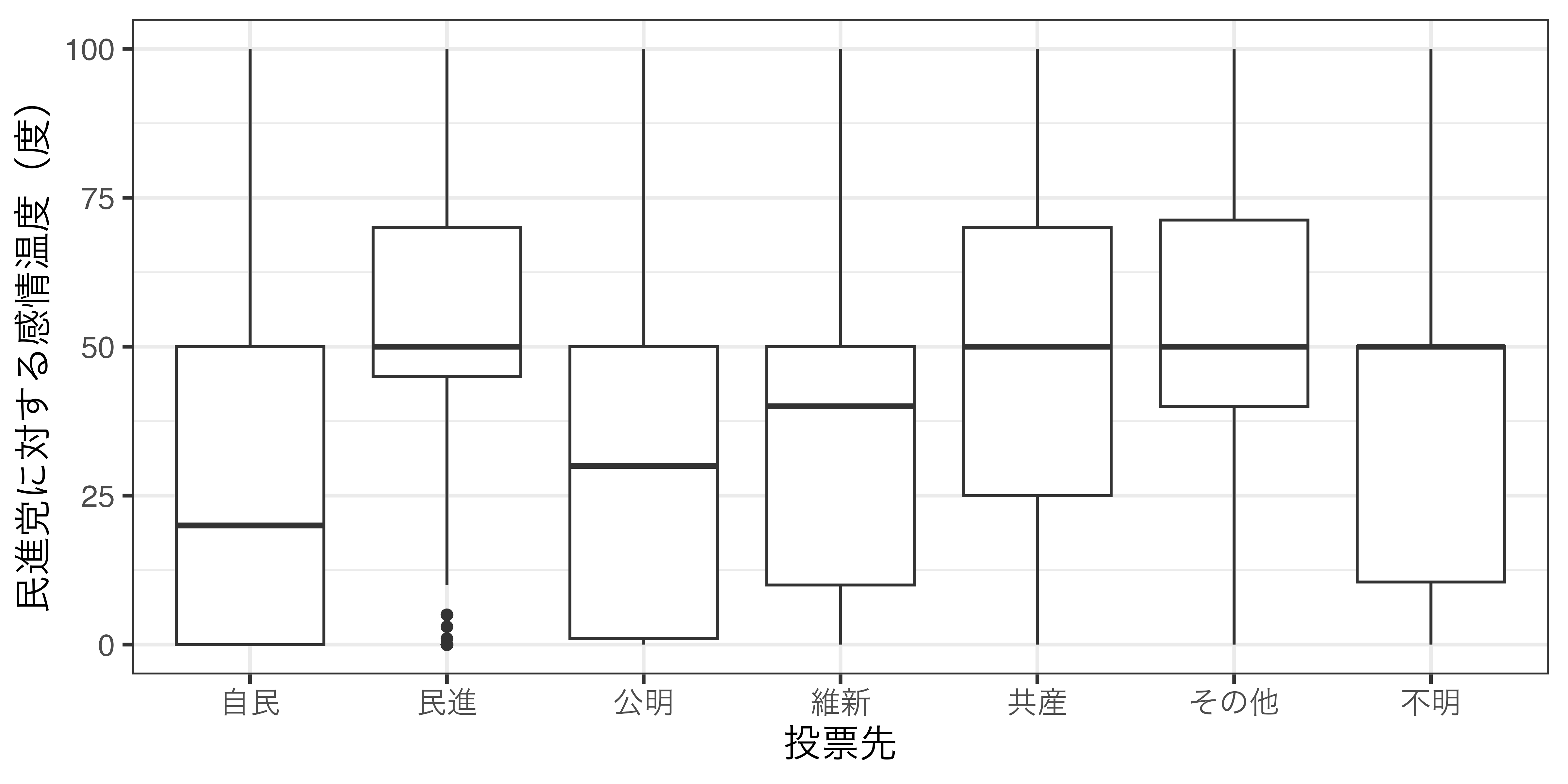
まとめ
- 分析に使われる変数を決める。
- 名目変数はダミー変数に変換する。
if_else()か{fastDummies}パッケージを使用- 例外)たとえば居住都道府県の変数はダミー変数に変換するとは47個のダミー変数ができてしまうので、このように項目数が非常に多い名目変数は省略するか、別途の棒グラフなどで分布を示す。
- 省略の場合、その旨を明記すること。
- 記述統計量を計算する。
- {summarytools}パッケージなどを使用しても良い。
- 報告する記述統計量:平均値、標準偏差、最小値、最大値、有効ケース数(欠損値がない場合、省略可)
- 読者にとって読みやすい表に加工する。
教科書との対応
副読本『私たちのR: ベストプラクティスの探求』
install.packages()、library():第5章read_csv():第8章dim():第10章names()、select():第13章summarise()、group_by():第14章mutate()、if_else():第15章factor(): 第16章- グラフの作成: 第19〜22章
Rの操作になれていない場合、当該章のみを読んでも内容を理解することは難しい。これは文法を勉強せずに辞書を調べることと同じ行為である。プログラミング、ソフトウェアの使い方は積み上げが重要であるため、第1章から読むことを推奨(当該章のみ抜粋して読むことは、その後の話)