# まずはtidyverseを読み込んでおく
library(tidyverse)
nauru_income <- round(rnorm(10210, mean = 5000, sd = 2000))大数の法則
大数の法則?
統計学を勉強するなら「大数の法則(Law of large numbers)」は一度くらいは聞くはず。この法則が知らなくても統計的手法を「使う」のは問題ない。しかし、その手法の背後にあるこれらの法則を知らないと「使う」ことは出来ても「理解」することは難しい。
とにかく、この法則は強法則と弱法則があるが、簡単に言えば「ある母集団から相互独立的に選ばれたサンプルのサイズが大きければ大きいほど、そのサンプルの平均値(標本平均)は母集団の平均値(母平均)に収斂する」ということ。
…?
簡単に言ったつもりだが、今見たらそこまで分かりやすい表現ではなさそうだ。
例えば地球上にいる人々の身長の平均値はどうだろうか。適当に一人を選んで身長を測ったとしても、それが地球上の人々の平均値と一致する可能性は極めて低い(厳密に言うとゼロ)し、直観的に考えてみて平均値からかなり外れている可能性も高いと考えられる。 しかし、1億人くらいを適当に選んで平均をとったら?その場合は先と比べてかなり平均値に近いと考えられる。これが大数の法則である。 今後やってみようと思うが、「中心極限定理」とは違う。中心極限定理は「標本平均の分布」の話であって、「標本平均そのもの」の話ではない。 ならば早速シミュレーションしてみよう。
シミュレーション設計
太平洋の島国、ナウルの人々の収入の平均値はいくらだろうか。なぜナウルかというと理由はない。ちょうど人口が1万くらいの何らかの例が欲しかっただけ。あくまでも用いるデータは仮想のデータである。
- ナウルの人口は1万210人とする。
- ナウル国民の所得の平均値は約5千ドルであって、標準偏差2千ドルの正規分布をしている1。つまり、所得が5千ドルくらいの人が最も多く、9千ドル以上とか1千ドル以下は非常に少ない。
- この1万210人の所得データから無作為にナウル人を抽出し、抽出されたナウル人の所得の平均値をとる。
- ただし、無作為に「何人」ととるかが問題。ここでは大数の法則を経験的に確認するために1人から1000人まで徐々に増やしていく。
- 一回抽出したデータはまた抽出されることもある(復元抽出)。これはサンプリングが相互独立であるためである。
シミュレーション・コード
まずは、ナウル国民の所得を生成する。ナウル国民の所得は\(\text{Normal}(\mu = 5000, \sigma = 2000)\)の分布をしている。
これで10210人のナウル国民の所得を設定した。ならば生成されたデータを見てみる。
summary(nauru_income) Min. 1st Qu. Median Mean 3rd Qu. Max.
-3505 3630 5026 5003 6340 12486 ナウル国民の所得の平均は5017ドル、最小値は-1761だそうだ。「所得にマイナスなんてあり得るか!」と思うかも知れないが、細かいことは無視しよう。知りたいのは大数の法則を経験的に確認することであって、ナウル国民の所得ではない。
次はヒストグラムで見てみよう。
nauru_income %>%
enframe(name = "ID", value = "Income") %>%
ggplot() +
geom_histogram(aes(x = Income, y = ..density..),
color = "white", binwidth = 500) +
stat_function(fun = dnorm, args = list(mean = 5000, sd = 2000),
color = "red", size = 1) +
labs(x = "所得", y = "密度")Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.Warning: The dot-dot notation (`..density..`) was deprecated in ggplot2 3.4.0.
ℹ Please use `after_stat(density)` instead.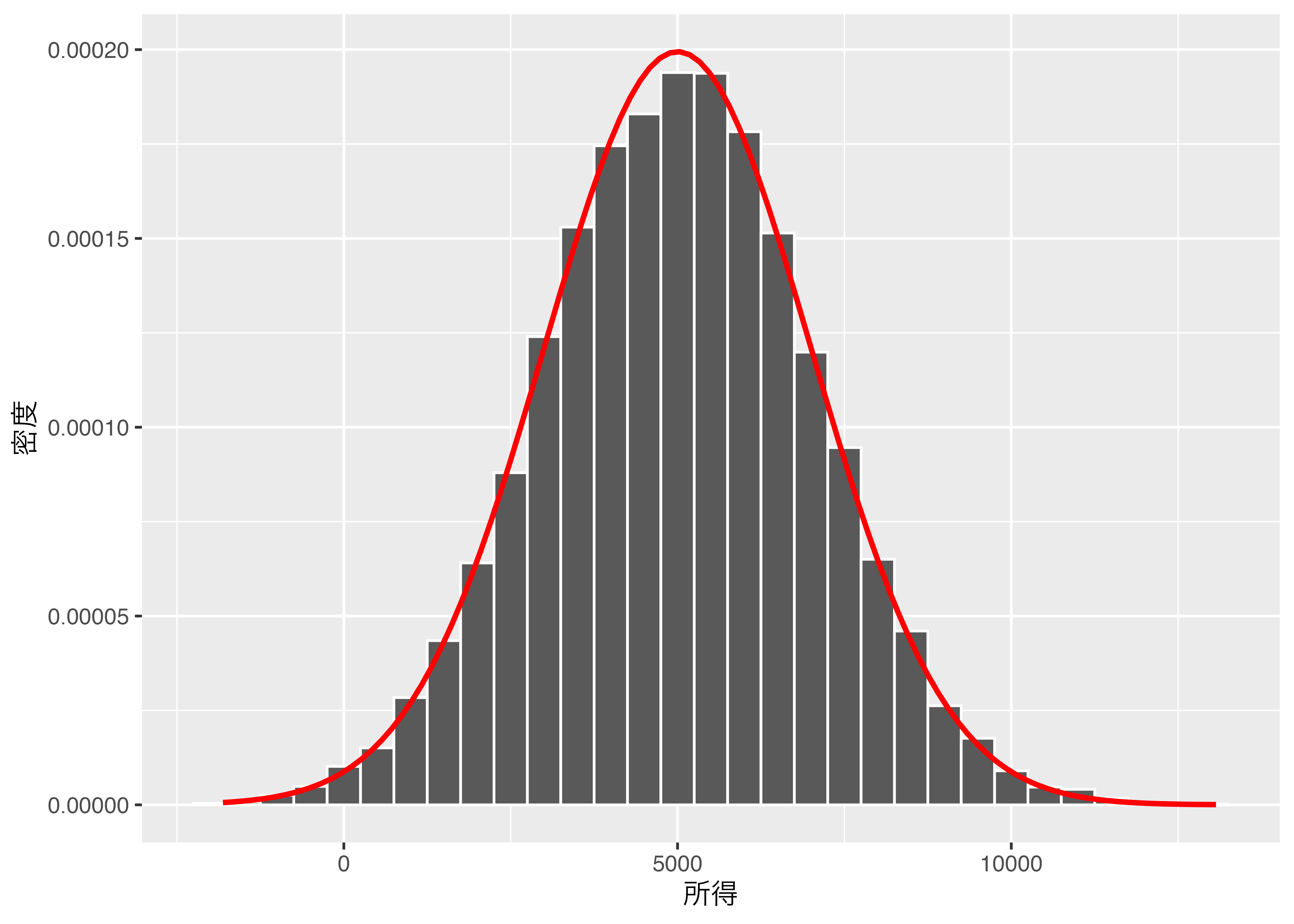
きれいな正規分布の形をしている。 次は、この1万210人の国民からランダムに抽出し、抽出された人の所得の平均値を見てみる。抽出される人数は最初は一人とし、徐々に増やしていく。
#まずは空のデータフレイムを作っとく
result_df <- data.frame(n = NA, mean = NA)
for(i in 1:1000){
result_df[i, ] <- c(i, mean(sample(nauru_income, i, replace = TRUE)))
}head(result_df) n mean
1 1 4716.000
2 2 5565.000
3 3 6901.000
4 4 4282.000
5 5 5103.000
6 6 4007.167抽出された人が一人の場合、彼(女)の所得は7710ドルであって、6人の場合、彼(女)らの所得の平均値は5502ドルである。 これをグラフで見ると
result_df %>%
ggplot() +
geom_hline(yintercept = mean(result_df$mean), color = "red") +
geom_line(aes(x = n, y = mean)) +
labs(x = "サンプルサイズ", y = "平均値")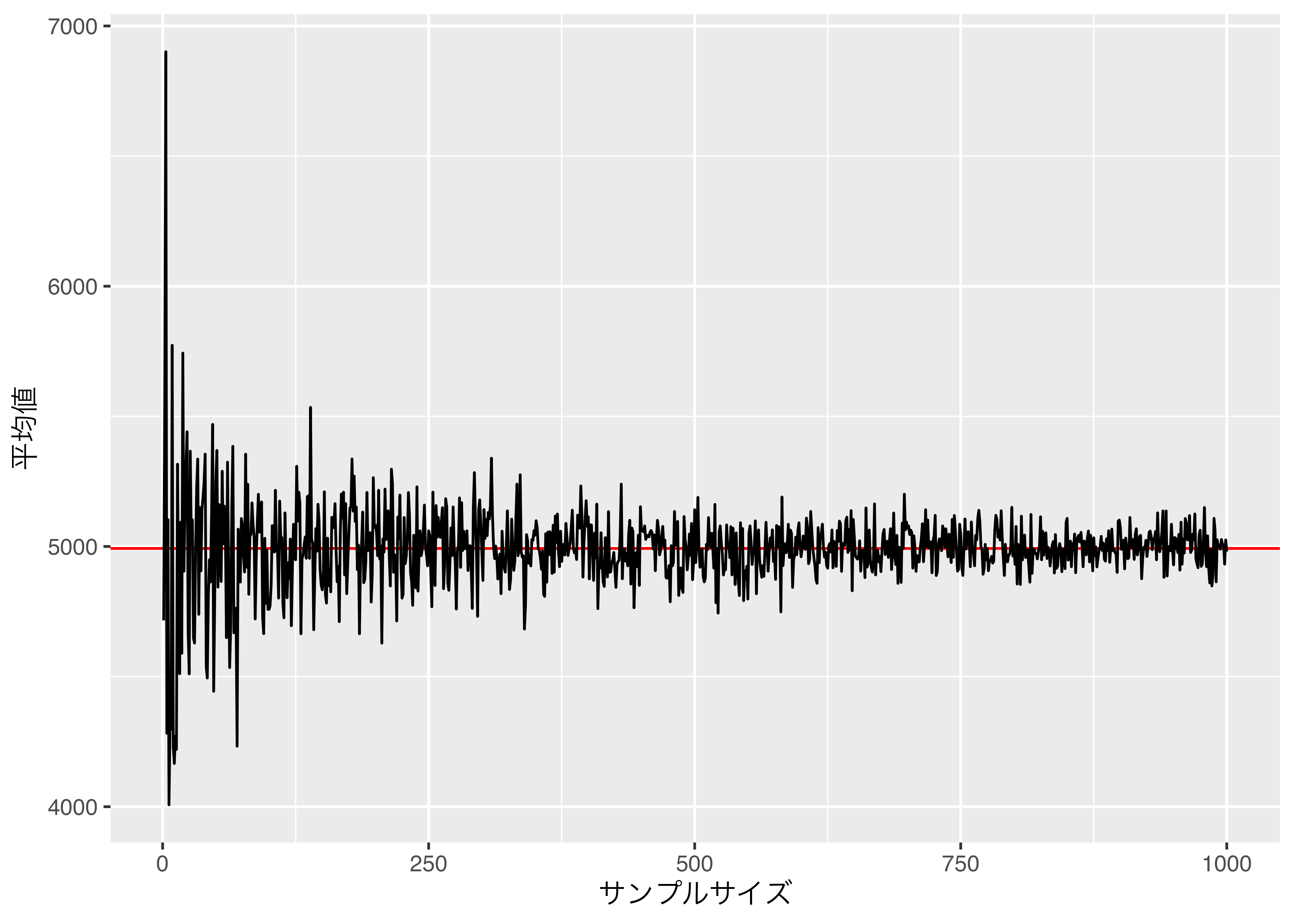
抽出される人が多くなるほど、その平均値はナウル国民の平均値に近づいていくことが確認できる。
「でも、こんなの偶然かも知れないじゃん!」
と思うこともできる。この作業を10回くらいやってみよう。
result_df <- as.data.frame(matrix(rep(NA, 1000 * 11), ncol = 11))
names(result_df) <- c("n", paste0("mean", 1:10))
for (i in 1:1000) {
result_df[i, 1] <- i
for (j in 2:11) {
result_df[i, j] <- c(mean(sample(nauru_income, i, replace = TRUE)))
}
}
result_df %>%
pivot_longer(cols = mean1:mean10,
names_to = "trial",
values_to = "mean") %>%
ggplot() +
geom_hline(yintercept = 5000, color = "red") +
geom_line(aes(x = n, y = mean, group = trial), alpha = 0.2) +
labs(x = "サンプルサイズ", y = "平均値")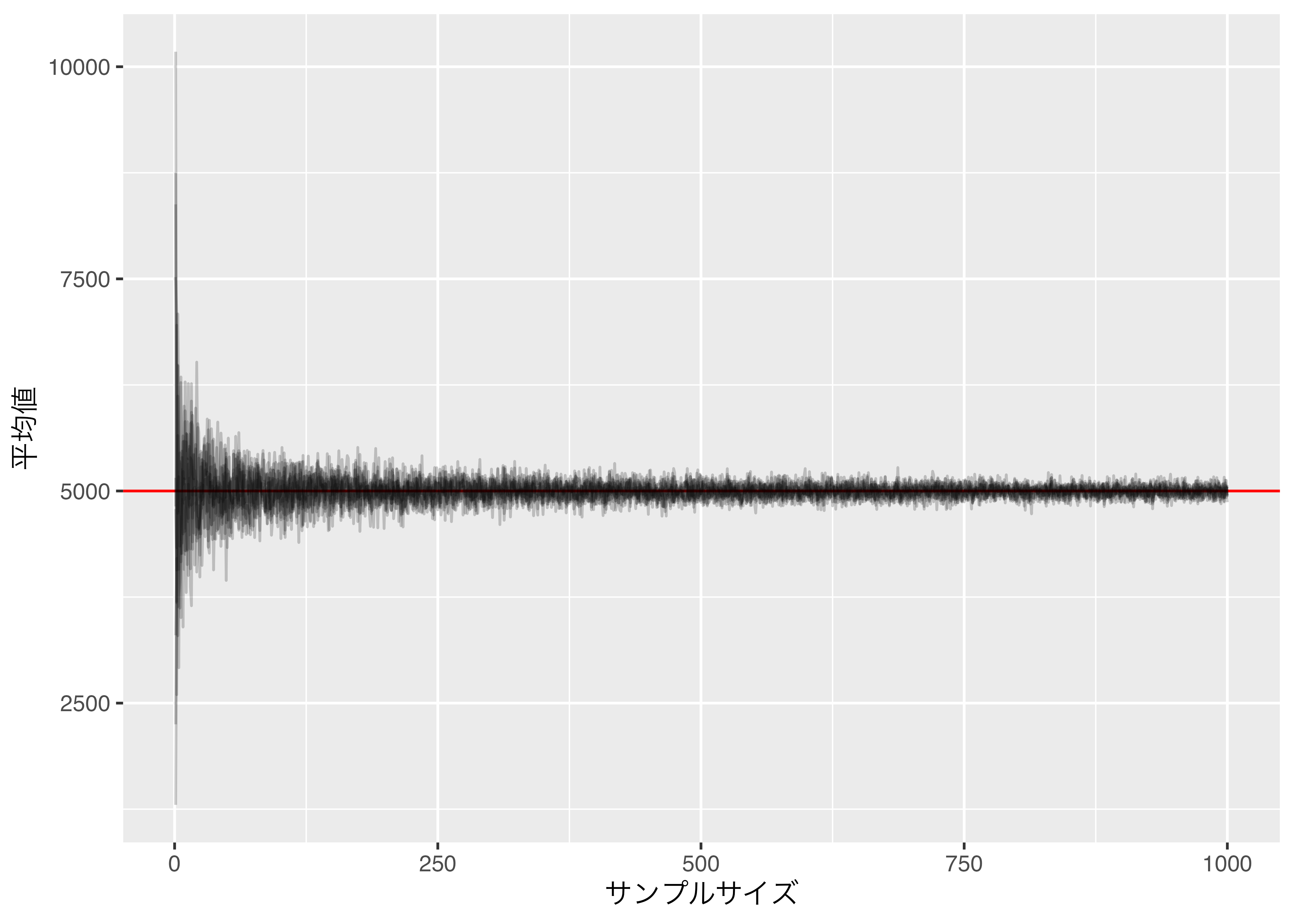
だいたいこんなもんだ。むしろ、偶然とろろかよりきれいなグラフが出来上がったと思う。もうちょっと拡大してみると
result_df %>%
pivot_longer(cols = mean1:mean10,
names_to = "trial",
values_to = "mean") %>%
filter(n <= 100) %>%
ggplot() +
geom_hline(yintercept = 5000, color = "red") +
geom_line(aes(x = n, y = mean, group = trial), alpha = 0.2) +
labs(x = "サンプルサイズ", y = "平均値")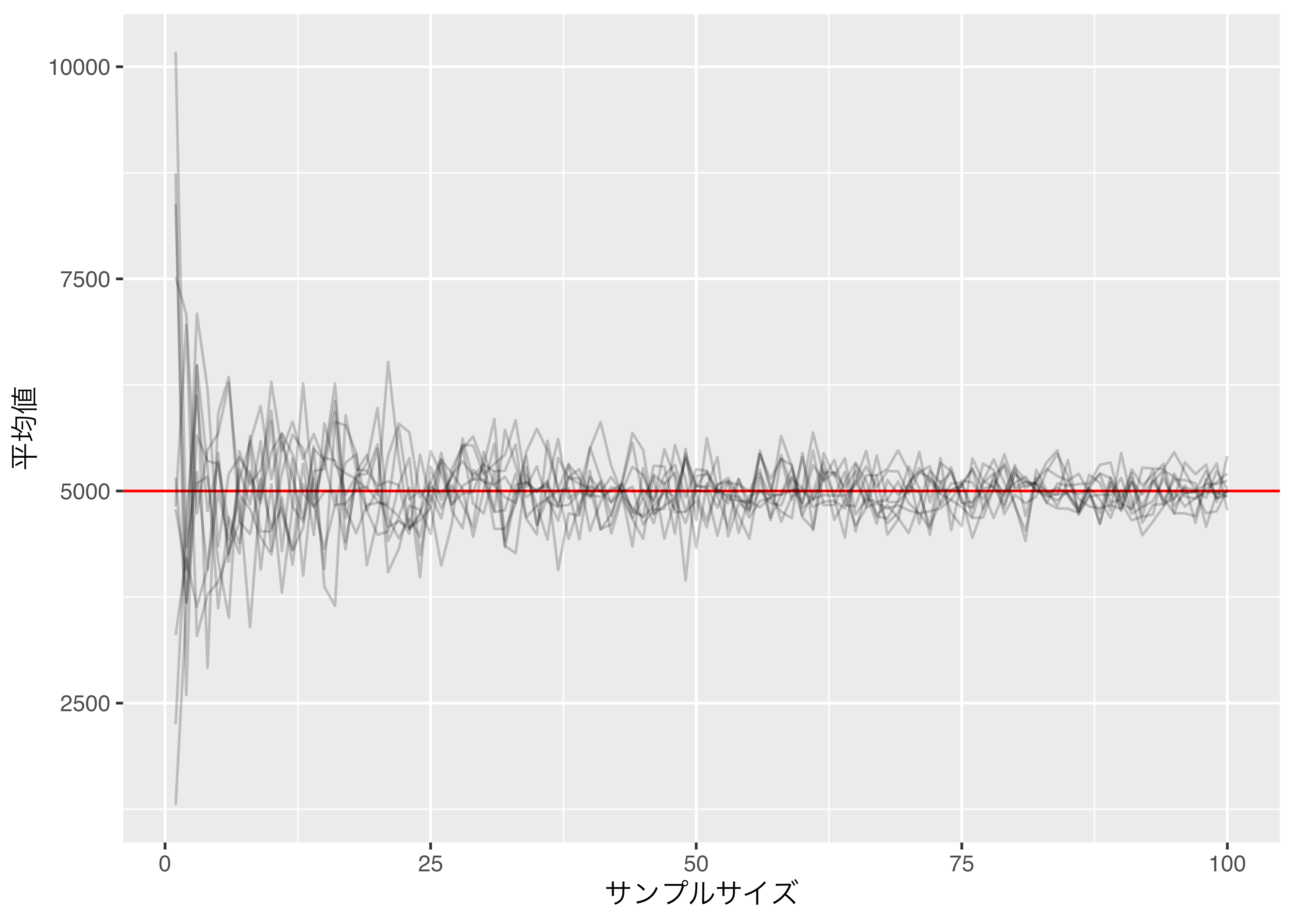
こんなもんだ。抽出される人が多くなると彼(女)らの所得の平均値は全体国民の平均値に近づく。これが大数の法則である。 直観的に考えれば当然のことでもあるが、この大数の法則と今後紹介する中心極限定理などに基づいて(伝統的)統計学2における「仮説検定」が成り立っているとも言える。