ミクロ政治データ分析実習
10/ データ・ハンドリング(3)
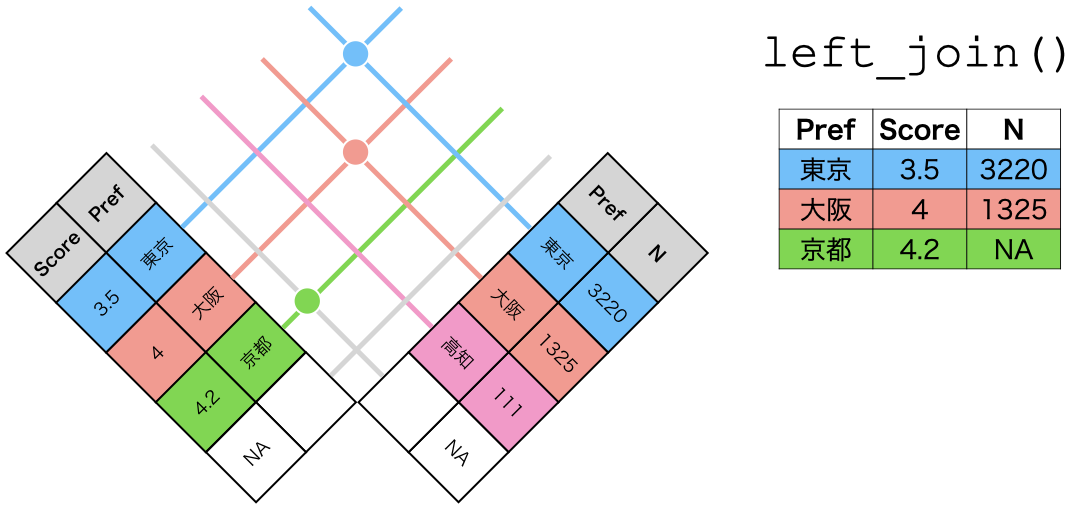
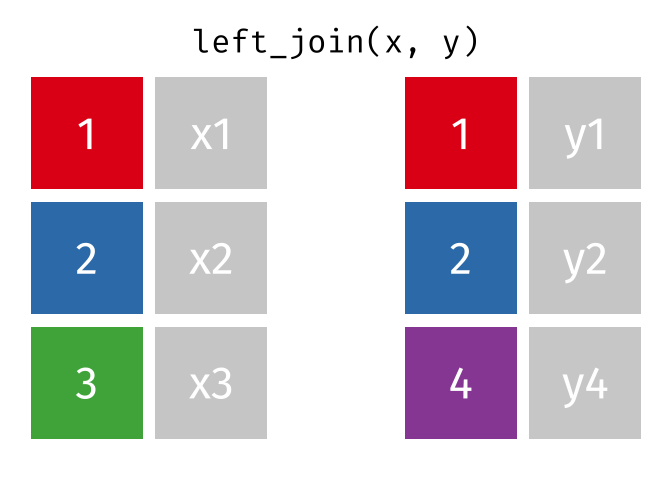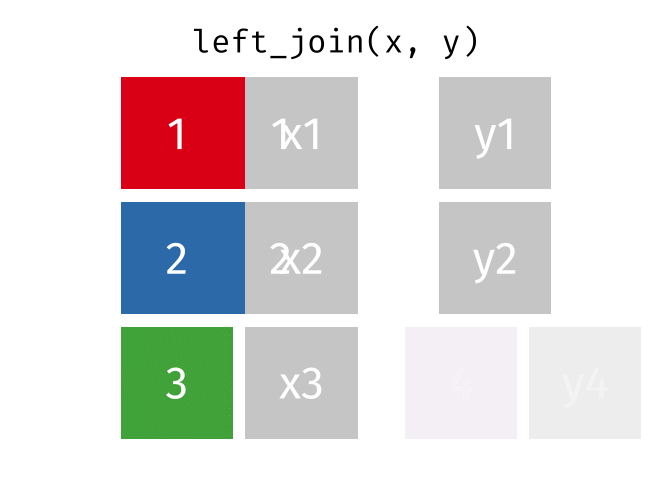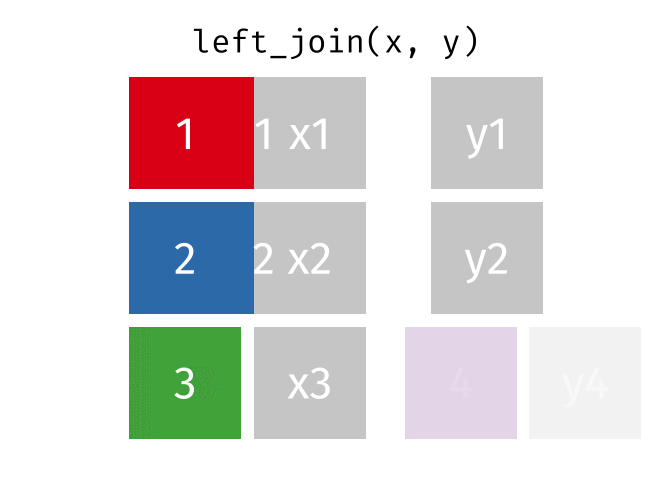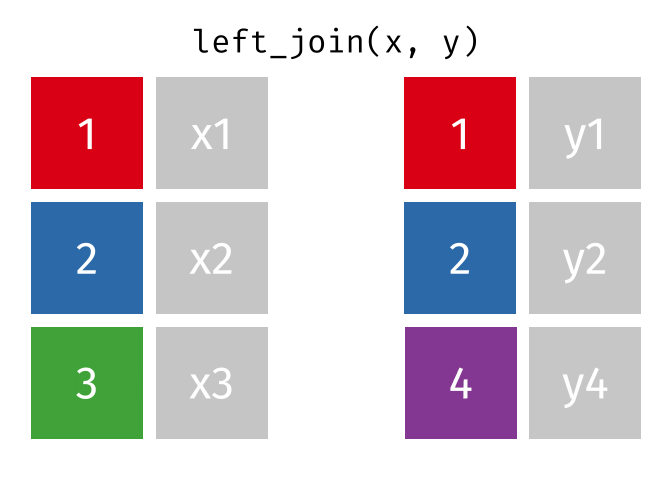
left_join()の仕組み
left_join(データ1, データ2, by = "識別用変数名")
- データ1を温存する
- 欠損しているセルは欠損値(
NA)で埋められる
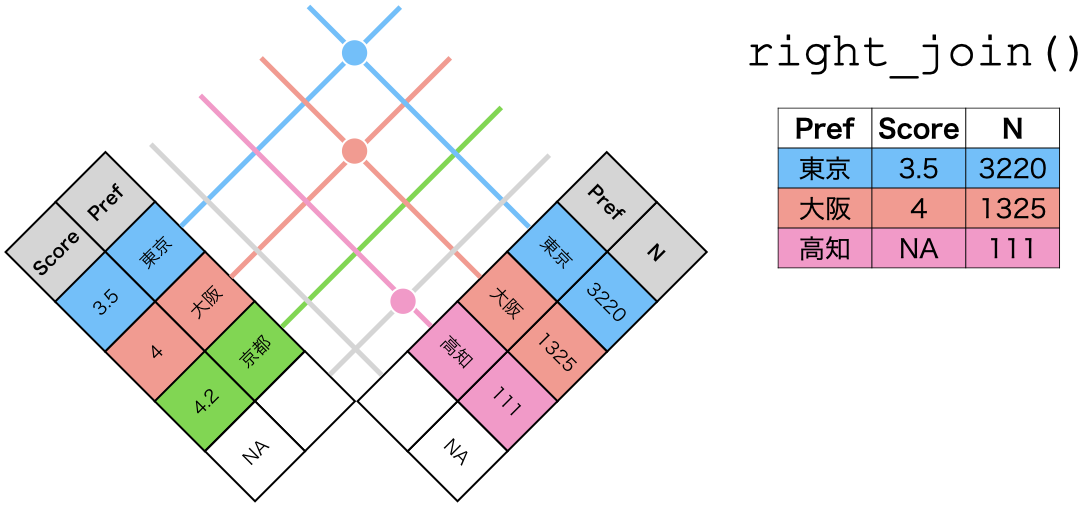
right_join()の仕組み
right_join(データ1, データ2, by = "識別用変数名")
- データ2を温存する
- 欠損しているセルは欠損値(
NA)で埋められる

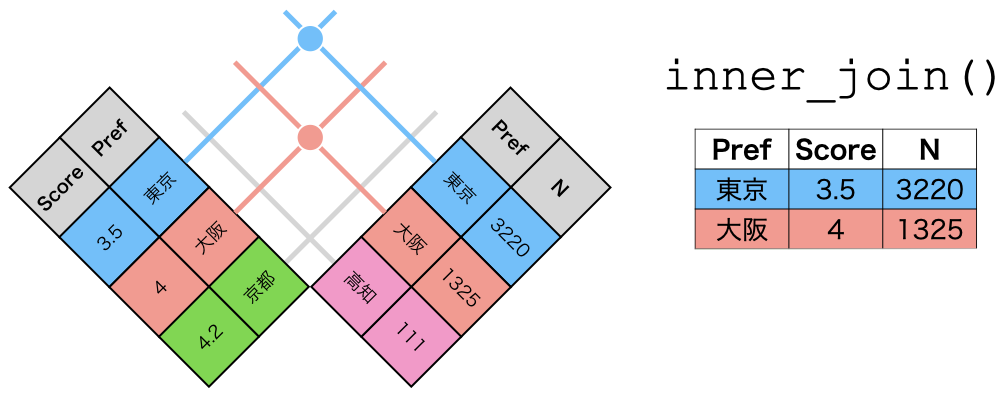
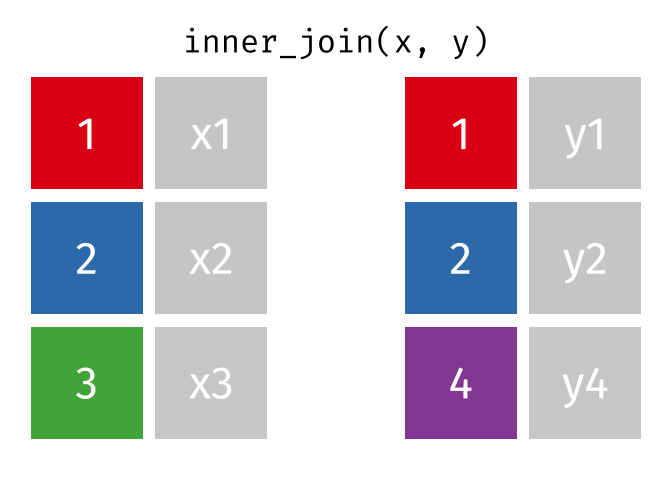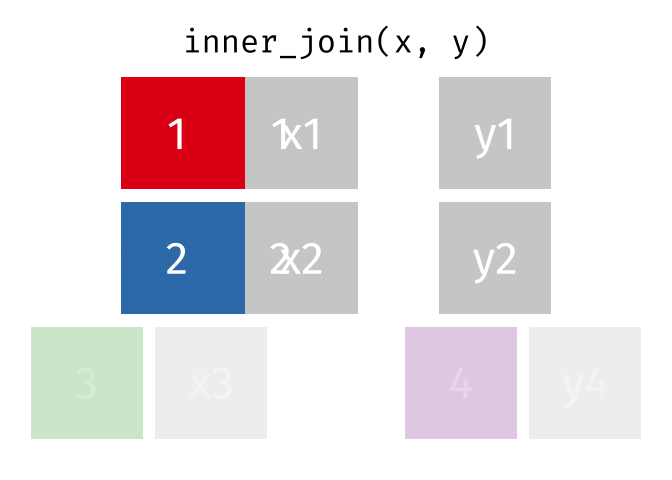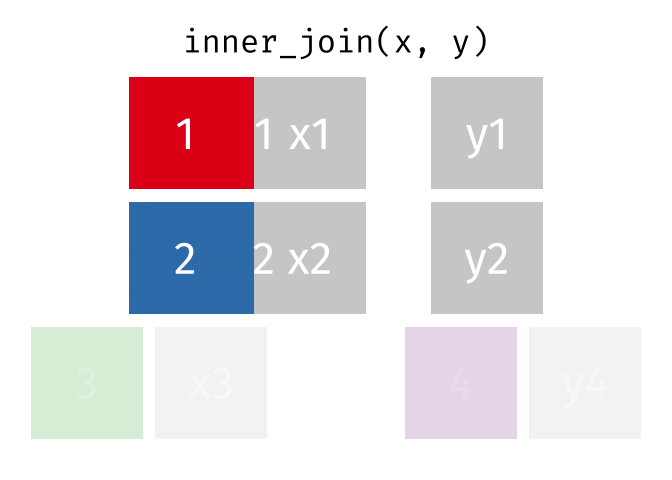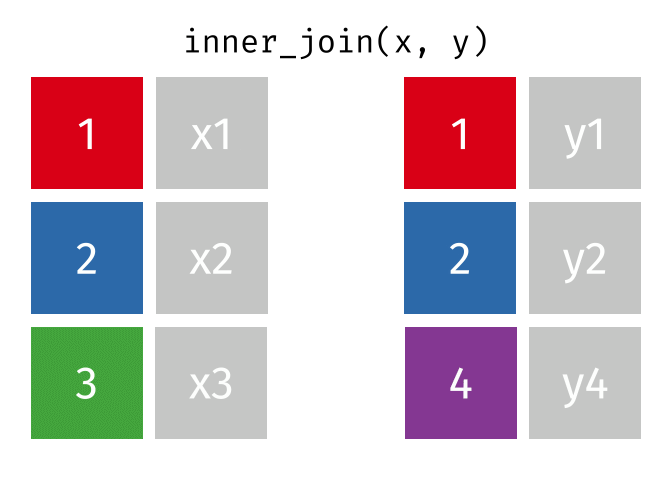
inner_join()の仕組み
inner_join(データ1, データ2, by = "識別用変数名")
- データ1とデータ2で識別子が共通する行のみ結合
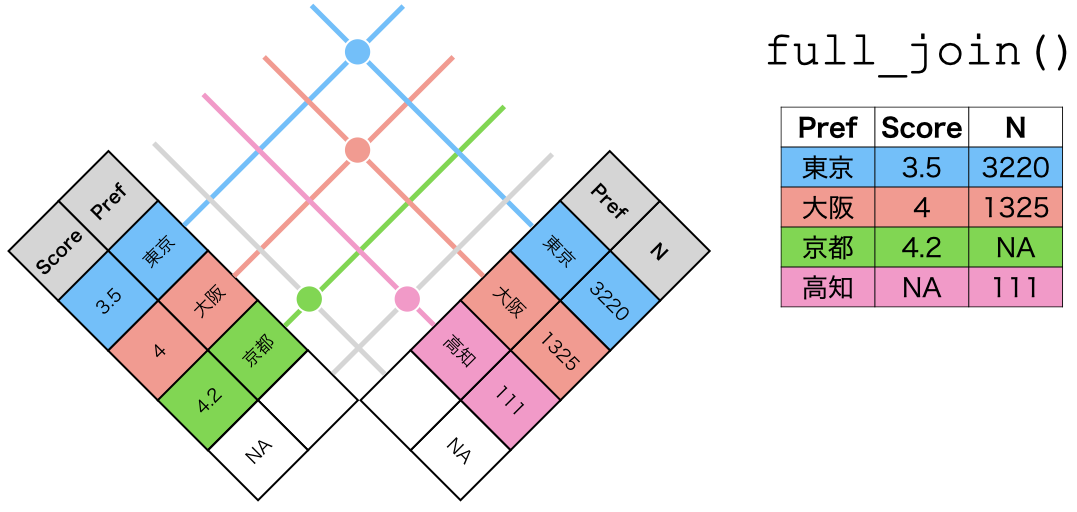
full_join()の仕組み
full_join(データ1, データ2, by = "識別用変数名")
- データ1とデータ2をすべて温存
- 欠損しているセルは欠損値(
NA)で埋められる

整然データ構造とは
Tidy data:Hadley Wickhamが提唱したデータ分析に適したデータ構造
- 「整然データ」、「簡潔データ」と呼ばれる。
- 対概念は「非整然データ」、「雑然データ」(messy data)
- パソコンにとって読みやすいデータ \(\neq\) 人間にとって読みやすいデータ
- {tidyr}パッケージは雑然データを整然データへ整形するパッケージ
- 次回紹介する{ggplot2}は整然データを前提として開発されたパッケージ
4つの原則
- 1つの列は、1つの変数を表す
- 1つの行は、1つの観測を表す
- 1つのセルは、1つの値を表す
- 1つの表は、1つの観測単位をもつ

原則1:1列1変数
- 1列には1つの変数のみ
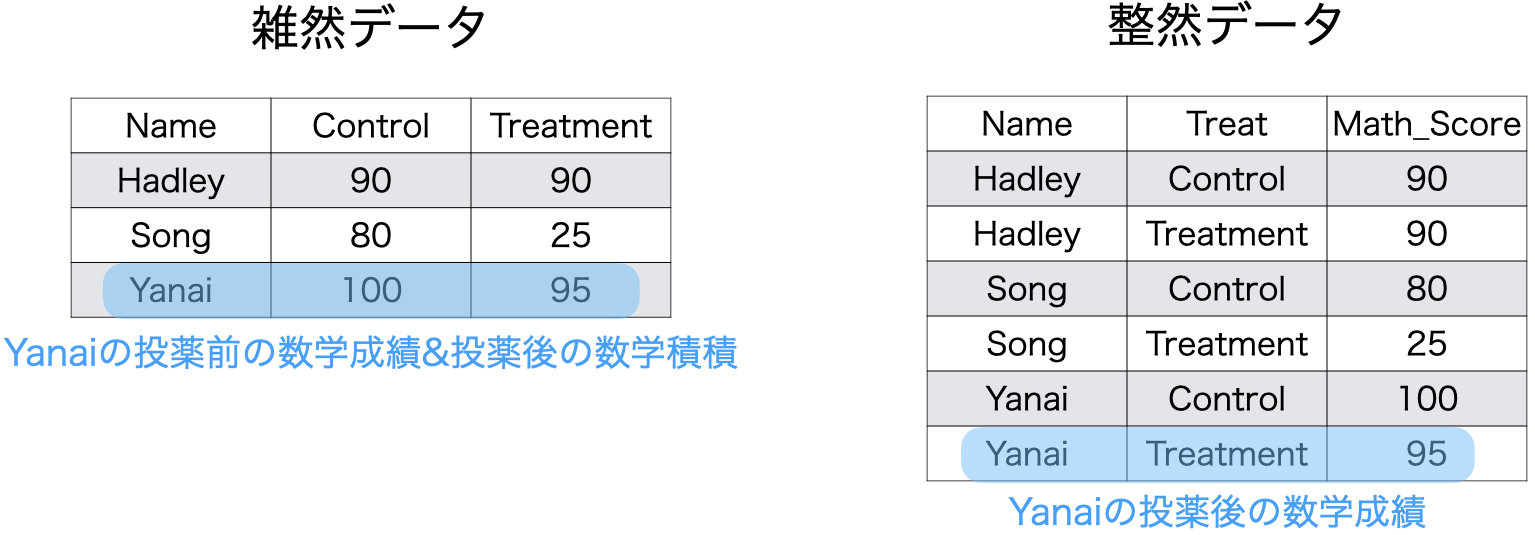
- 3人の被験者に対し、薬を飲む前後の数学成績を測定した場合
- 薬を飲む前:Control / 薬を飲んだ後:Treatment

原則2:1行1観察
- 1観察 \(\neq\) 1値
- 観察:観察単位ごとに測定された値の集合
- 観察単位:人、企業、国、時間など
- 以下の例の場合、観察単位は「人 \(\times\) 時間 」
原則3:1セル1値
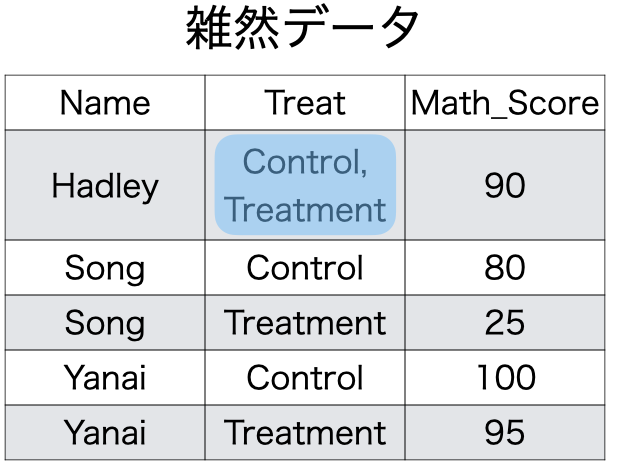
- この原則に反するケースは多くない
- 例外) 1セルに
2020年8月24日という値がある場合- 分析の目的によっては年月日を全て異なるセルに割り当てる必要もある
- このままで問題とならないケースも
原則4:1表1単位
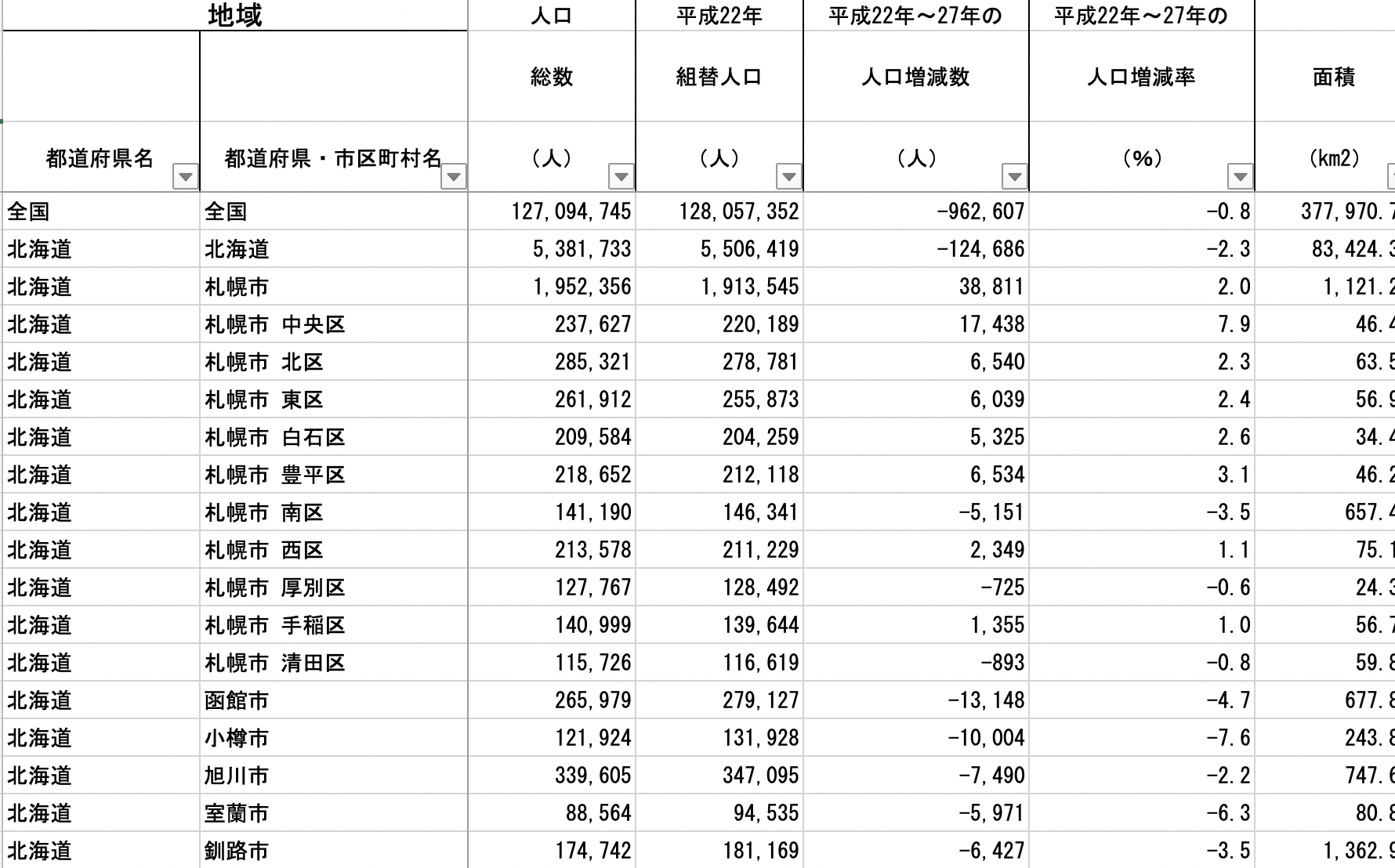
- 政府統計:日本を代表する雑然データ
- データの中身は良いが、構造が…
- 表に「国」、「都道府県」、「市区町村」、「行政区」の単位が混在
原則4:1表1単位
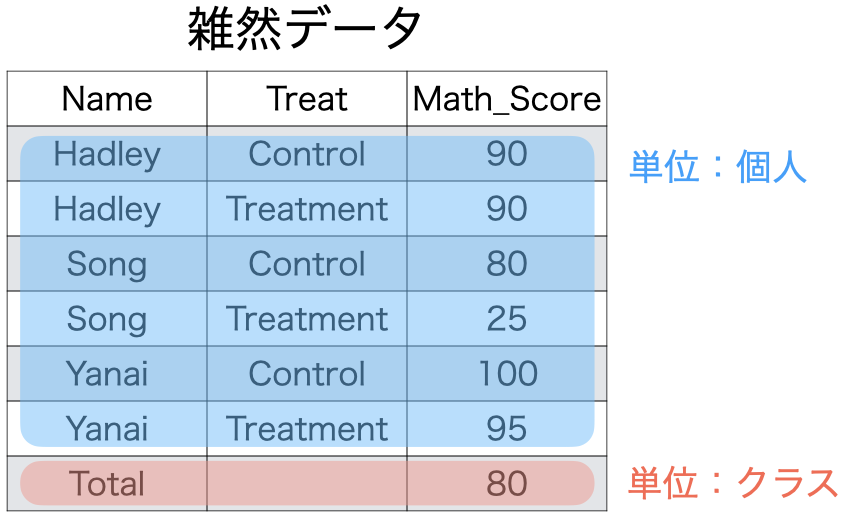
- 「1表1単位」原則を満たさない場合、
filter()関数等で、異なる単位の行を除外- 以降、解説する{tidyr}でなく、{dplyr}で対応可能
{tidyr}パッケージ

雑然データから整然データへ変形をサポートするパッケージ
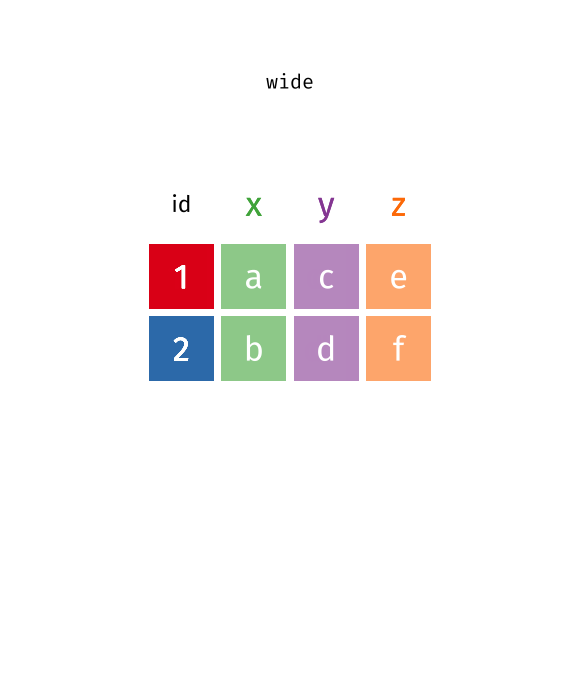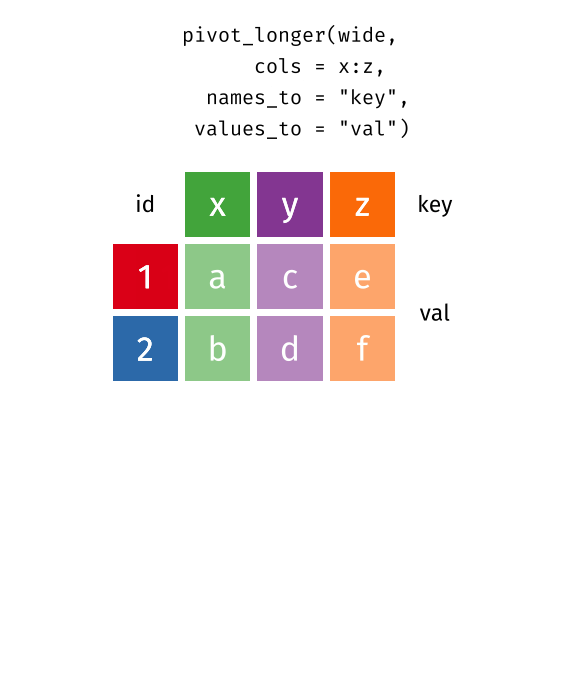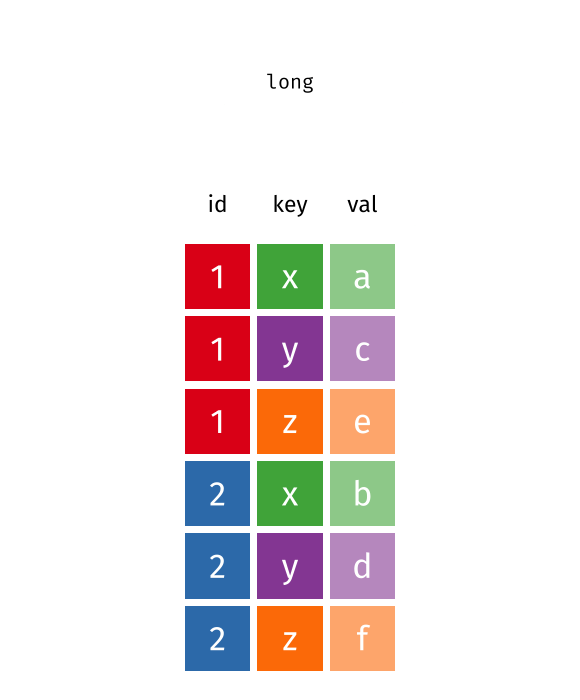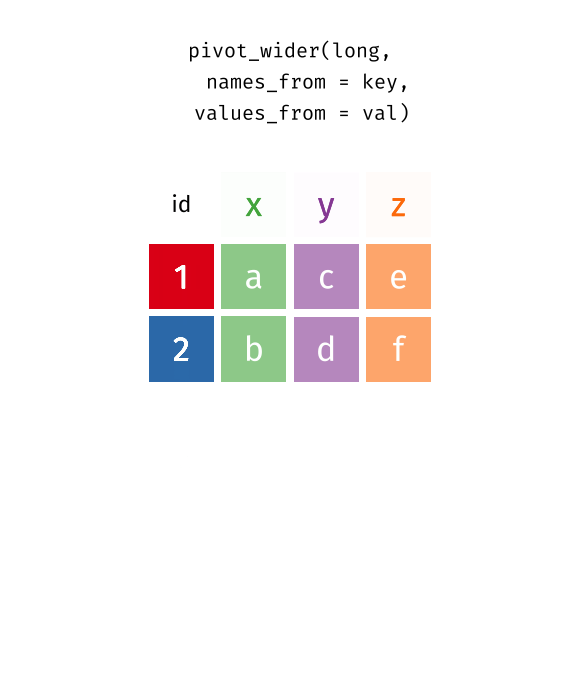
pivot_longer():Wide型データからLong型データへ- 原則1・2に反するデータを整然データへ変換 (最も頻繁に使われる)
pivot_wider():Long型データからWide型データへ- 人間には雑然データの方が読みやすい場合がある(原則1の例)
separate():セルの分割(「年月日」から「年」、「月」、「日」へ)- 原則3に反するデータを整然データへ変換
- 原則4に反するデータは分析単位が異なる行を
filter()などで除外
pivot_longer()とpivot_wider()