ミクロ政治データ分析実習
8/ データ・ハンドリング(1)
関西大学総合情報学部
授業開始前に
すぐに実習できるように準備しておきましょう。
- JDCat分析ツールを起動しておいてください。
- 本日授業用のプロジェクトを開いてください。
- RStudioの右上に「Project: (none)」と表示されたら\(\times\)
- LMSから実習用データをダウンロードしておいてください。
- ダウンロードしてデータをプロジェクト・フォルダーにアップロードしてください。
- 実習用コードを入力する空のスクリプトファイル、またはQuartoファイルを開き、以下のコードを入力&実行してください。
- トラブルが生じた場合、速やかにTAを呼んでください。
- 時間に余裕があれば、スライド内のコードも書いておきましょう。
Tidyverseの世界とパイプ演算子
Tidyverseの世界

データサイエンスのために考案された、強い信念と思想に基づいたRパッケージの集合
- {tidyverse}をインストールすることで導入可能
- Tidyverseに属するパッケージは思想、文法およびデータ構造を共有
- {dplyr}、{tidyr}、{readr}、{ggplot2}など
- オブジェクトをパイプ演算子(
|>or%>%)で繋ぐ
Rのコードはlibrary(tidyverse)で始めよう!
パイプ演算子
Tidyverseにおいてオブジェクトは|>で繋がっている。
- 既存の書き方:書き方と読み方が逆
- 一般的なプログラミング言語共通
- 書き方:
print(sum(X))(print、sum、Xの順で書く) - 読み方1:
Xをsum()し、print()する(コードの順番と逆) - 読み方2:
print()する内容はsum()で、sum()はXに対して行う(直感的でない読み方)
- Tidyverseな書き方:書き方と読み方が(おおむね)一致
- 今どきのRの書き方
- 書き方:
X |> sum() |> print() - 読み方:
Xをsum()し、print()する
パイプ演算子の仕組み
|>の左側を右側の最初の引数として渡すだけX |> 関数(Y)は関数(X, Y)と同じX |> sum(na.rm = TRUE)はsum(X, na.rm = TRUE)と同じ
- ショートカットキーを使えば簡単に入力可能
- macOS:Command(⌘) + Shift + m
- Windows/Linux:Control(Ctrl) + Shift + m
- 二番目以降の引数として渡すことも可能(適宜、解説)
様々な書き方
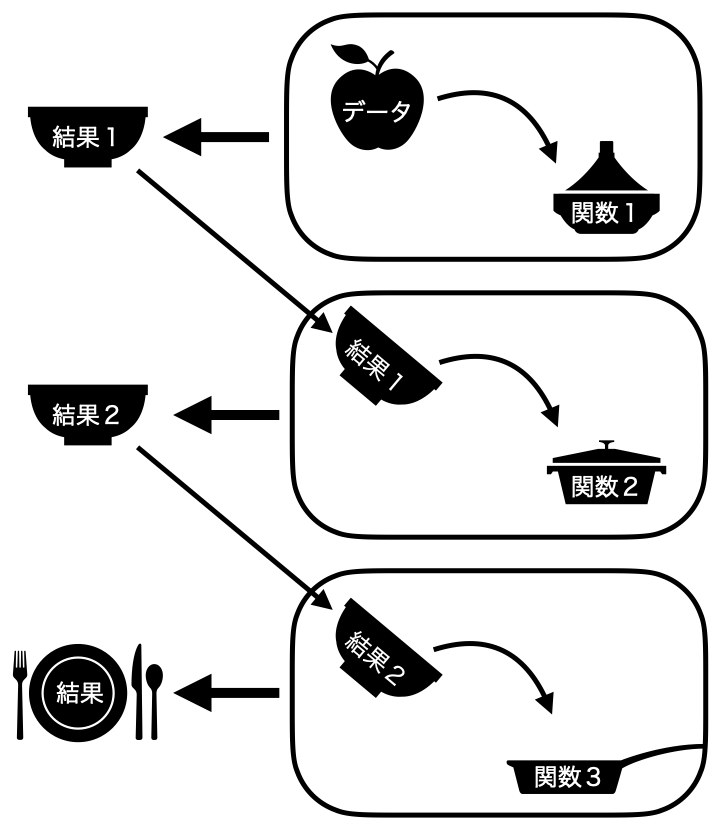
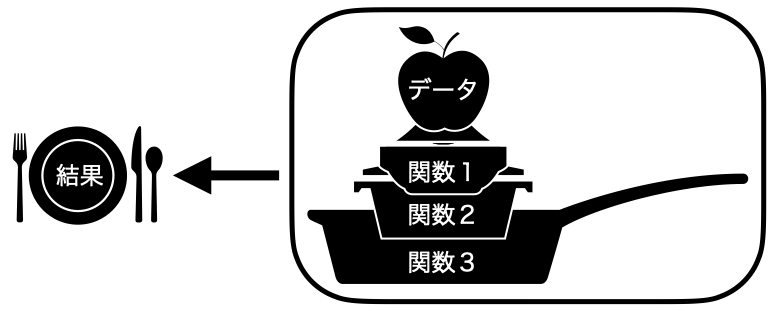

参考)%>%:もう一つのパイプ演算子
R内蔵演算子としてパイプ演算子(|>)が追加
- 2021年5月リリースされたR 4.1からR内蔵のパイプ演算子
|>が登場 - それまでは{magrittr}パッケージが提供する
%>%を使用- {magrittr}は{tidyverse}を読み込むと自動的に読み込まれる。
- 使い方はほぼ同じ
- ただし、演算子の左側のオブジェクトを右側の第一引数として渡す場合のみ
- 第一引数以外の引数として渡す場合は使い方が異なる。
- インターネット、教科書などでは
%>%を使用するケースがまだ多いが、今後の主流は|>になると予想されるため、本講義では|>を使用する。- むろん、現段階では
%>%を使っても良いし、%>%を使ったコードを|>に置換して使ってもほぼ問題にならない。
- むろん、現段階では
参考)%>%と|>の比較
渡す先が第一引数の場合
- R内蔵のパイプ(native pipe;
|>)、{magrittr}のパイプ(%>%)の使い方は同じ
渡す先が第一引数でない場合
- 実引数として渡す箇所に
.(tidyverse)、_(native pipe)を入力
{dplyr}: 列の抽出
{dplyr}とは

- 表形式データ (データフレームやtibble)を操作するパッケージ
- 第8回の講義で解説した行・列の抽出も簡単に可能
- {tidyverse}を読み込む際に自動的に読み込まれる
- {tidyverse}はパッケージを集めたパッケージであり、{dplyr}もその一部
実習用データ
countries.csv: 186カ国の社会経済・政治体制のデータ
# A tibble: 186 × 18
Country Population Area GDP PPP GDP_per_capita PPP_per_capita G7
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghani… 38928346 6.53e5 1.91e4 8.27e4 491. 2125. 0
2 Albania 2877797 2.74e4 1.53e4 3.97e4 5309. 13781. 0
3 Algeria 43851044 2.38e6 1.70e5 4.97e5 3876. 11324. 0
4 Andorra 77265 4.7 e2 3.15e3 NA 40821. NA 0
5 Angola 32866272 1.25e6 9.46e4 2.19e5 2879. 6649. 0
6 Antigua… 97929 4.4 e2 1.73e3 2.08e3 17643. 21267. 0
7 Argenti… 45195774 2.74e6 4.50e5 1.04e6 9949. 22938. 0
8 Armenia 2963243 2.85e4 1.37e4 3.84e4 4614. 12974. 0
9 Austral… 25499884 7.68e6 1.39e6 1.28e6 54615. 50001. 0
10 Austria 9006398 8.24e4 4.46e5 5.03e5 49555. 55824. 0
# ℹ 176 more rows
# ℹ 10 more variables: G20 <dbl>, OECD <dbl>, HDI_2018 <dbl>,
# Polity_Score <dbl>, Polity_Type <chr>, FH_PR <dbl>, FH_CL <dbl>,
# FH_Total <dbl>, FH_Status <chr>, Continent <chr>実習用データの確認
186行、18列のデータ(= 186カ国、18変数)
変数の一覧
各変数について
詳細は教科書第18.2章を参照
| 変数名 | 説明 | 変数名 | 説明 | |
|---|---|---|---|---|
Country |
国名 | OECD |
OECD加盟有無 | |
Population |
人口 | HDI_2018 |
人間開発指数 (2018年) | |
Area |
面積( \(\text{km}^2\) ) | Polity_Score |
政治体制のスコア | |
GDP |
国内総生産(ドル) | Polity_Type |
政治体制 | |
PPP |
購買力平価国内総生産 | FH_PR |
政治的自由 | |
GDP_per_capita |
一人当たりGDP | FH_CL |
市民的自由 | |
PPP_per_capita |
一人当たりPPP | FH_Total |
FH_PR + FH_CL |
|
G7 |
G7加盟有無 | FH_Status |
自由の状態 | |
G20 |
G20加盟有無 | Continent |
大陸 |
列の選択(抽出): 書き方
select()関数を使用
注意: select()関数は複数ある!
select()関数は{dplyr}だけでなく、{MASS}からも提供されるが、別の関数である。
- {MASS}もデータ分析において頻繁に使われるパッケージであるため、
select()だけだと、どのパッケージのselect()か分からなくなる場合がある。 - エラーが生じる場合は、
dplyr::select()など、パッケージ名を指定すること
列の選択(抽出): 例
dfからCountry、Population、HDI_2018列を抽出し、最初の5行のみ出力
# A tibble: 5 × 3
Country Population HDI_2018
<chr> <dbl> <dbl>
1 Afghanistan 38928346 0.496
2 Albania 2877797 0.791
3 Algeria 43851044 0.759
4 Andorra 77265 0.857
5 Angola 32866272 0.574この時点では抽出・出力されただけ。抽出した結果をdf2という名で作業環境内に格納するためには
課題では格納が必要な場合もある
課題の問題には「出力せよ」だけでなく、「格納した上で出力せよ」といった形式もある。加工したデータを引き続き使うためには格納が必須であるため、問題文を注意深く読むこと。
列の選択と変数名の変更
変数名の変更と抽出を同時に行うことも可能
新しい変数名 = 既存の変数名
例) HDI_2018の変数名をHDIに変更
# A tibble: 186 × 3
Country Population HDI
<chr> <dbl> <dbl>
1 Afghanistan 38928346 0.496
2 Albania 2877797 0.791
3 Algeria 43851044 0.759
4 Andorra 77265 0.857
5 Angola 32866272 0.574
6 Antigua and Barbuda 97929 0.776
7 Argentina 45195774 0.83
8 Armenia 2963243 0.76
9 Australia 25499884 0.938
10 Austria 9006398 0.914
# ℹ 176 more rows抽出せず、変数名のみ変更
rename()関数を使用
例) PopulationをJinkoに、AreaをMensekiに変更
# A tibble: 186 × 18
Country Jinko Menseki GDP PPP GDP_per_capita PPP_per_capita G7
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 3.89e7 652860 1.91e4 8.27e4 491. 2125. 0
2 Albania 2.88e6 27400 1.53e4 3.97e4 5309. 13781. 0
3 Algeria 4.39e7 2381740 1.70e5 4.97e5 3876. 11324. 0
4 Andorra 7.73e4 470 3.15e3 NA 40821. NA 0
5 Angola 3.29e7 1246700 9.46e4 2.19e5 2879. 6649. 0
6 Antigua an… 9.79e4 440 1.73e3 2.08e3 17643. 21267. 0
7 Argentina 4.52e7 2736690 4.50e5 1.04e6 9949. 22938. 0
8 Armenia 2.96e6 28470 1.37e4 3.84e4 4614. 12974. 0
9 Australia 2.55e7 7682300 1.39e6 1.28e6 54615. 50001. 0
10 Austria 9.01e6 82409 4.46e5 5.03e5 49555. 55824. 0
# ℹ 176 more rows
# ℹ 10 more variables: G20 <dbl>, OECD <dbl>, HDI_2018 <dbl>,
# Polity_Score <dbl>, Polity_Type <chr>, FH_PR <dbl>, FH_CL <dbl>,
# FH_Total <dbl>, FH_Status <chr>, Continent <chr>列の除外
変数名の前に! (推奨)、または-を付ける
- 2つ以上の変数を除外する場合、変数名を
c()でまとめる。
例) dfからGDP_per_capitaとPPP_per_capitaを除外
# A tibble: 186 × 16
Country Population Area GDP PPP G7 G20 OECD HDI_2018
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 38928346 6.53e5 1.91e4 8.27e4 0 0 0 0.496
2 Albania 2877797 2.74e4 1.53e4 3.97e4 0 0 0 0.791
3 Algeria 43851044 2.38e6 1.70e5 4.97e5 0 0 0 0.759
4 Andorra 77265 4.7 e2 3.15e3 NA 0 0 0 0.857
5 Angola 32866272 1.25e6 9.46e4 2.19e5 0 0 0 0.574
6 Antigua and Barb… 97929 4.4 e2 1.73e3 2.08e3 0 0 0 0.776
7 Argentina 45195774 2.74e6 4.50e5 1.04e6 0 1 0 0.83
8 Armenia 2963243 2.85e4 1.37e4 3.84e4 0 0 0 0.76
9 Australia 25499884 7.68e6 1.39e6 1.28e6 0 1 1 0.938
10 Austria 9006398 8.24e4 4.46e5 5.03e5 0 0 1 0.914
# ℹ 176 more rows
# ℹ 7 more variables: Polity_Score <dbl>, Polity_Type <chr>, FH_PR <dbl>,
# FH_CL <dbl>, FH_Total <dbl>, FH_Status <chr>, Continent <chr>隣接する列の同時選択
:を使用
CountryからPPPまでの列:Country:PPPCountry:PPPはCountry, Population, Area, GDP, PPPと同じ意味
例) dfのCountry〜PPP, HDI_2018列を抽出
# A tibble: 186 × 6
Country Population Area GDP PPP HDI_2018
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 38928346 652860 19101. 82737. 0.496
2 Albania 2877797 27400 15278. 39658. 0.791
3 Algeria 43851044 2381740 169988. 496572. 0.759
4 Andorra 77265 470 3154. NA 0.857
5 Angola 32866272 1246700 94635. 218533. 0.574
6 Antigua and Barbuda 97929 440 1728. 2083. 0.776
7 Argentina 45195774 2736690 449663. 1036721. 0.83
8 Armenia 2963243 28470 13673. 38446. 0.76
9 Australia 25499884 7682300 1392681. 1275027. 0.938
10 Austria 9006398 82409 446315. 502771. 0.914
# ℹ 176 more rows高度な変数選択
- 特定の文字列で始まる列を選択:
starts_with()- 例)FHで始まる列の選択:
starts_with("FH")
- 例)FHで始まる列の選択:
- 特定の文字列で終わる列を選択:
ends_with() - 特定の文字列を含む列を選択:
contains()
例) dfからCountry, "FH"で始まる列を抽出
# A tibble: 186 × 5
Country FH_PR FH_CL FH_Total FH_Status
<chr> <dbl> <dbl> <dbl> <chr>
1 Afghanistan 13 14 27 NF
2 Albania 27 40 67 PF
3 Algeria 10 24 34 NF
4 Andorra 39 55 94 F
5 Angola 11 21 32 NF
6 Antigua and Barbuda 33 52 85 F
7 Argentina 35 50 85 F
8 Armenia 21 32 53 PF
9 Australia 40 57 97 F
10 Austria 37 56 93 F
# ℹ 176 more rows- 応用)
!starts_with("FH"):"FH"で始まる列を除外
列の順番変更: select()使用
抽出後のデータフレームにおける変数はselect()内で指定された順番に
例) G7からOECD列をCountryとPopulationの間へ移動
# A tibble: 186 × 18
Country G7 G20 OECD Population Area GDP PPP GDP_per_capita
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 0 0 0 38928346 6.53e5 1.91e4 8.27e4 491.
2 Albania 0 0 0 2877797 2.74e4 1.53e4 3.97e4 5309.
3 Algeria 0 0 0 43851044 2.38e6 1.70e5 4.97e5 3876.
4 Andorra 0 0 0 77265 4.7 e2 3.15e3 NA 40821.
5 Angola 0 0 0 32866272 1.25e6 9.46e4 2.19e5 2879.
6 Antigua an… 0 0 0 97929 4.4 e2 1.73e3 2.08e3 17643.
7 Argentina 0 1 0 45195774 2.74e6 4.50e5 1.04e6 9949.
8 Armenia 0 0 0 2963243 2.85e4 1.37e4 3.84e4 4614.
9 Australia 0 1 1 25499884 7.68e6 1.39e6 1.28e6 54615.
10 Austria 0 0 1 9006398 8.24e4 4.46e5 5.03e5 49555.
# ℹ 176 more rows
# ℹ 9 more variables: PPP_per_capita <dbl>, HDI_2018 <dbl>, Polity_Score <dbl>,
# Polity_Type <chr>, FH_PR <dbl>, FH_CL <dbl>, FH_Total <dbl>,
# FH_Status <chr>, Continent <chr>列の順番変更: relocate()使用
relocate()の使い方
.after = XXX:XXX列の後ろへ移動 /.before = YYY:YYY列の前へ移動
例) G7からOECD列をCountryの後ろへ移動
# A tibble: 186 × 18
Country G7 G20 OECD Population Area GDP PPP GDP_per_capita
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 0 0 0 38928346 6.53e5 1.91e4 8.27e4 491.
2 Albania 0 0 0 2877797 2.74e4 1.53e4 3.97e4 5309.
3 Algeria 0 0 0 43851044 2.38e6 1.70e5 4.97e5 3876.
4 Andorra 0 0 0 77265 4.7 e2 3.15e3 NA 40821.
5 Angola 0 0 0 32866272 1.25e6 9.46e4 2.19e5 2879.
6 Antigua an… 0 0 0 97929 4.4 e2 1.73e3 2.08e3 17643.
7 Argentina 0 1 0 45195774 2.74e6 4.50e5 1.04e6 9949.
8 Armenia 0 0 0 2963243 2.85e4 1.37e4 3.84e4 4614.
9 Australia 0 1 1 25499884 7.68e6 1.39e6 1.28e6 54615.
10 Austria 0 0 1 9006398 8.24e4 4.46e5 5.03e5 49555.
# ℹ 176 more rows
# ℹ 9 more variables: PPP_per_capita <dbl>, HDI_2018 <dbl>, Polity_Score <dbl>,
# Polity_Type <chr>, FH_PR <dbl>, FH_CL <dbl>, FH_Total <dbl>,
# FH_Status <chr>, Continent <chr>{dplyr}: 行の抽出
行の抽出: 書き方
filter()関数を使用
パイプを使わない書き方
パイプを使う書き方
行の抽出: 例
例) dfからContinentが"Europe"の行を抽出し、Country〜PPP, HDI_2018列を抽出し、HDI_2018はHDIに変更
filter()とselect()の組み合わせ- 以下の例の場合、
filter()とselect()の順番を逆にすることは不可select()後、Continent変数がなくなるため
# A tibble: 4 × 6
Country Population Area GDP PPP HDI
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Australia 25499884 7682300 1392681. 1275027. 0.938
2 Fiji 896445 18270 5536. 12496. 0.724
3 New Zealand 4842780 263820 206929. 204260. 0.921
4 Papua New Guinea 8947024 452860 24970. 37319. 0.543行の抽出: 2つ以上の条件(AND)
2つ以上の条件を同時に満たす行を抽出
,で条件式を追加するだけ (&もOK; むしろ&を推奨)
例) dfから「Continentが"Asia"(条件1)」、「HDI_2018が0.8以上(条件2)」の行を抽出し、CountryとHDI_2018列を抽出
- 条件1 AND 条件2 \(\Rightarrow\) 条件1 & 条件3
# A tibble: 13 × 2
Country HDI_2018
<chr> <dbl>
1 Bahrain 0.838
2 Brunei 0.845
3 Israel 0.906
4 Japan 0.915
5 Kazakhstan 0.817
6 South Korea 0.906
7 Kuwait 0.808
8 Malaysia 0.804
9 Oman 0.834
10 Qatar 0.848
11 Saudi Arabia 0.857
12 Singapore 0.935
13 United Arab Emirates 0.866行の抽出: 2つ以上の条件(OR)
2つ以上の条件を片方か両方に満たす行を抽出
|で条件式を追加するだけ
例) dfから「Continentが"Asia"(条件1)か"Oceania"(条件2)」であり、かつ「HDI_2018が0.9以上(条件3)」の行を抽出し、CountryとHDI_2018、Continent列を抽出
- (条件1 OR 条件2) AND 条件3 \(\Rightarrow\) (条件1 | 条件2) & 条件3
# A tibble: 6 × 3
Country HDI_2018 Continent
<chr> <dbl> <chr>
1 Australia 0.938 Oceania
2 Israel 0.906 Asia
3 Japan 0.915 Asia
4 South Korea 0.906 Asia
5 New Zealand 0.921 Oceania
6 Singapore 0.935 Asia %in%演算子
%in%: |の代わりに使用可能な便利な演算子
例) Continentの値がc("Asia", "Oceainia")の要素に含まれている場合
# A tibble: 6 × 3
Country HDI_2018 Continent
<chr> <dbl> <chr>
1 Australia 0.938 Oceania
2 Israel 0.906 Asia
3 Japan 0.915 Asia
4 South Korea 0.906 Asia
5 New Zealand 0.921 Oceania
6 Singapore 0.935 Asia 欠損値が含まれた行の扱い
dfのPPPが欠損している行を抽出し、CountryからPPP列まで出力
変数名 == NAを条件にしてはいけない
欠損値が含まれた行の扱い
dfのPPPが欠損している行を抽出し、CountryからPPP列まで出力
- 正解:
is.na(変数名)
# A tibble: 8 × 5
Country Population Area GDP PPP
<chr> <dbl> <dbl> <dbl> <dbl>
1 Andorra 77265 470 3154. NA
2 Cuba 11326616 106440 100023 NA
3 Holy See 801 0 NA NA
4 Liechtenstein 38128 160 6553. NA
5 Monaco 39242 1 7188. NA
6 Somalia 15893222 627340 917. NA
7 Syria 17500658 183630 40405. NA
8 Western Sahara 597339 266000 909. NA欠損値が含まれた行の除外
dfのPPPが欠損している行を除外し、CountryからPPP列まで出力
- 否定を意味する
!を使用する
# A tibble: 178 × 5
Country Population Area GDP PPP
<chr> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 38928346 652860 19101. 82737.
2 Albania 2877797 27400 15278. 39658.
3 Algeria 43851044 2381740 169988. 496572.
4 Angola 32866272 1246700 94635. 218533.
5 Antigua and Barbuda 97929 440 1728. 2083.
6 Argentina 45195774 2736690 449663. 1036721.
7 Armenia 2963243 28470 13673. 38446.
8 Australia 25499884 7682300 1392681. 1275027.
9 Austria 9006398 82409 446315. 502771.
10 Azerbaijan 10139177 82658 48048. 144556.
# ℹ 168 more rowsもう一つの方法
drop_na()関数を利用
()内で指定した変数が欠損している行をすべて除外(複数指定可)
# A tibble: 155 × 6
Country Population Area GDP PPP Polity_Score
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 38928346 652860 19101. 82737. -1
2 Albania 2877797 27400 15278. 39658. 9
3 Algeria 43851044 2381740 169988. 496572. 2
4 Angola 32866272 1246700 94635. 218533. -2
5 Argentina 45195774 2736690 449663. 1036721. 9
6 Armenia 2963243 28470 13673. 38446. 7
7 Australia 25499884 7682300 1392681. 1275027. 10
8 Austria 9006398 82409 446315. 502771. 10
9 Azerbaijan 10139177 82658 48048. 144556. -7
10 Bahrain 1701575 760 38574. 74230. -10
# ℹ 145 more rows{dplyr}: 行のソート
行のソート: 書き方
arrange()関数を使用
パイプを使わない書き方
パイプを使う書き方
基本的には昇順 (値が小さい行が先にくる)
- 降順にする場合は
desc(変数名) 変数名1を基準にソートし、同点の場合は変数名2を基準に
行のソート: 例
例) dfからContinentの値が"Africa"の行のみを抽出し、Polity_Scoreが高い行を上位にする。そして、CountryとPPP_per_capita、Polity_Score列のみ残す。
- Polity Scoreが高い (低い) = より民主主義 (権威主義)に近い
# A tibble: 54 × 3
Country PPP_per_capita Polity_Score
<chr> <dbl> <dbl>
1 Mauritius 22637. 10
2 Kenya 4105. 9
3 South Africa 12605. 9
4 Botswana 17311. 8
5 Ghana 5097. 8
6 Lesotho 3019. 8
7 Benin 3067. 7
8 Liberia 1461. 7
9 Nigeria 5018. 7
10 Senegal 3248. 7
# ℹ 44 more rows行のソート: 応用
dfからアフリカのみを抽出し、Polity_Scoreが低い行を上位にPolity_Scoreが同点の場合、PPP_per_capitaが高い行を上位にCountryとPolity_Score,PPP_per_capita列のみ残すPolity_ScoreはPolityに、PPP_per_capitaはPPPと名前を変更
# A tibble: 54 × 3
Country Polity PPP
<chr> <dbl> <dbl>
1 Eswatini -9 8634.
2 Eritrea -7 1860.
3 Equatorial Guinea -6 19458.
4 Egypt -4 11198.
5 Morocco -4 7554.
6 Sudan -4 4063.
7 Cameroon -4 3506.
8 Congo (Brazzaville) -4 3191.
9 Comoros -3 3007.
10 Rwanda -3 2008.
# ℹ 44 more rows