ミクロ政治データ分析実習
6/ データ型
Factor型
- 順序付き文字型
- 主に図表を作成する際に使用する。
列名の下が<chr>ならcharacter型、<fct>ならfactor型
大学名がcharacter型の場合
# A tibble: 4 × 2
大学名 学生数
<chr> <dbl>
1 Ritsumeikan 32467
2 Kwansei-gakuin 23671
3 Kansai 27736
4 Doshisha 25974大学名がfactor型の場合
- 順番は関西-関学-同志社-立命館
# A tibble: 4 × 2
大学名 学生数
<fct> <dbl>
1 Ritsumeikan 32467
2 Kwansei-gakuin 23671
3 Kansai 27736
4 Doshisha 25974行のソートについてはデータ・ハンドリングの講義にて解説
大学名がcharacter型の場合
- アルファベット順になる。
# A tibble: 4 × 2
大学名 学生数
<chr> <dbl>
1 Doshisha 25974
2 Kansai 27736
3 Kwansei-gakuin 23671
4 Ritsumeikan 32467大学名がfactor型の場合
- 予め指定した順番で表示される。
# A tibble: 4 × 2
大学名 学生数
<fct> <dbl>
1 Kansai 27736
2 Kwansei-gakuin 23671
3 Doshisha 25974
4 Ritsumeikan 32467作図については可視化の講義にて解説
大学名がcharacter型の場合
- アルファベット順になる。
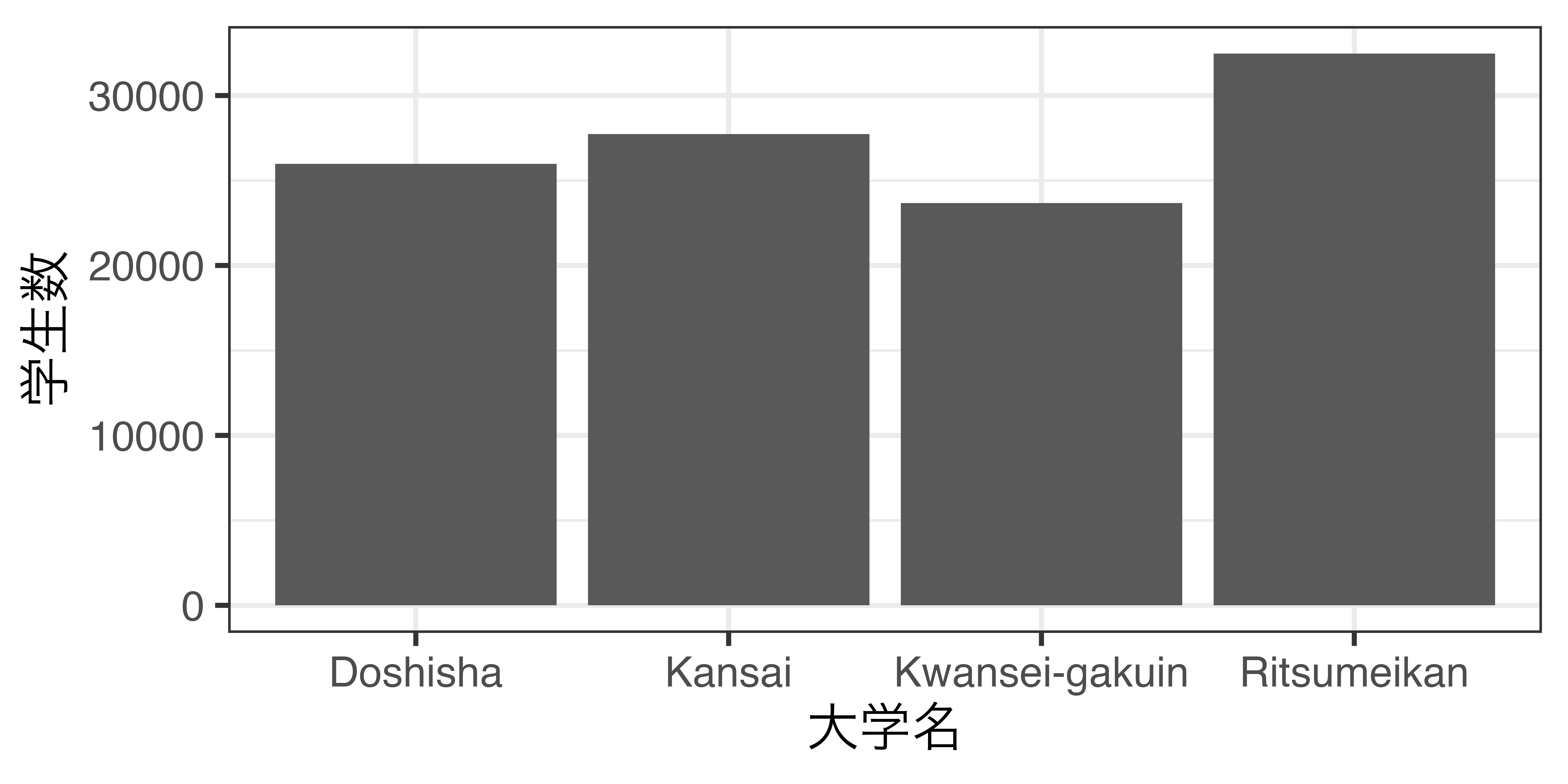
大学名がfactor型の場合
- 予め指定した順番で表示される。
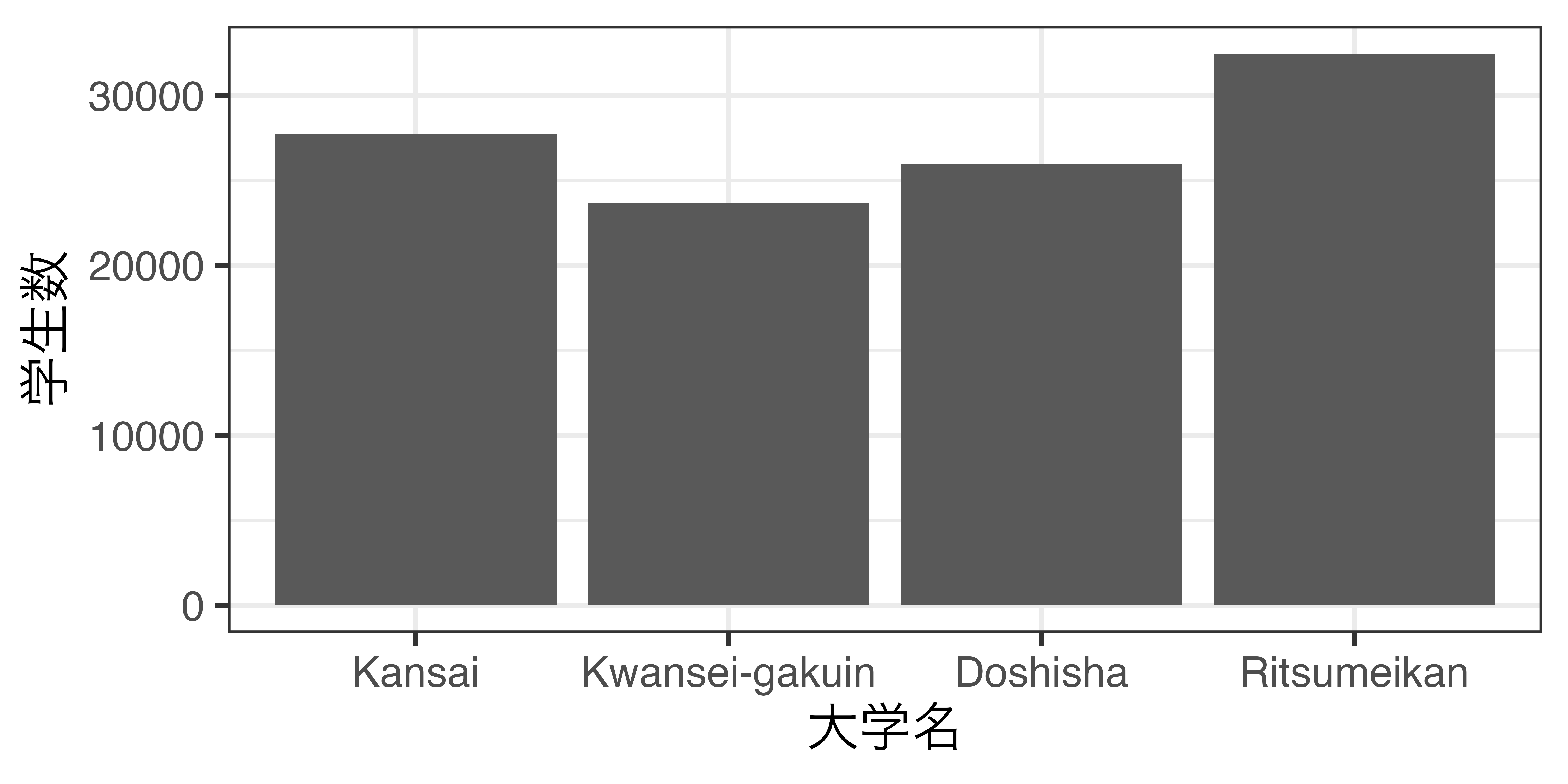
NAとNULL (2)
初心者レベルでNULLを使うことはないが、中級以上からは(そこそこ)使う機会がある。
