[1] 193.5 402.5方法論特殊講義III
マッチング
2025-08-18
条件付き独立の仮定とは
| ID (i) | Zi | Ti | Y0, i | Y1, i |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 1 |
| 2 | 0 | 0 | 1 | 0 |
| 3 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 |
| 5 | 0 | 1 | 0 | 0 |
| 6 | 0 | 1 | 1 | 0 |
| 7 | 0 | 1 | 0 | 0 |
| 8 | 0 | 1 | 0 | 1 |
| 9 | 1 | 0 | 1 | 1 |
| 10 | 1 | 0 | 1 | 0 |
| 11 | 1 | 0 | 0 | 1 |
| 12 | 1 | 1 | 1 | 1 |
| 13 | 1 | 1 | 1 | 1 |
| 14 | 1 | 1 | 0 | 1 |
| 15 | 1 | 1 | 0 | 1 |
| 16 | 1 | 1 | 0 | 1 |
| 17 | 1 | 1 | 1 | 1 |
| 18 | 1 | 1 | 1 | 0 |
| 19 | 1 | 1 | 1 | 0 |
| 20 | 1 | 1 | 1 | 0 |
| X | Y0 | Y1 |
|---|---|---|
| T = 0 | 0.429 | 0.429 |
| T = 1 | 0.538 | 0.538 |
- 処置効果は0.538 − 0.429 = 0.109
- もし、統制群と処置群が同質なら
- A = C、そしてB = Dのはず
- 処置群がもし統制群になっても、今の統制群と同じ
- \(\Rightarrow\) 交換可能性が成立せず

条件付き独立の仮定とは
| ID (i) | Zi | Ti | Y0, i | Y1, i |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 1 |
| 2 | 0 | 0 | 1 | 0 |
| 3 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 |
| 5 | 0 | 1 | 0 | 0 |
| 6 | 0 | 1 | 1 | 0 |
| 7 | 0 | 1 | 0 | 0 |
| 8 | 0 | 1 | 0 | 1 |
| 9 | 1 | 0 | 1 | 1 |
| 10 | 1 | 0 | 1 | 0 |
| 11 | 1 | 0 | 0 | 1 |
| 12 | 1 | 1 | 1 | 1 |
| 13 | 1 | 1 | 1 | 1 |
| 14 | 1 | 1 | 0 | 1 |
| 15 | 1 | 1 | 0 | 1 |
| 16 | 1 | 1 | 0 | 1 |
| 17 | 1 | 1 | 1 | 1 |
| 18 | 1 | 1 | 1 | 0 |
| 19 | 1 | 1 | 1 | 0 |
| 20 | 1 | 1 | 1 | 0 |
\(Z\) で条件づけた場合 ( \(Z = 0\) )
| X | Y0 | Y1 |
|---|---|---|
| T = 0 | 0.250 | 0.250 |
| T = 1 | 0.250 | 0.250 |
- 処置効果は0.250 − 0.250 = 0.000
- もし、統制群と処置群が同質なら
- A = C、そしてB = Dが成立
- \(\Rightarrow\) 交換可能性が成立

条件付き独立の仮定とは
| ID (i) | Zi | Ti | Y0, i | Y1, i |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 1 |
| 2 | 0 | 0 | 1 | 0 |
| 3 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 |
| 5 | 0 | 1 | 0 | 0 |
| 6 | 0 | 1 | 1 | 0 |
| 7 | 0 | 1 | 0 | 0 |
| 8 | 0 | 1 | 0 | 1 |
| 9 | 1 | 0 | 1 | 1 |
| 10 | 1 | 0 | 1 | 0 |
| 11 | 1 | 0 | 0 | 1 |
| 12 | 1 | 1 | 1 | 1 |
| 13 | 1 | 1 | 1 | 1 |
| 14 | 1 | 1 | 0 | 1 |
| 15 | 1 | 1 | 0 | 1 |
| 16 | 1 | 1 | 0 | 1 |
| 17 | 1 | 1 | 1 | 1 |
| 18 | 1 | 1 | 1 | 0 |
| 19 | 1 | 1 | 1 | 0 |
| 20 | 1 | 1 | 1 | 0 |
\(Z\) で条件づけた場合 ( \(Z = 1\) )
| X | Y0 | Y1 |
|---|---|---|
| T = 0 | 0.667 | 0.667 |
| T = 1 | 0.667 | 0.667 |
- 処置効果は0.667 − 0.667 = 0.000
- もし、統制群と処置群が同質なら
- A = C、そしてB = Dが成立
- \(\Rightarrow\) 交換可能性が成立
Exact Matching
- 「正確マッチング」、「厳格なマッチング」などで訳される
- これまで見てきた方法が Exact Matching
- データ内の共変量 (交絡要因) が完全に一致するケース同士の比較
- 共変量が少数、かつ、名目or順序変数の場合、使用可
- 共変量が多数、または連続変数の場合は実質的に無理
- 次元の呪い or 次元爆発

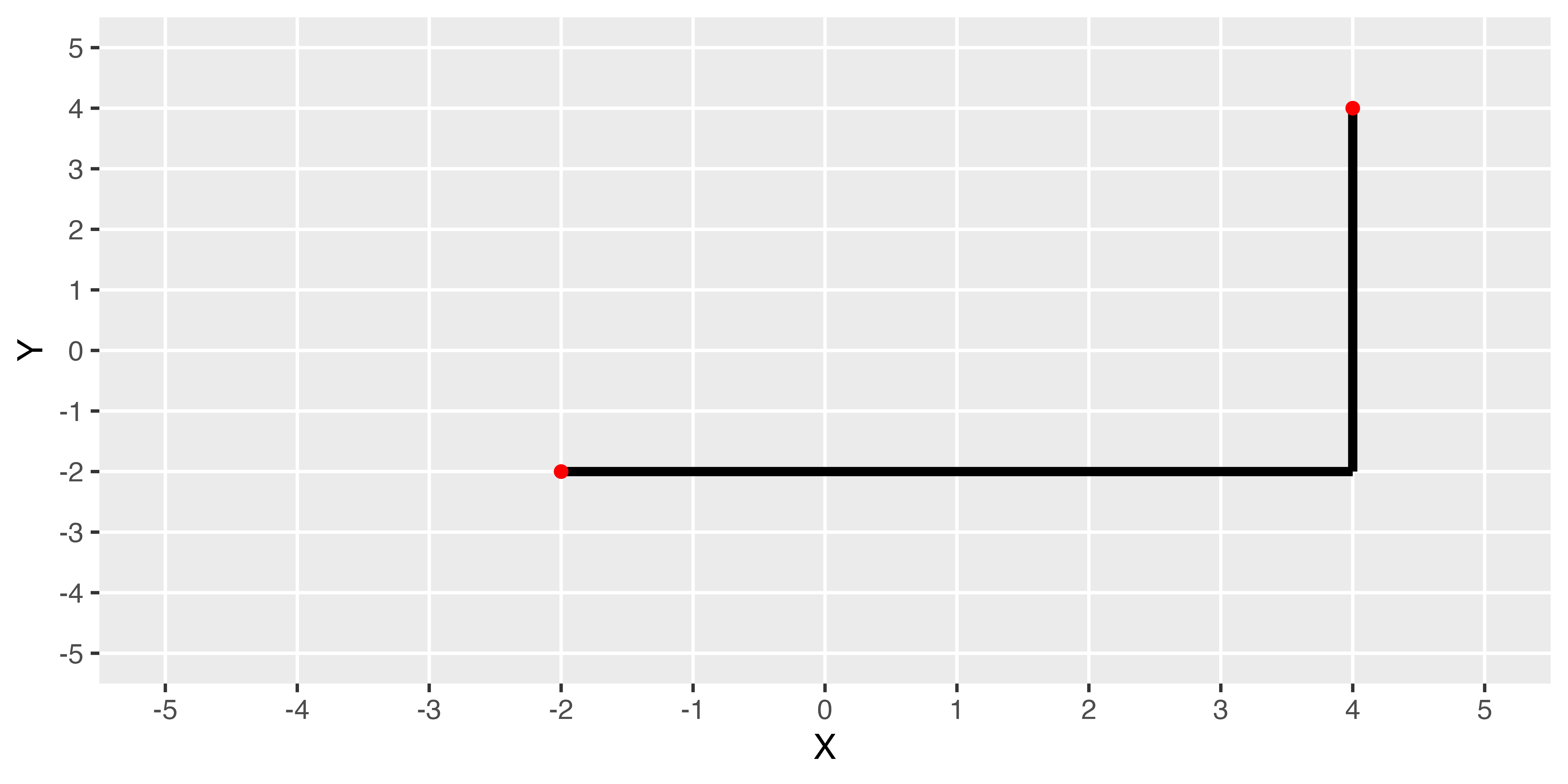
マンハッタン距離(Manhattan Distance; City-block Distance)
\[d(i, j) = |X_i - X_j| + |Y_i - Y_j| \text{ where } i \neq j.\]
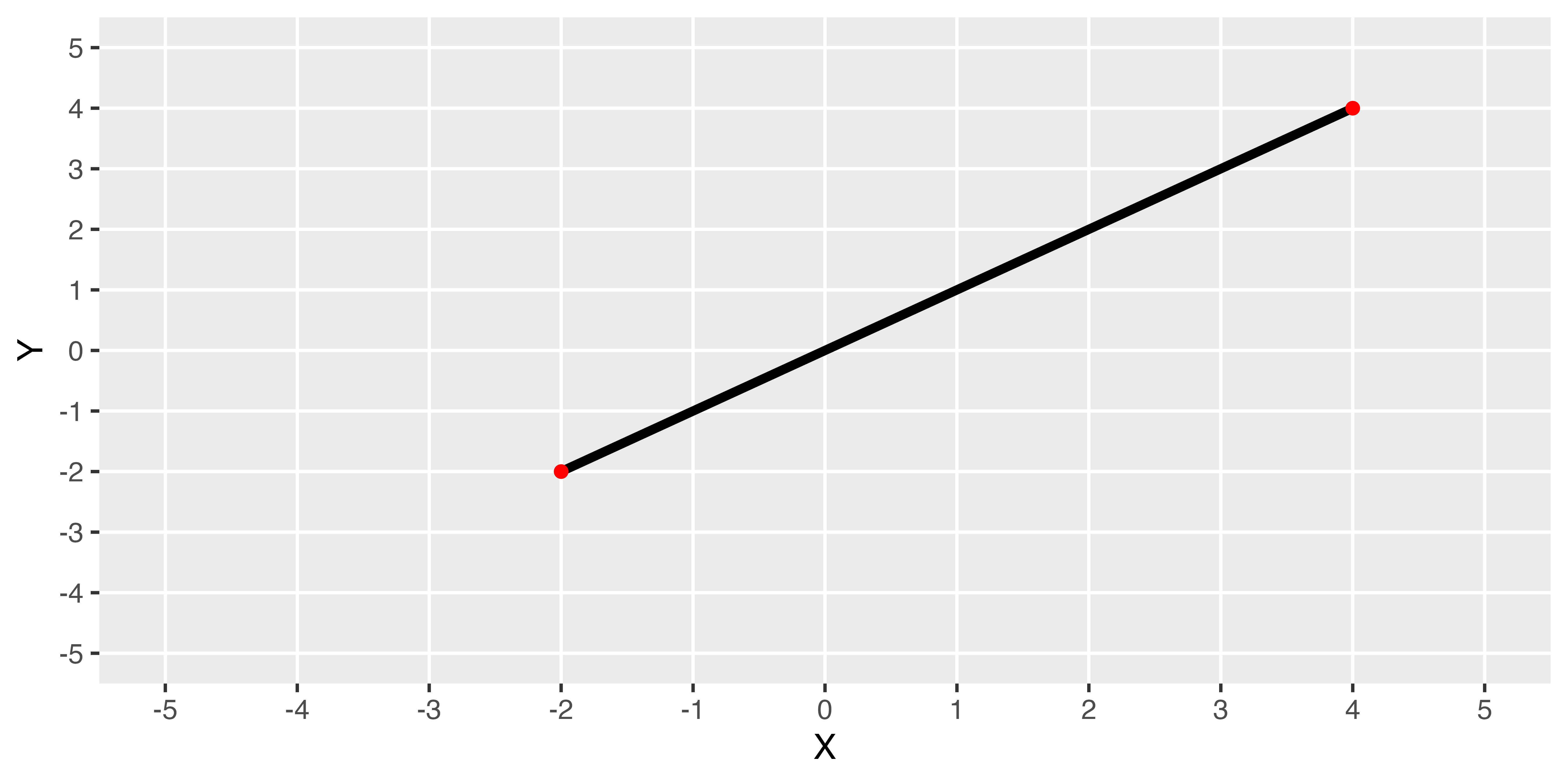
標準化ユークリッド距離(Standardized Euclidean Distance)
\[d(i, j) = \sqrt{\Bigg(\frac{X_i - X_j}{\sigma_X}\Bigg)^2 + \Bigg(\frac{Y_i - Y_j}{\sigma_Y}\Bigg)^2} \text{ where } i \neq j.\]

マハラノビス距離(Mahalanobis Distance)
- 共変量間の相関が0(\(\rho = 0\))の場合、Standardized Euclidean Distanceと同じ
\[d(i, j) = \sqrt{\frac{1}{1 - \rho^2_{X, Y}} \Bigg[\Bigg(\frac{X_i - X_j}{\sigma_X}\Bigg)^2 + \Bigg(\frac{Y_i - Y_j}{\sigma_Y}\Bigg)^2 - 2\rho_{X,Y}\Bigg(\frac{X_i - X_j}{\sigma_X}\Bigg) \Bigg(\frac{Y_i - Y_j}{\sigma_Y}\Bigg)\Bigg]} \text{ where } i \neq j.\]

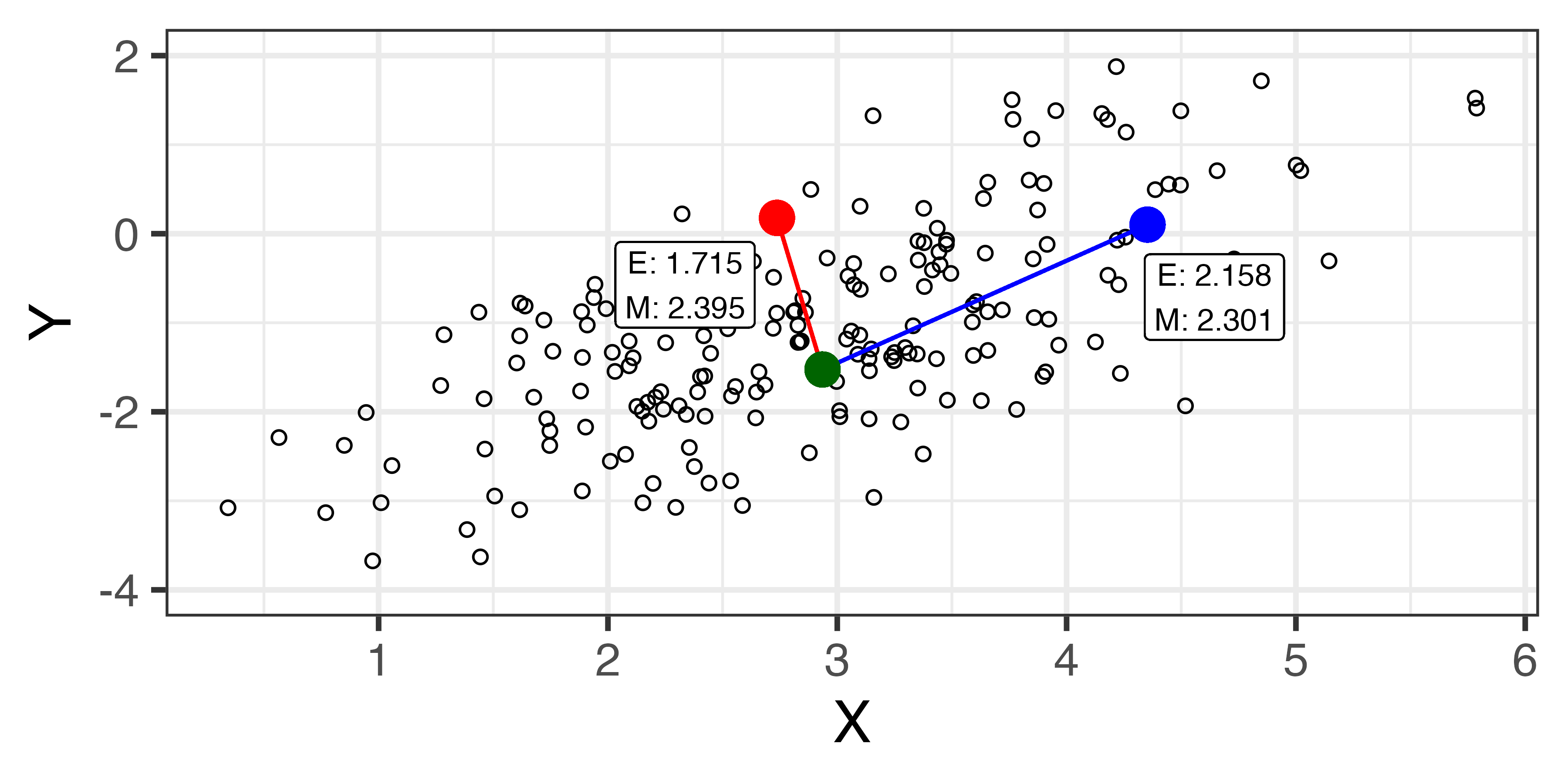
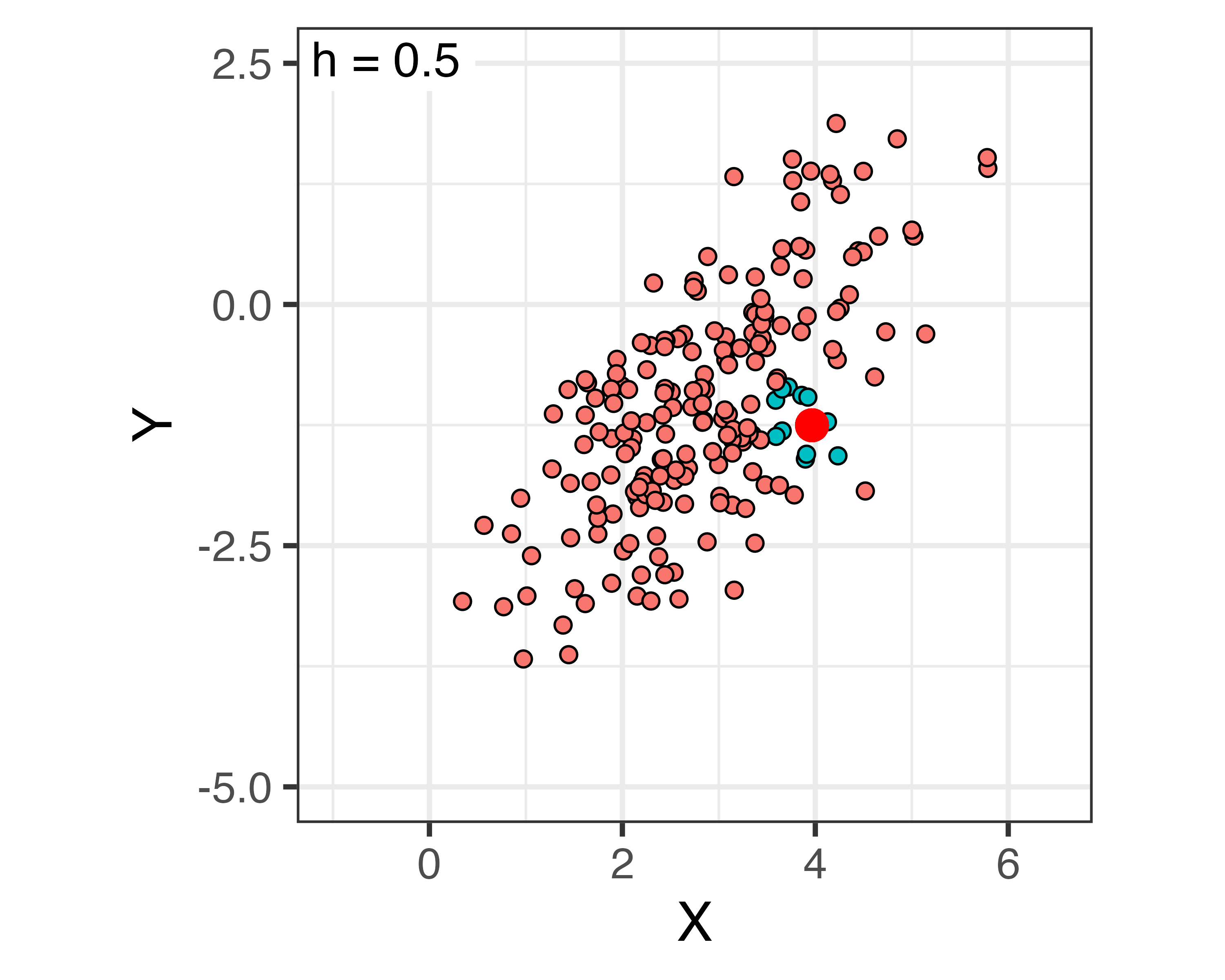
Caliper Matching
「カリパーマッチング」と訳される(訳されてない…?)
- 半径 \(h\) の中にある全てのケースの平均値を潜在的結果として使用
\[Y_i(T_i = 0) = \begin{cases}Y_i & \text{ if } T_i = 0\\ \frac{\sum_{j=1}^N I(T_j = 0, d(i, j) < h)\cdot Y_i}{\sum_{j=1}^N I(T_j = 0, d(i, j) < h)} & \text{ if } T_i = 1\end{cases}\]

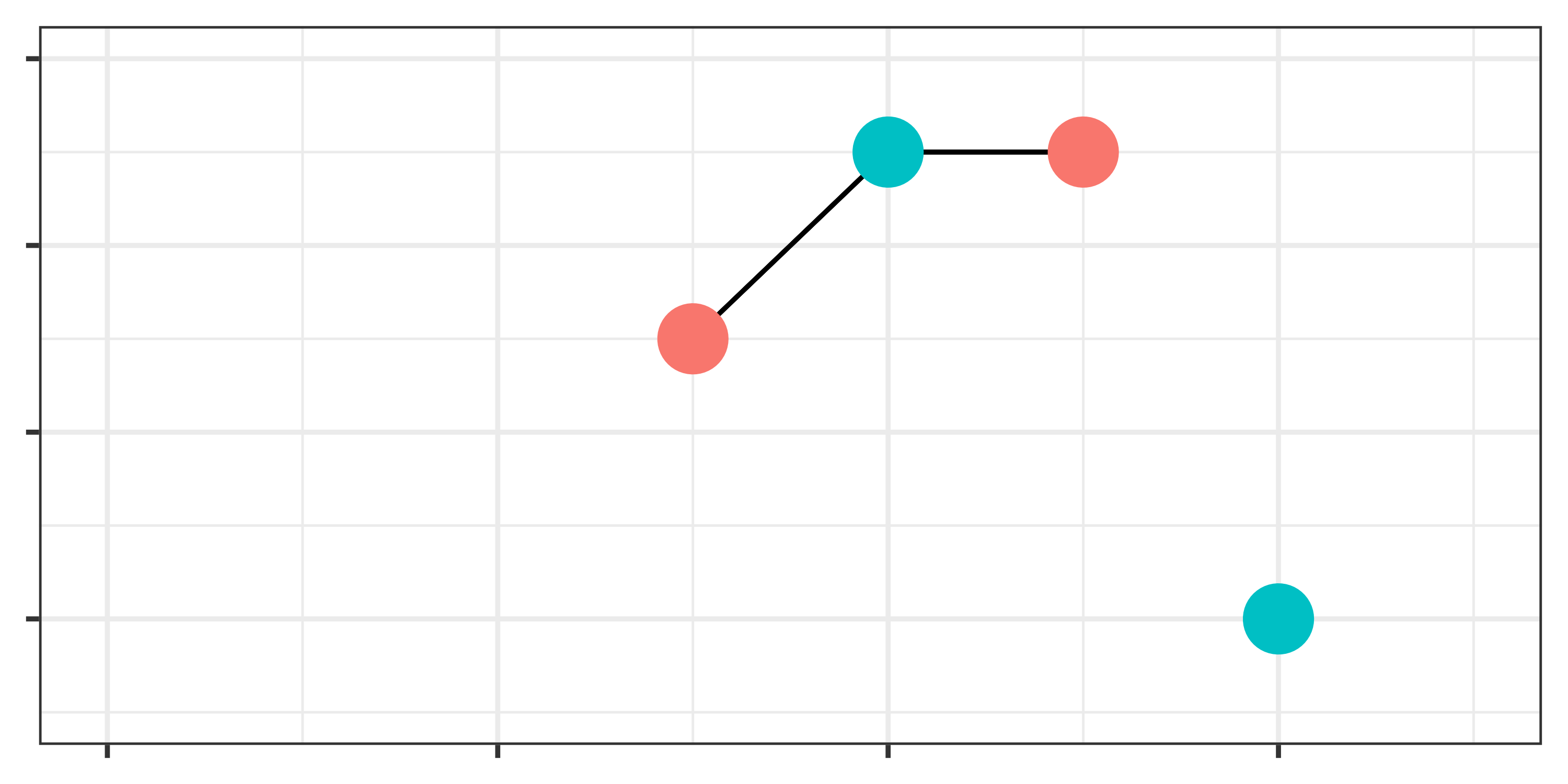
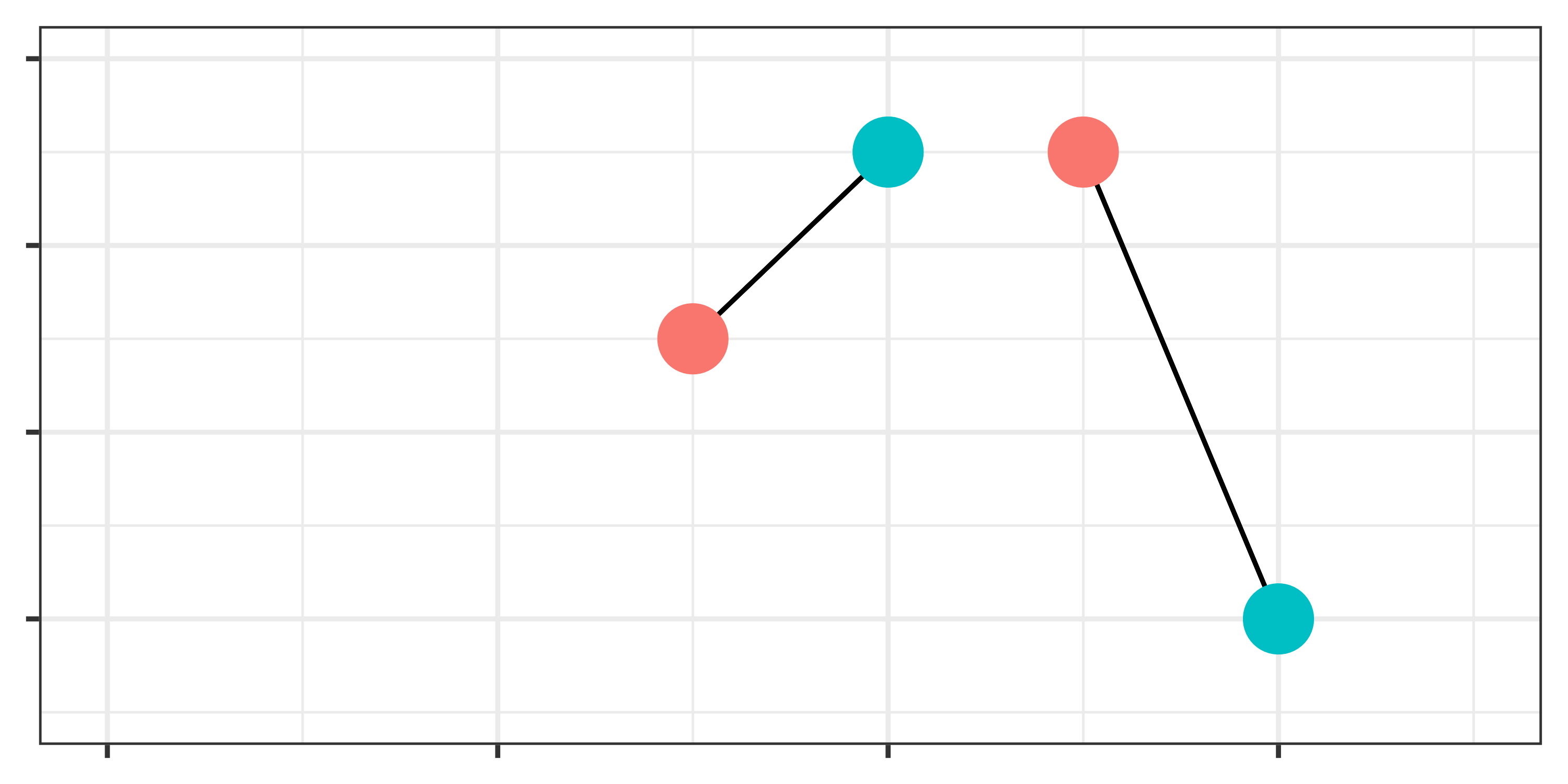
復元マッチングと非復元マッチング
- 1:1マッチングの場合に生じる問題:マッチング済みの統制群(or 処置群)をどう扱うか
- 他にも近い処置群のケースがあればマッチング \(\rightarrow\) 復元マッチング
- 他にも近い処置群のケースがあっても使わない \(\rightarrow\) 非復元マッチング
- 復元マッチングの場合、統制群の各ケースに重みが付与される。
- 加重平均 or 重み付け回帰分析が必要
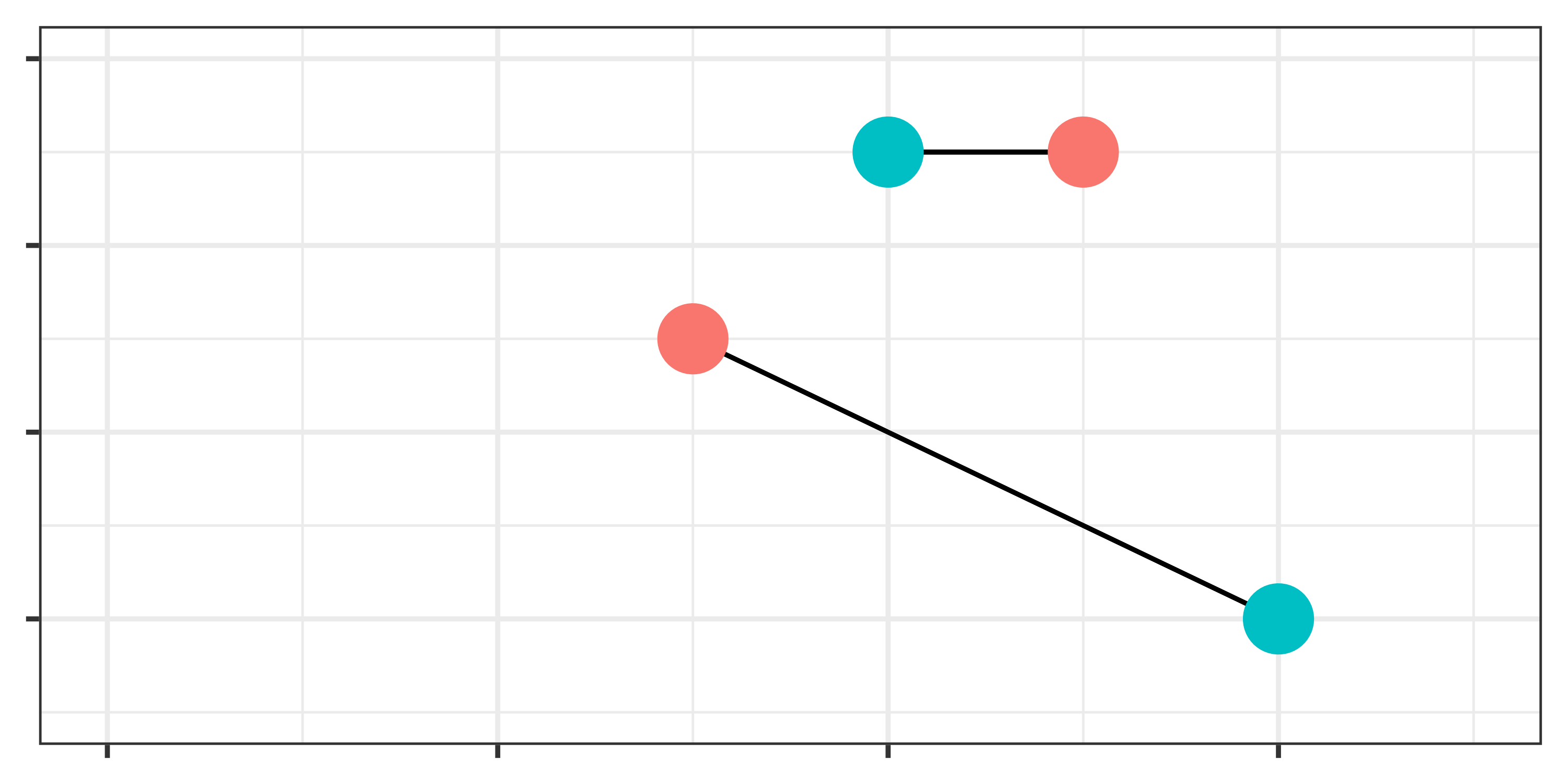
- 多くのパッケージは非復元がデフォルトとなっているが、推定ごとに結果が変化することも(図BとC)
- 復元マッチングはバランスが改善されやすいが、サンプルサイズが小さくなる。
- 正しい方法はなく、分析者の判断が必要。
- 下の例はATT推定の例(赤が処置群、青は統制群)
IPWの考え方

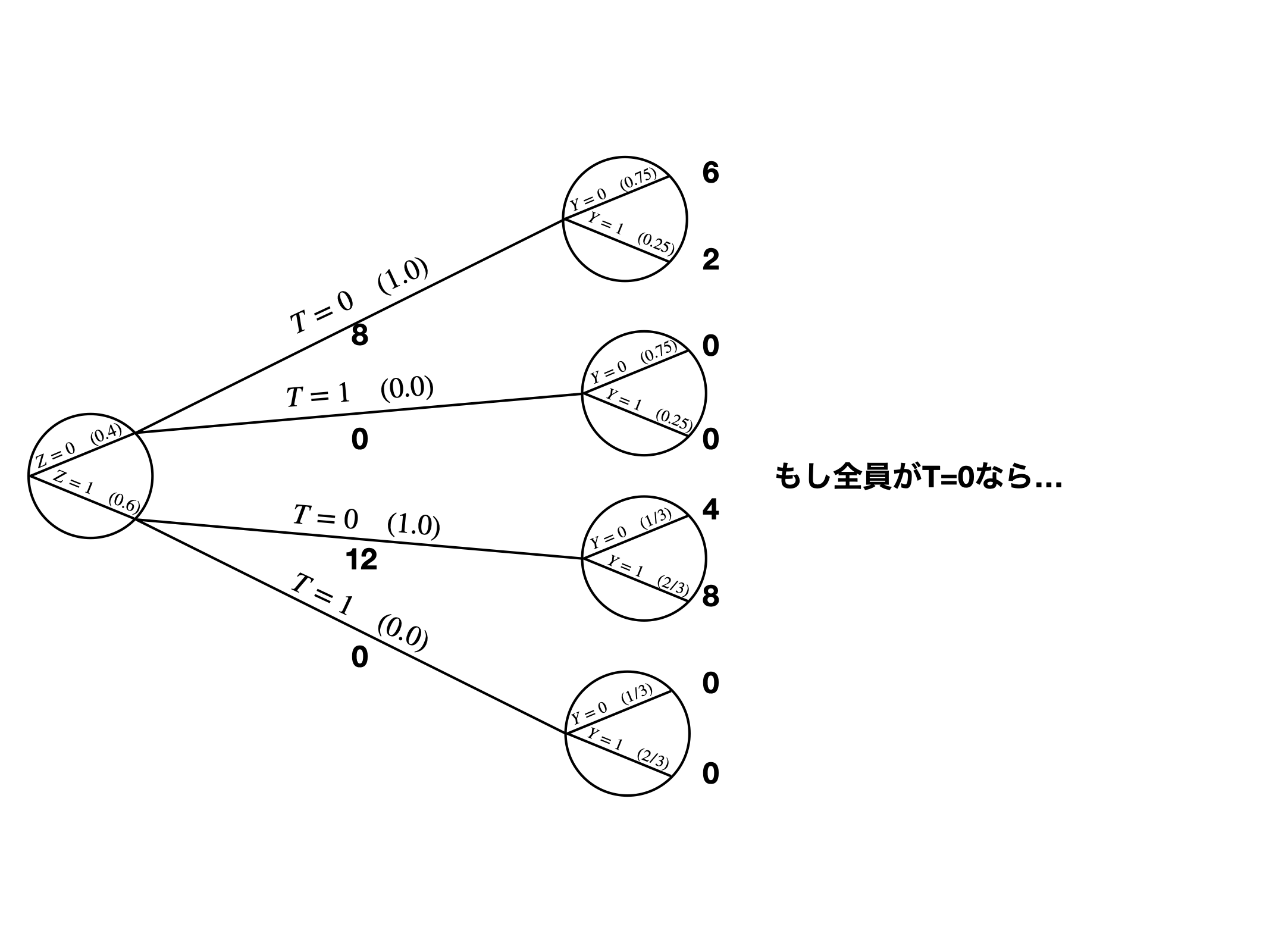
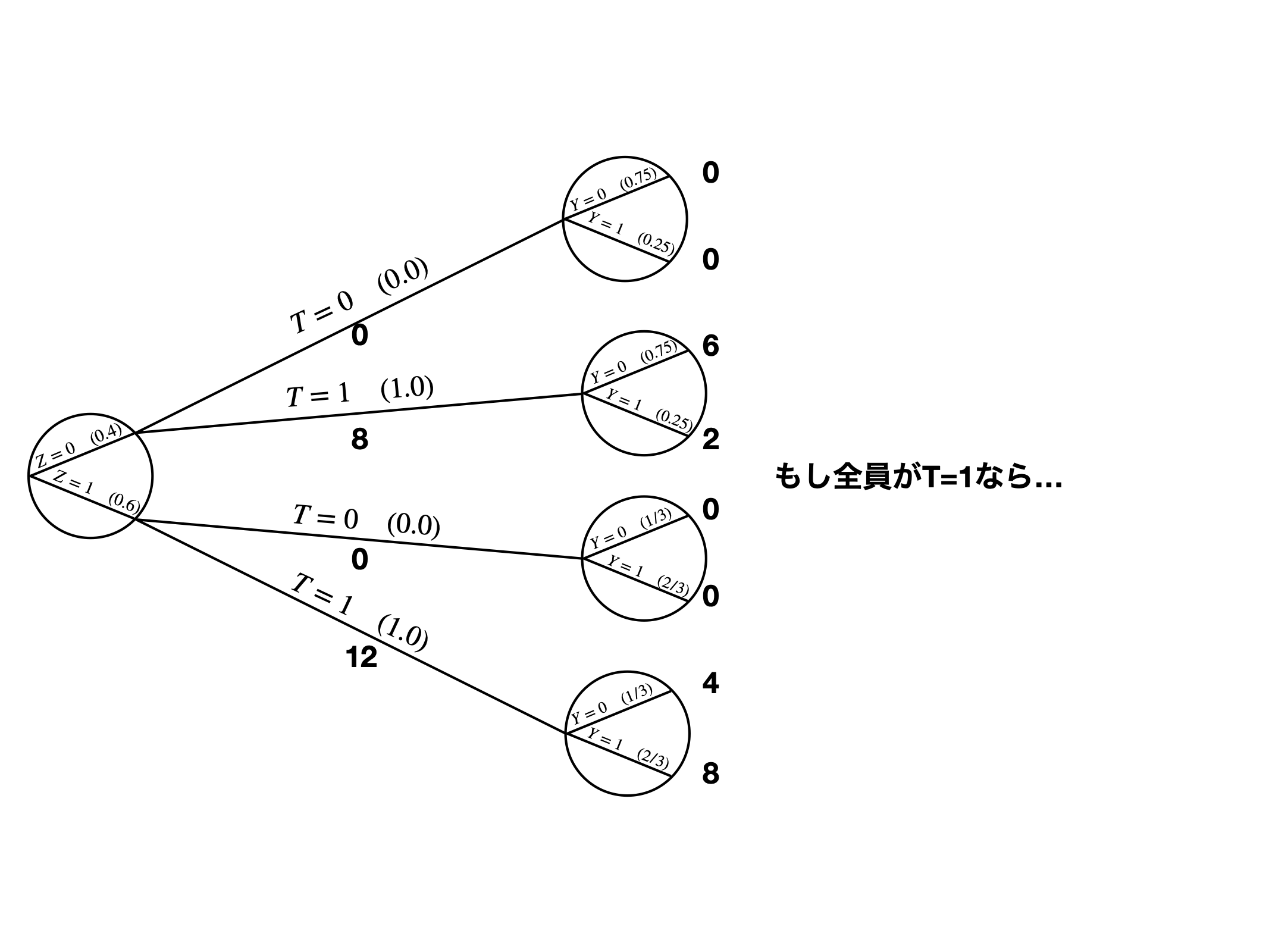
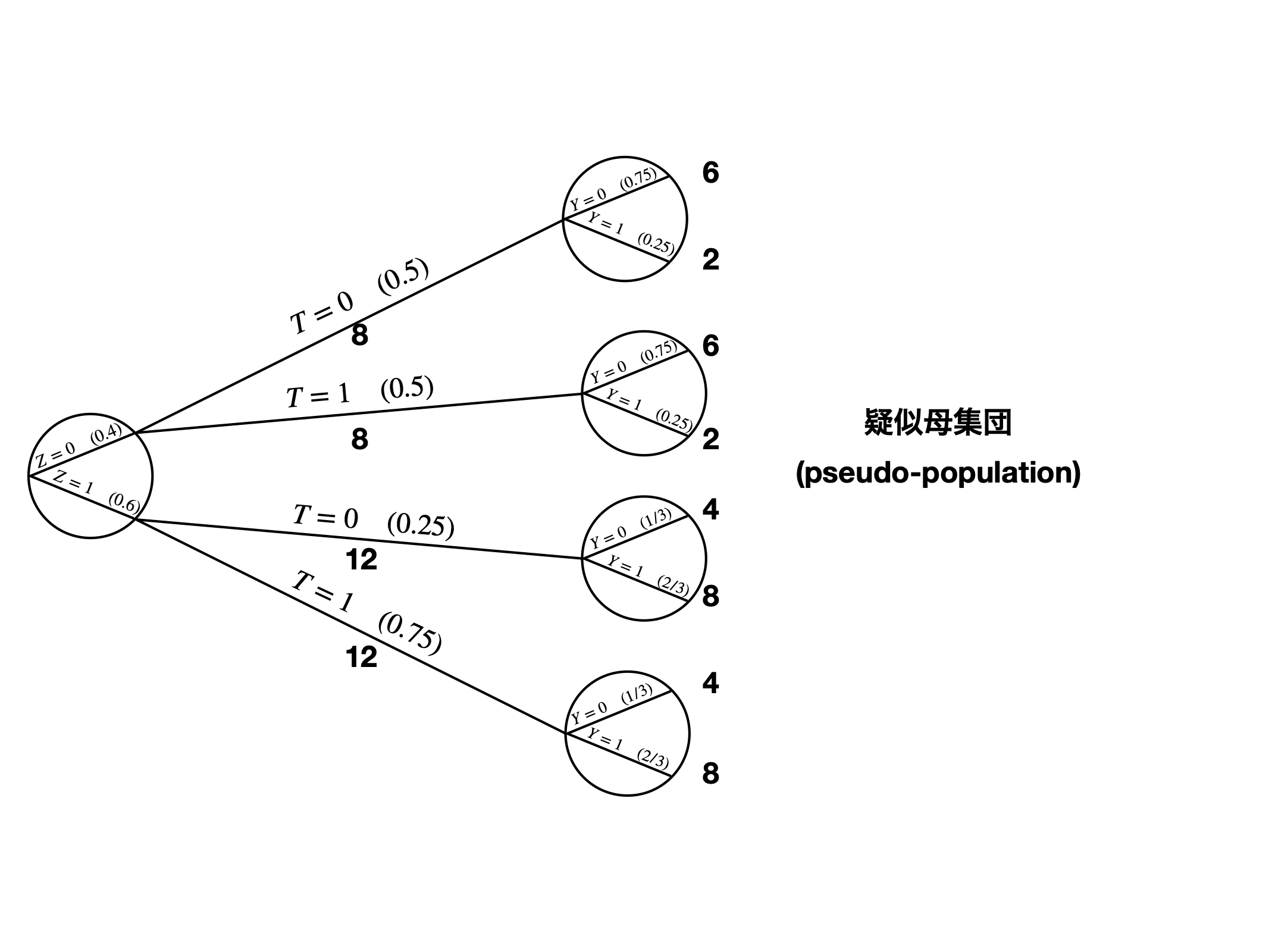
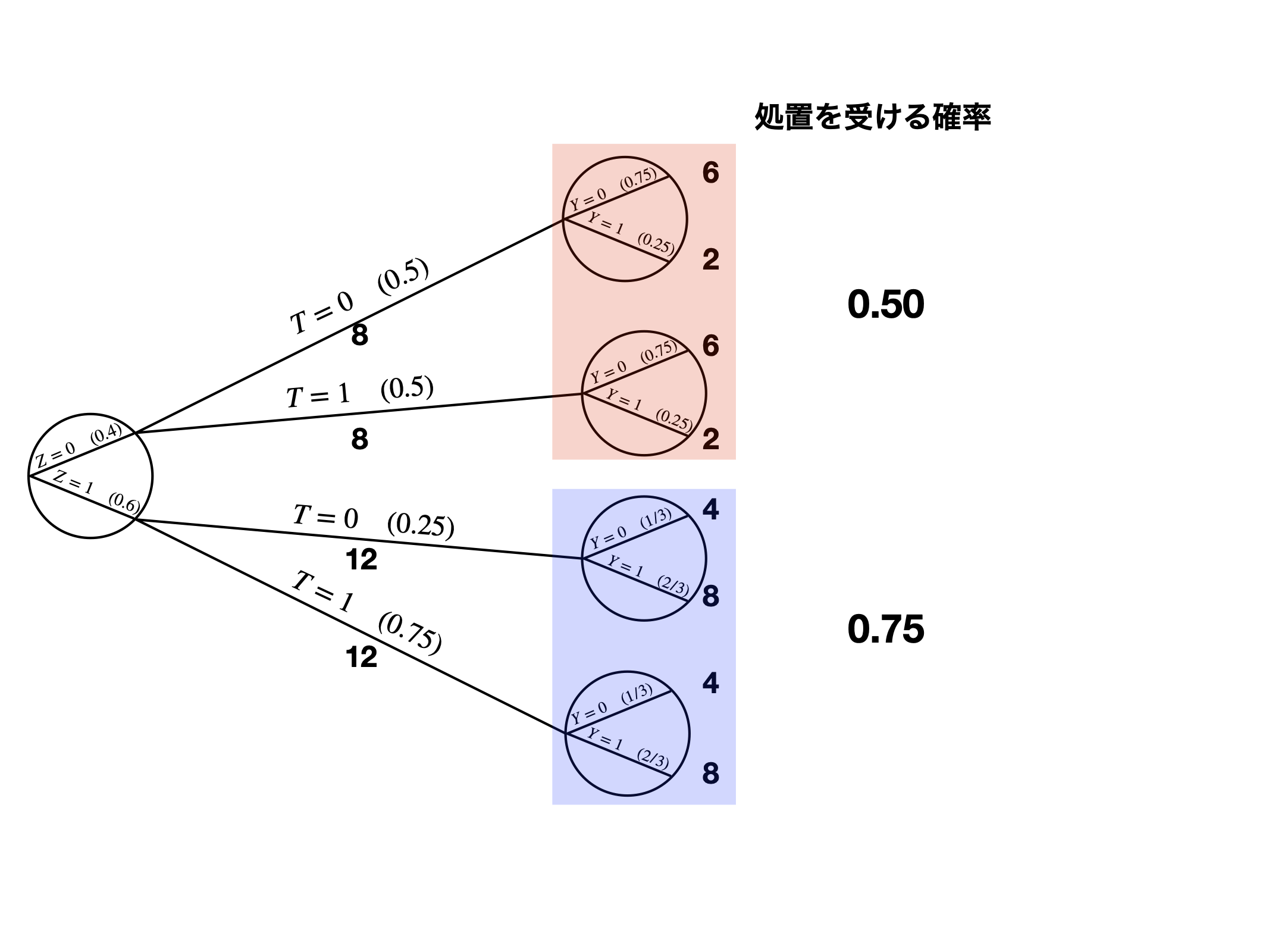
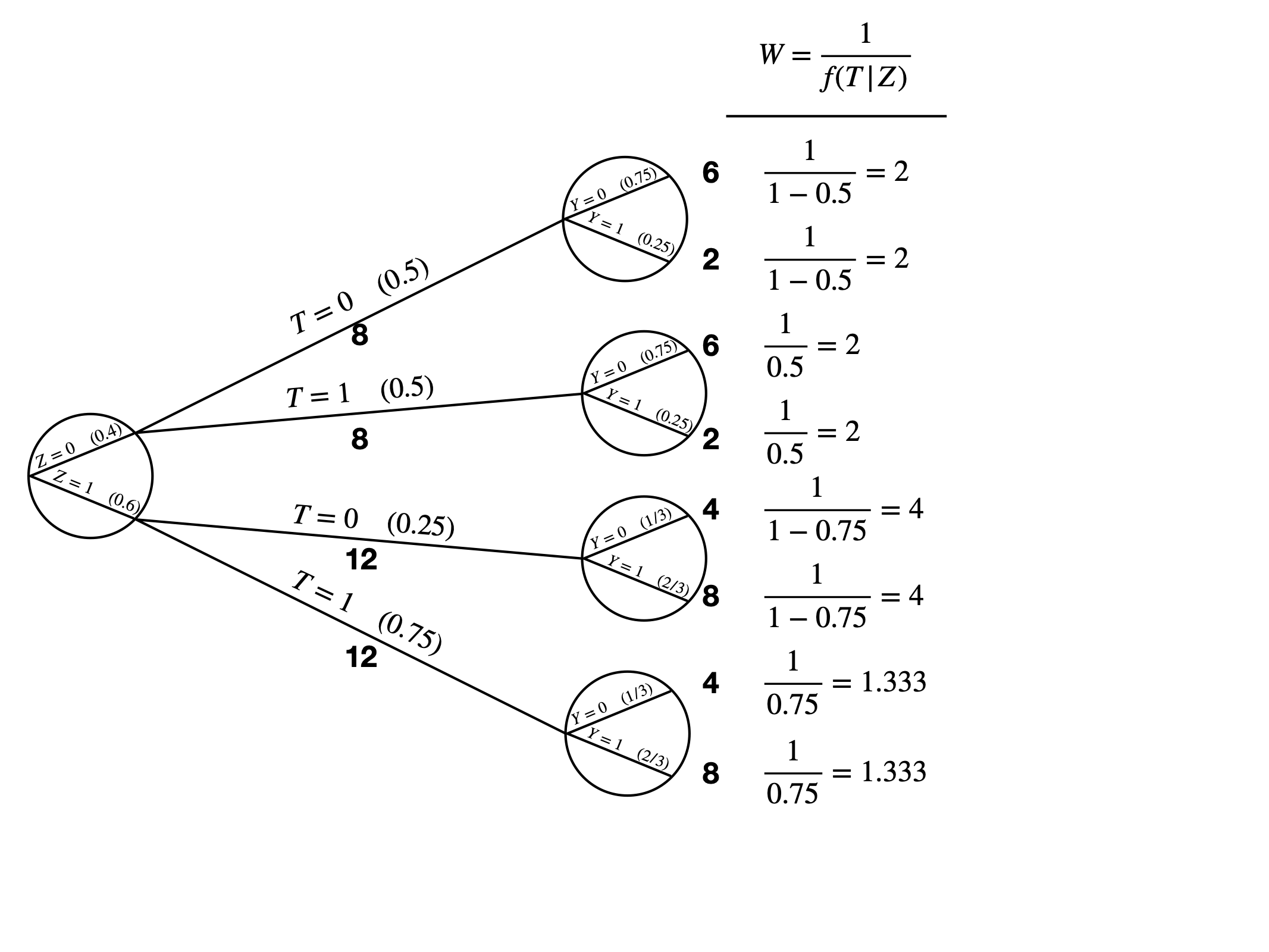
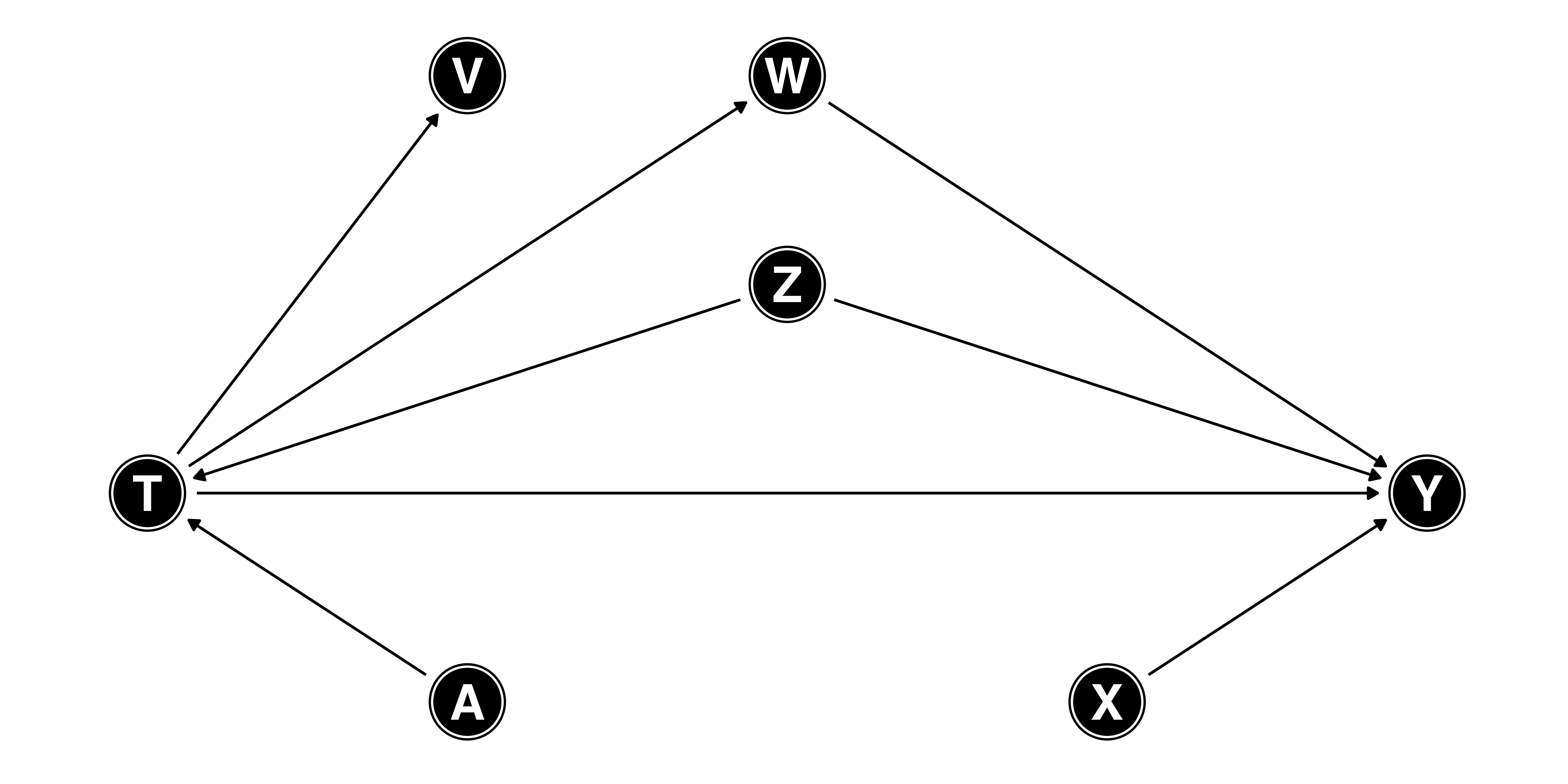
ダイアグラムを使った例
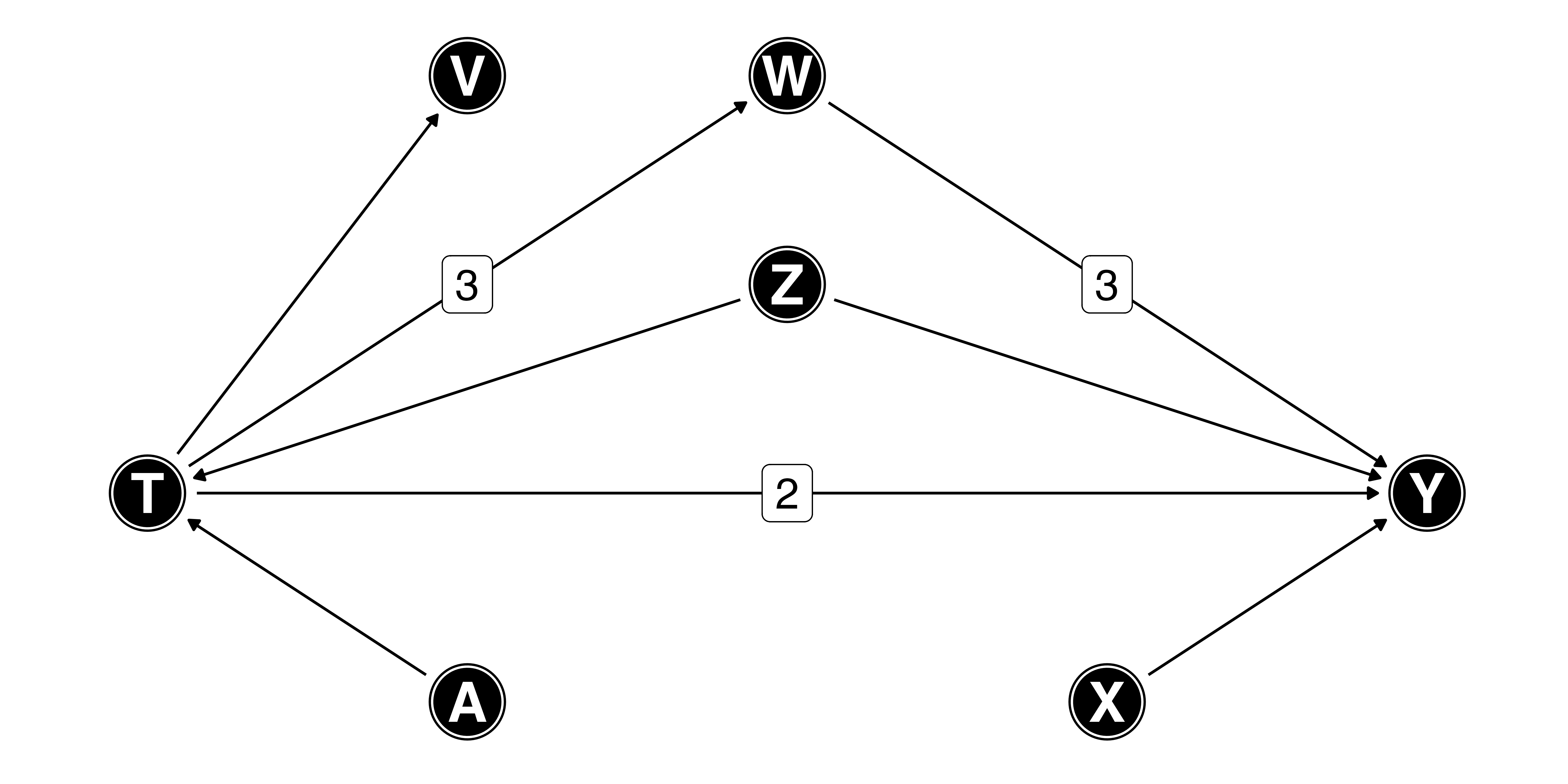
- \(T \rightarrow Y\)の効果は11
- \(Z\): \(T\)と\(Y\)の原因 \(\leftarrow\) 投入
- \(A\): 操作変数 \(\leftarrow\) 除外
- \(X\): \(Y\)の原因 \(\leftarrow\) 投入
- \(V\): \(T\)の結果 \(\leftarrow\) 除外
- \(W\)は…?
ダイアグラムを使った例
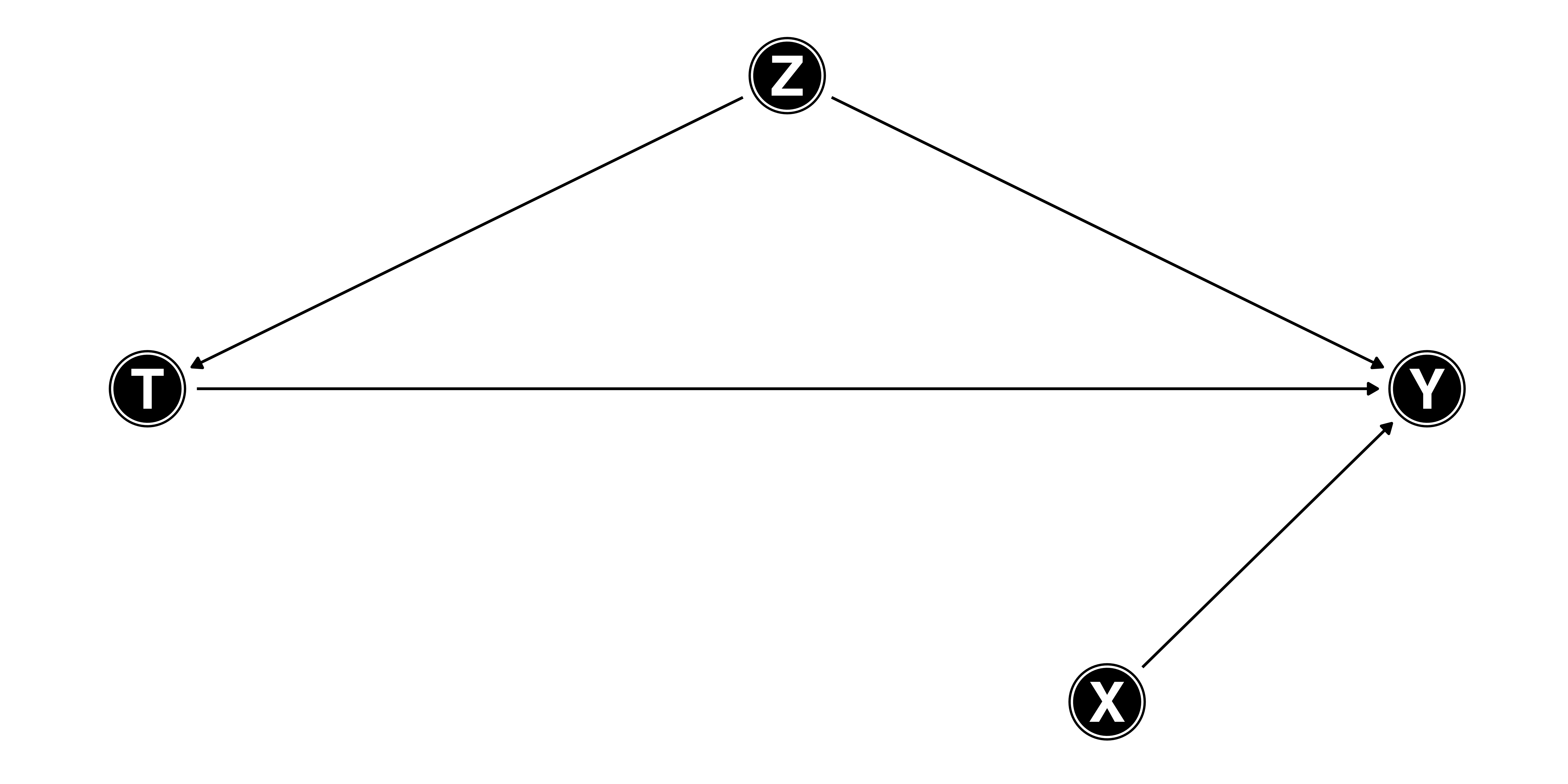
- \(T \rightarrow Y\): 直接効果
- \(T \rightarrow W \rightarrow Y\): 間接効果
- \(W\)は中間変数(mediate variable)
- 因果推論では主に全効果 (total effect) に関心があるため\(W\)は投入しない
- 全効果: 直接効果 + 間接効果
- \(T\)が変動したら\(W\)も必ず変わるため、\(T\)のみの効果はあまり意味なし
- 直接効果のみ推定する場合、\(W\)も統制
- 例) 就職市場における人種差別の例
- 結論: \(Z\)と\(X\)のみ統制
- 実は\(X\)は入れなくてもOK
ダイアグラムのツール
{ggdag}を用いた可視化
- 詳細は『私たちのR』第22章を参照