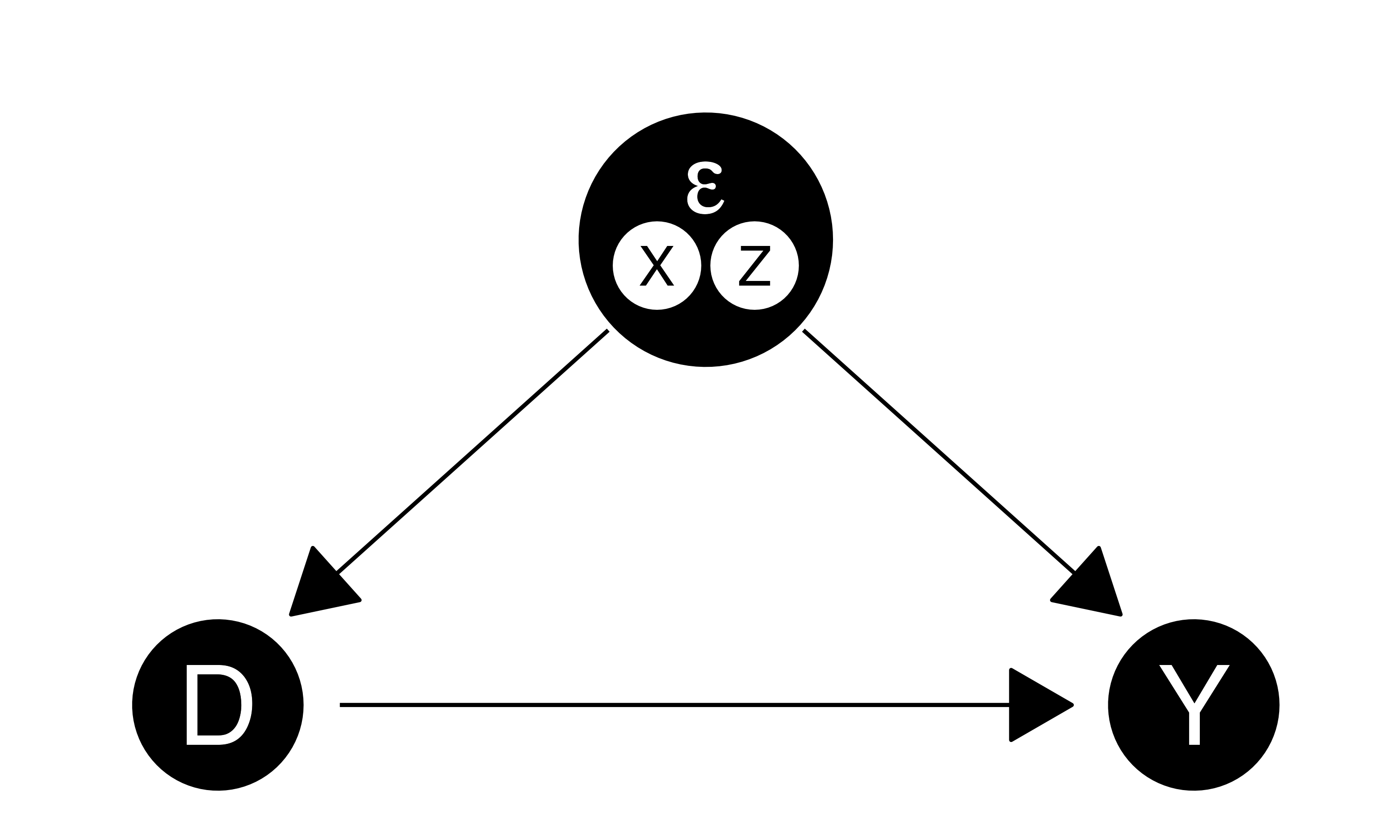
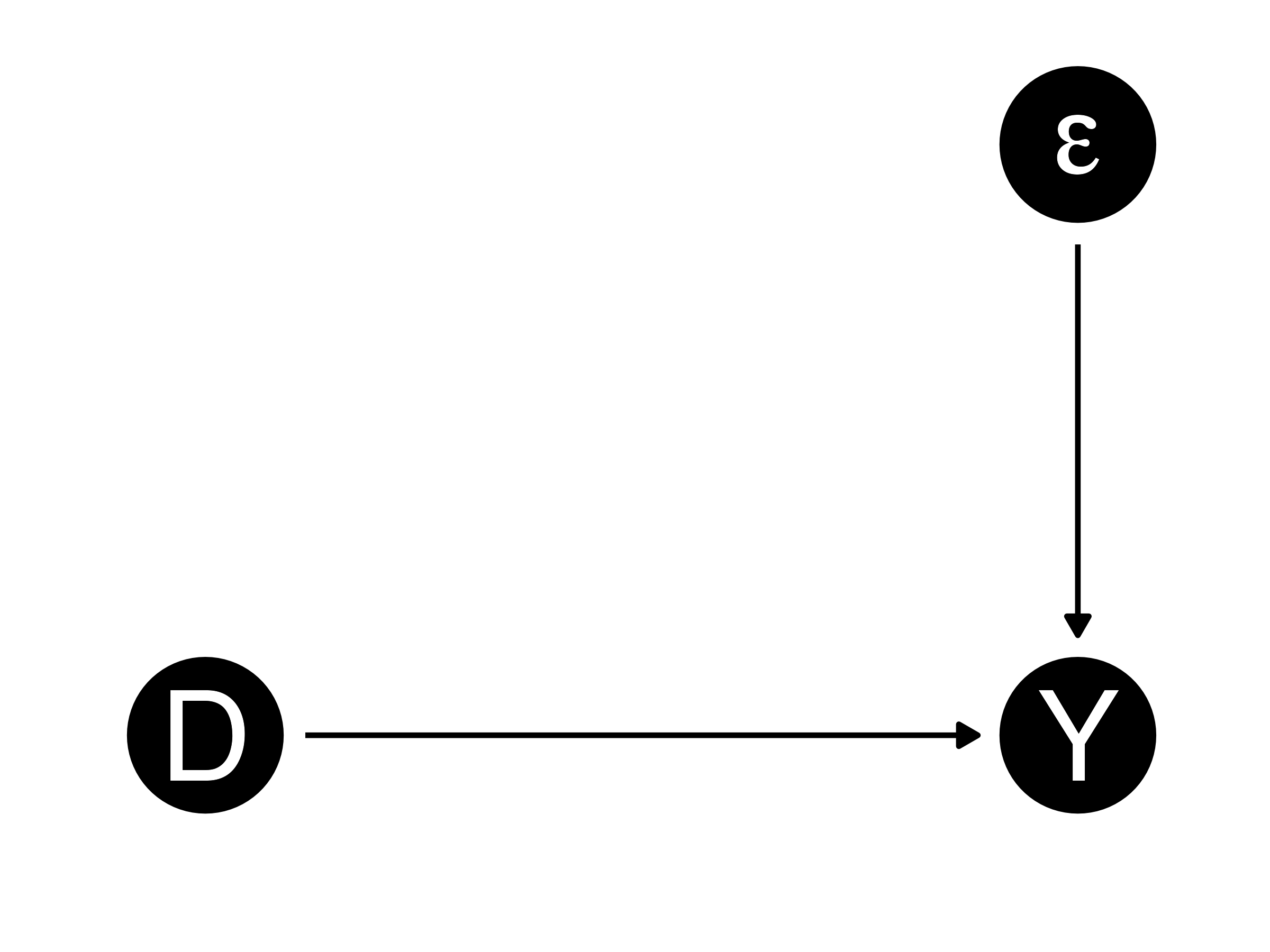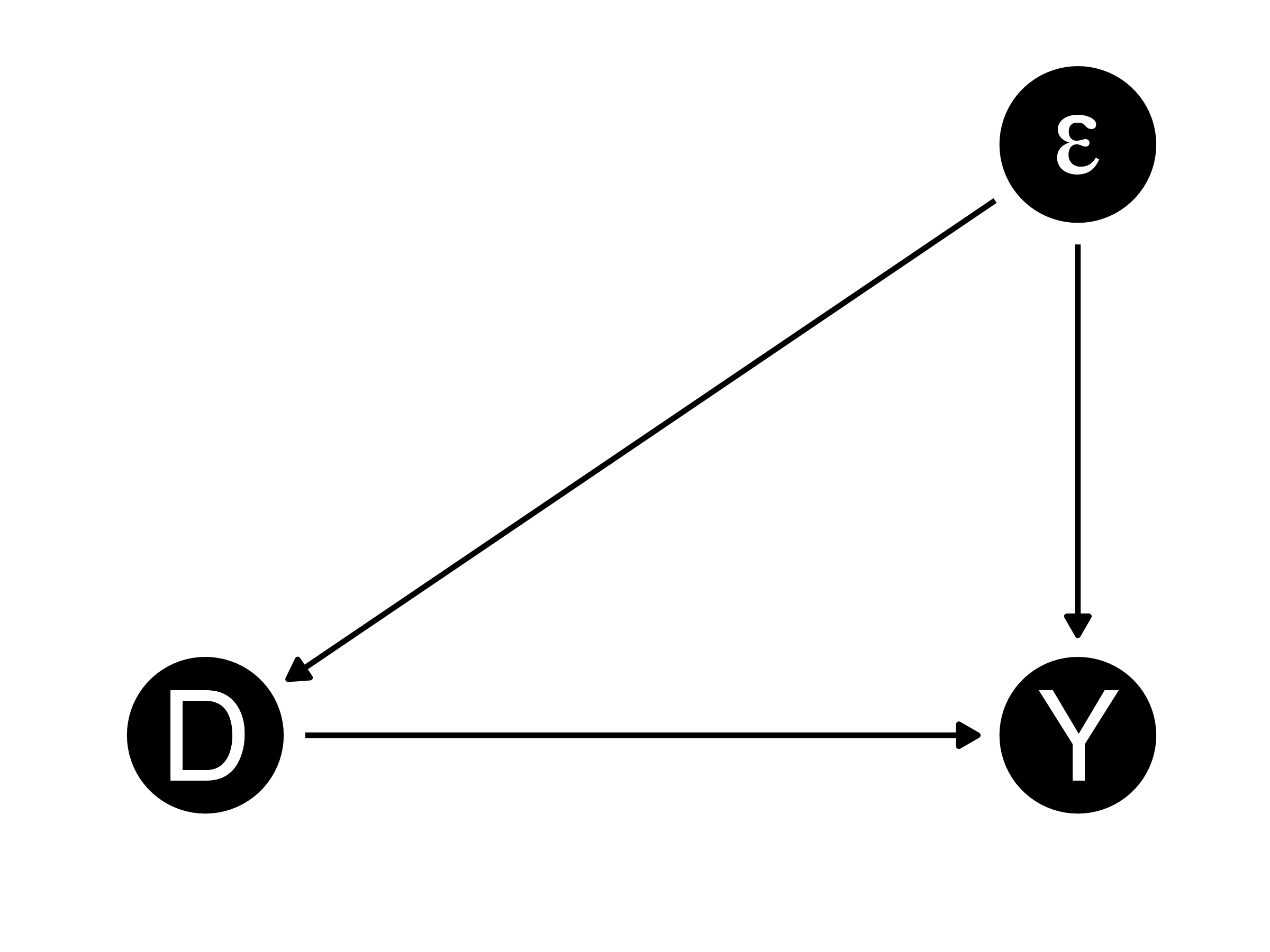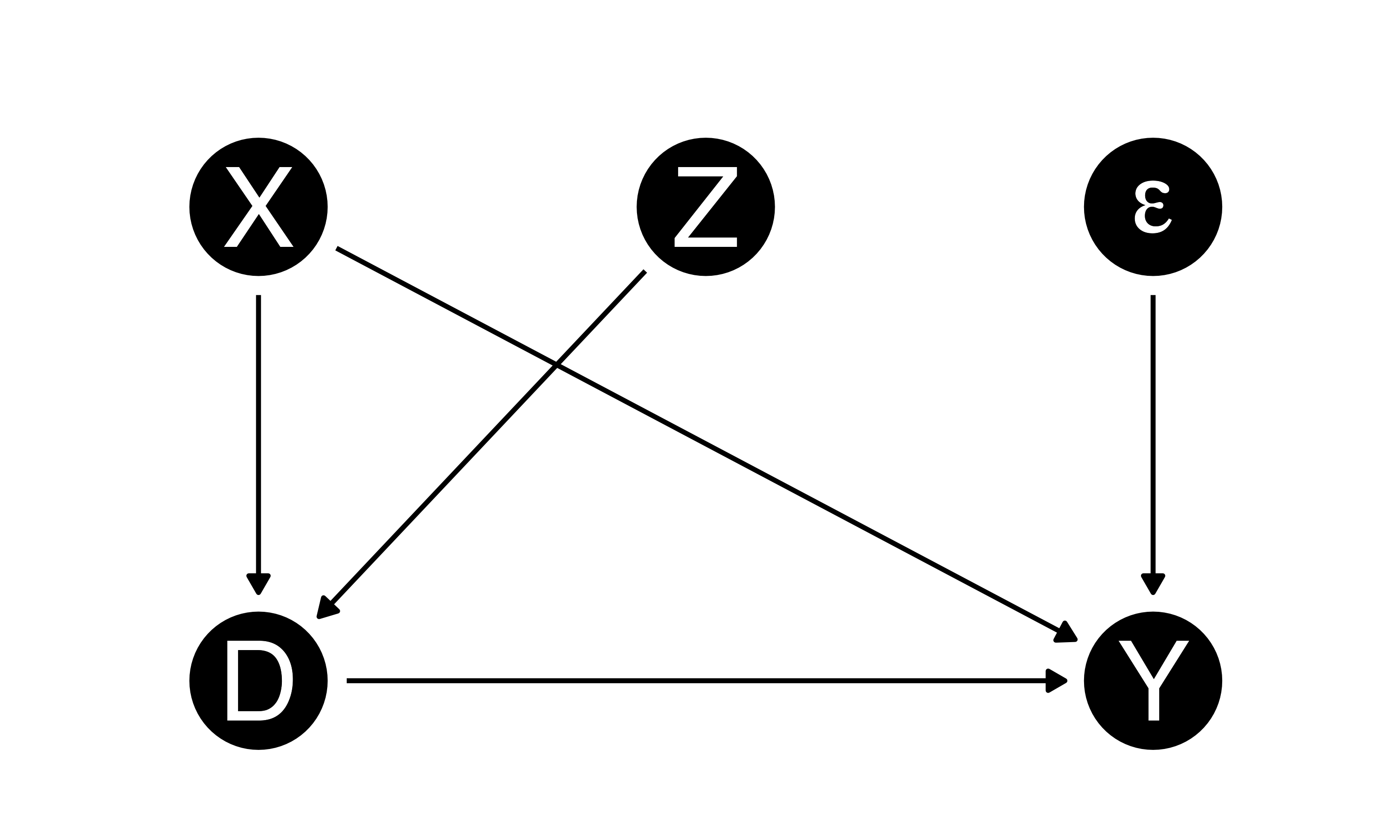セレクション・バイアスの定式化
- セレクション・バイアスが存在する場合、推定された因果効果(処置効果)にはセレクションによりバイアスを含む
- 推定された処置効果 = 真の処置効果 + セレクション・バイアス
- 推定対象がATTかATCかによって想定されるセレクション・バイアスが異なる
- ATT:処置群のおける処置効果(\(\mathbb{E}[Y_i(1) - Y_i(0) | D_i = 1]\))
- ATC:統制群のおける処置効果(\(\mathbb{E}[Y_i(1) - Y_i(0) | D_i = 0]\))
ATTとセレクション・バイアス
もともと優秀な人が宋さんの授業を取る(自己選択)
- \(\mathbb{E}[Y_i(0) | D_i = 1]\):処置群がもし処置を受けなかった場合の結果変数の期待値
- \(\mathbb{E}[Y_i(0) | D_i = 0]\):統制群における結果変数の期待値(観察可能)
\[
\begin{align}
& \mathbb{E}[Y_i | D_i = 1] - \mathbb{E}[Y_i | D_i = 0] \\
= & \mathbb{E}[Y_i(1) | D_i = 1] - \mathbb{E}[Y_i(0) | D_i = 0] \\
= & \mathbb{E}[Y_i(1) | D_i = 1] \textcolor{red}{- \mathbb{E}[Y_i(0) | D_i = 1] + \mathbb{E}[Y_i(0) | D_i = 1]} - \mathbb{E}[Y_i(0) | D_i = 0] \\
= & \underbrace{\mathbb{E}[Y_i(1) - Y_i(0) | D_i = 1]}_{\textsf{ATT}} + \underbrace{\mathbb{E}[Y_i(0) | D_i = 1] - \mathbb{E}[Y_i(0) | D_i = 0]}_{\textsf{selection bias}}
\end{align}
\]
ATCとセレクション・バイアス
授業の効果が高そうな人が宋さんの授業を取る(最適化選択)
- \(\mathbb{E}[Y_i(1) | D_i = 1]\):処置群における結果変数の期待値(観察可能)
- \(\mathbb{E}[Y_i(1) | D_i = 0]\):統制群がもし処置を受けたら場合の結果変数の期待値
\[
\begin{align}
& \mathbb{E}[Y_i | D_i = 1] - \mathbb{E}[Y_i | D_i = 0] \\
= & \mathbb{E}[Y_i(1) | D_i = 1] - \mathbb{E}[Y_i(0) | D_i = 0] \\
= & \mathbb{E}[Y_i(1) | D_i = 1] \textcolor{red}{- \mathbb{E}[Y_i(1) | D_i = 0] + \mathbb{E}[Y_i(1) | D_i = 0]} - \mathbb{E}[Y_i(0) | D_i = 0] \\
= & \underbrace{\mathbb{E}[Y_i(1) | D_i = 1] - \mathbb{E}[Y_i(1) | D_i = 0]}_{\textsf{selection bias}} + \underbrace{\mathbb{E}[Y_i(1) - Y_i(0) | D_i = 0]}_{\textsf{ATC}}
\end{align}
\]
ATT、ATCの識別条件
以下の2つの条件がすべて満たされる場合、ATEが推定可能
- ATTの識別条件
- \(\mathbb{E}[Y_i(0) | D_i = 1] = \mathbb{E}[Y_i(0) | D_i = 0]\)
- この場合、ATT = \(\mathbb{E}[Y_i(1) | D_i = 1] - \mathbb{E}[Y_i(0) | D_i = 0]\)
- ATCの識別条件
- \(\mathbb{E}[Y_i(1) | D_i = 1] = \mathbb{E}[Y_i(1) | D_i = 0]\)
- この場合、ATC = \(\mathbb{E}[Y_i(1) | D_i = 1] - \mathbb{E}[Y_i(0) | D_i = 0]\)
- これらは経験的に観察できず、理論的に説得する必要がある
- 前者の方が説得しやすいケースが多いので、ATTを推定するケースが多い
- 「もともと優秀な人が宋さんの授業を取る」と「授業の効果が高そうな人が宋さんの授業を取る」
その他のセレクションの例
手元のサンプルが「授業効果が高そうな学生(\(i \in \{1, 2, 4, 7, 8\}\))」だけなら…?
- 真の処置効果は0だが、この場合、処置効果は必ず正になる
- \(\Rightarrow\) 偏ったサンプリングによるバイアス(サンプルセレクション・バイアス)
| 1 |
500 |
550 |
50 |
| 2 |
200 |
300 |
100 |
| 3 |
800 |
750 |
-50 |
| 4 |
300 |
400 |
100 |
| 5 |
300 |
200 |
-100 |
| 6 |
550 |
450 |
-100 |
| 7 |
700 |
750 |
50 |
| 8 |
400 |
600 |
200 |
| 9 |
500 |
300 |
-200 |
| 10 |
600 |
550 |
-50 |
| 平均 |
|
|
0 |
セレクションへの対処
- 無作為抽出(random sampling)
- サンプルセレクション・バイアス(サンプリング・バイアス)が存在する場合
- ランダム割り当て(無作為割当; random assignment)
- あらゆる内生性を(理論上)完全に除去できる因果推論の王道
- 統計的因果推論(statistical causal inference)