社会科学における因果推論
8/ 差分の差分法
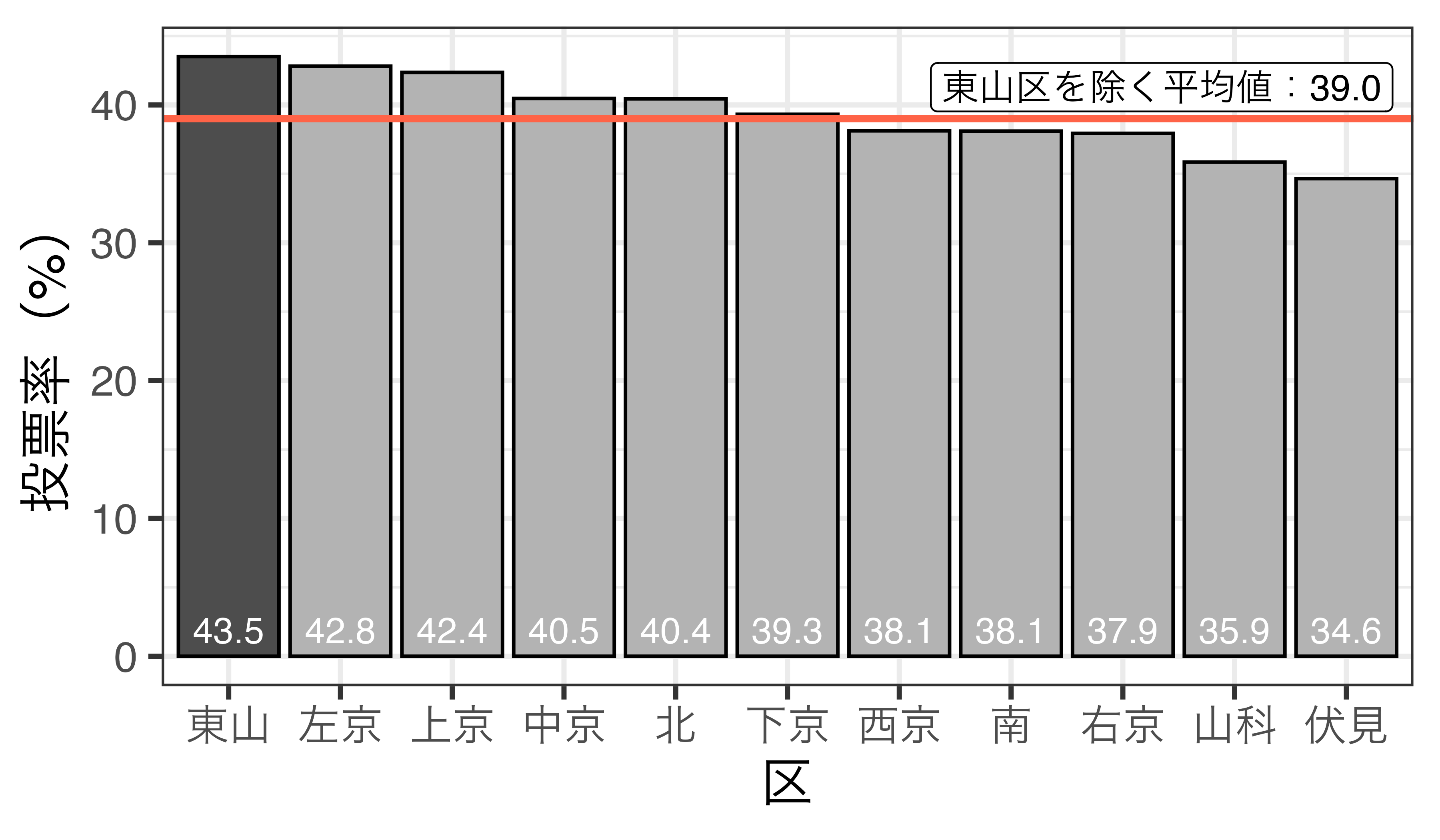
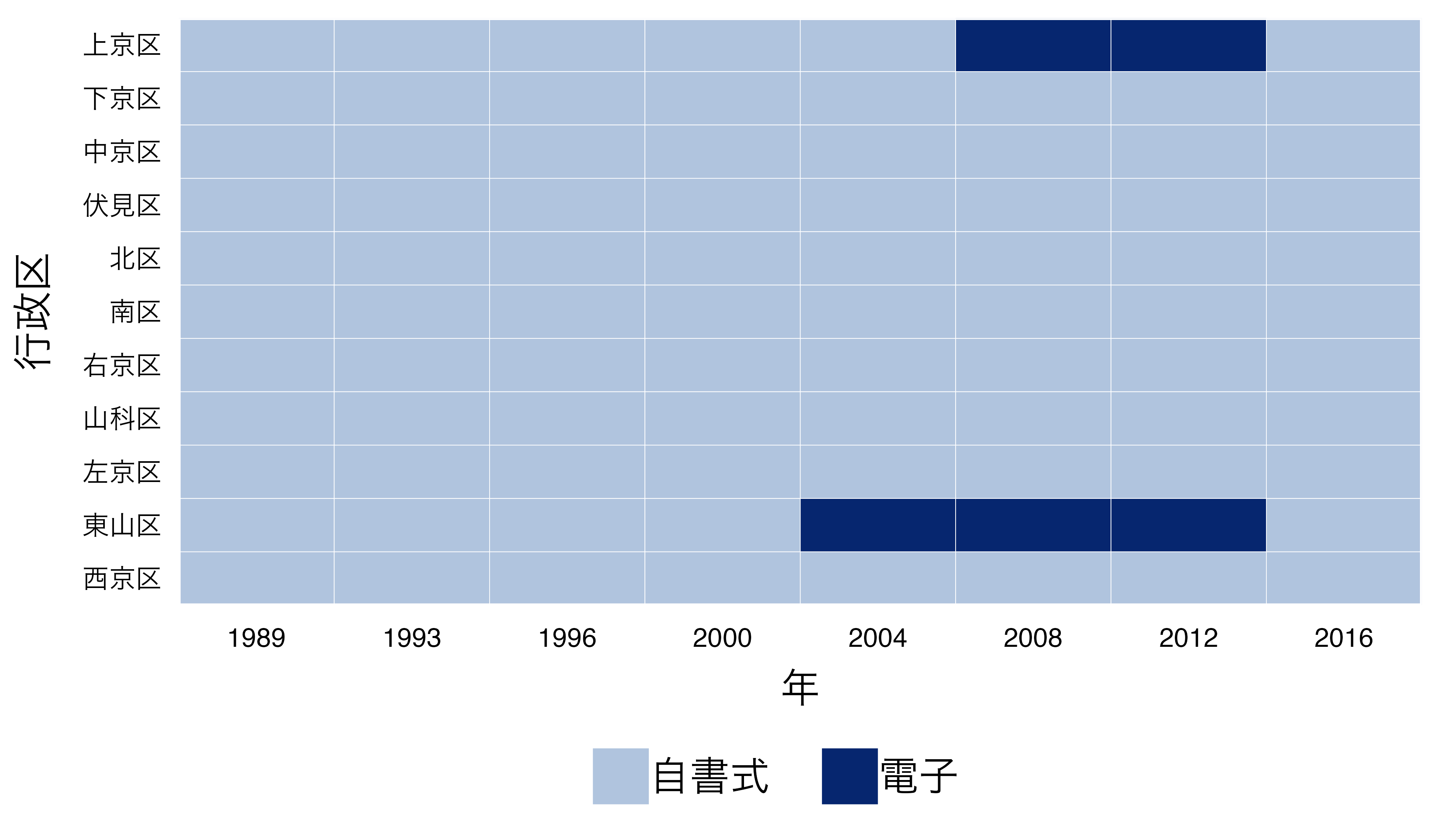
電子投票の導入と投票率
2004年京都市長選挙における電子投票の導入1
- 11の行政区の内、東山区のみ導入
- タッチパネル式投票(投票所に足を運ぶ必要はある)


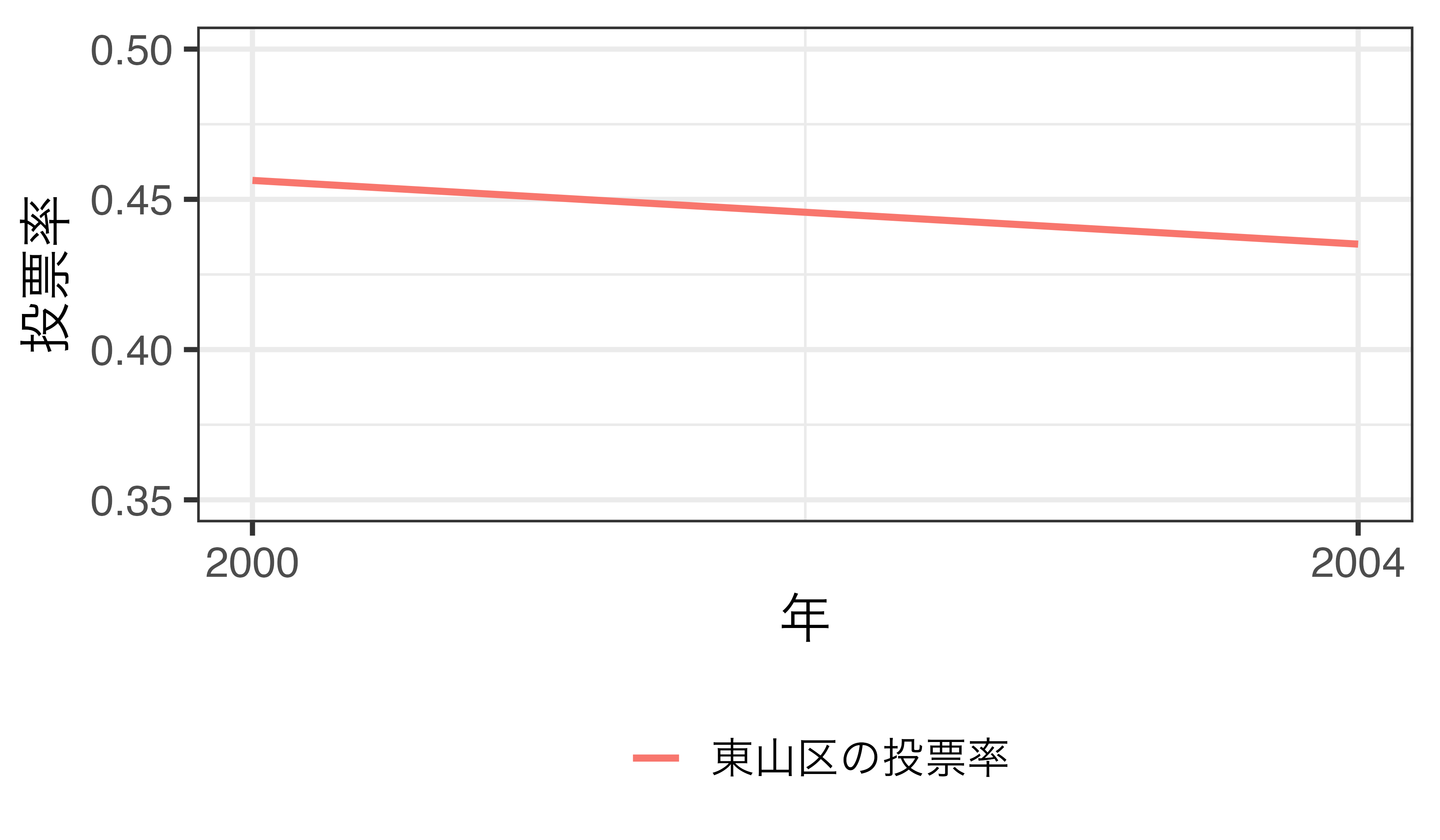
東山区の投票率(経時的変化)
- 電子投票導入後、投票率が約2.1%p減少(45.6% \(\rightarrow\) 43.5%)
- 電子投票は投票率を下げる?
内生性

- 電子投票の導入は選管が決めるため、自己選択バイアスの可能性がある。
- \(\Rightarrow\) 電子投票と投票率間の交絡要因は?
- どのような場合に選管は電子投票の導入を検討するか。
自己選択バイアスの例(1)

- 東山区の投票率は元々低く、選管が投票率向上のために電子投票を導入
- 元々投票率の低い地域は次の選挙の投票率も低い傾向
- 電子投票のおかげで2.1%p減で食い止められたかも
- \(\Rightarrow\) 単純前後比較には限界があり、比較対象が必要
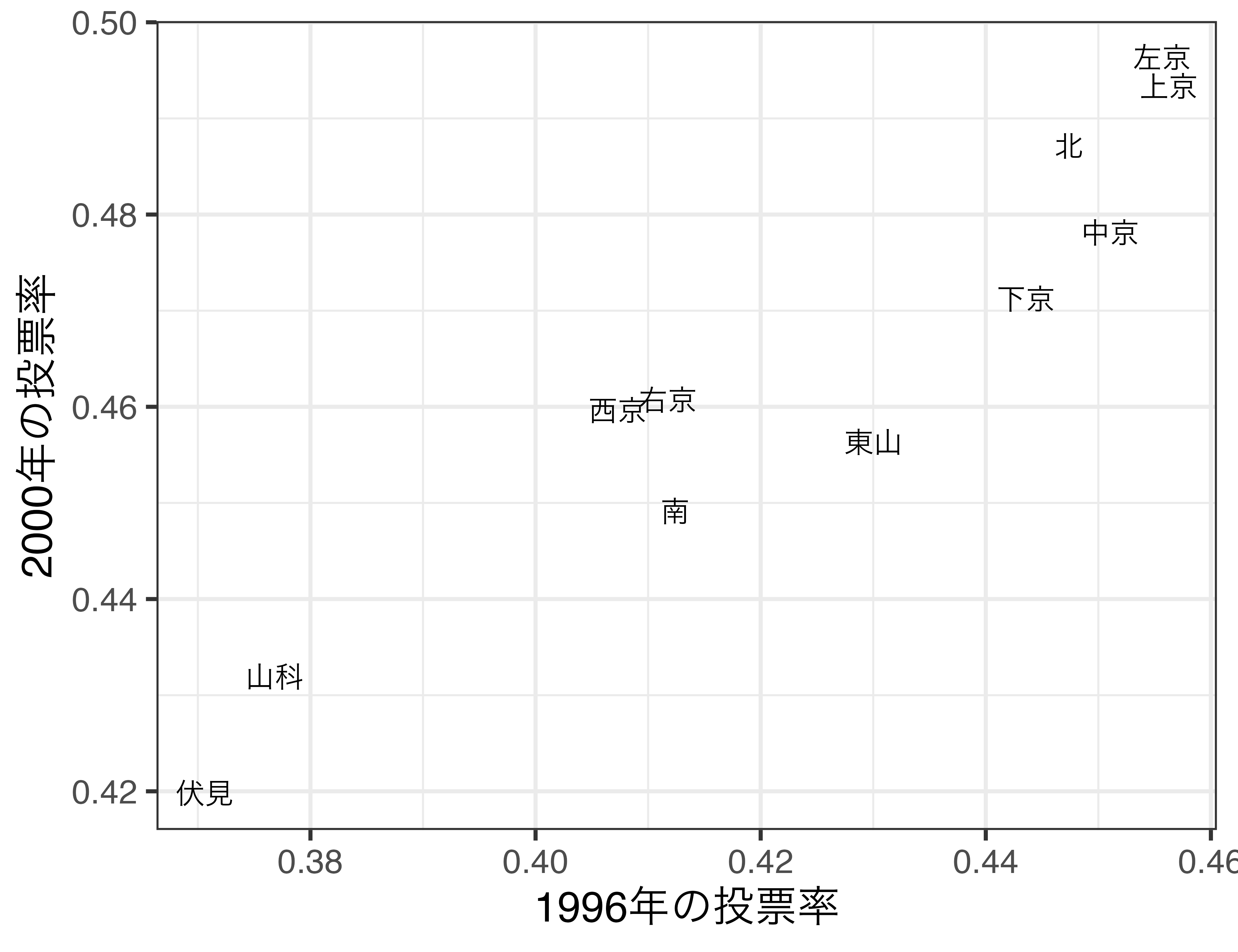
東山区の投票率(群間比較)
- 電子投票を導入した東山区の投票率は導入しなかった区に比べ、約4.5%p高い
- 電子投票は投票率を上げる?
自己選択バイアスの例(2)

- 東山区の選管は投票参加の重要性を認識
- \(\Rightarrow\) 東山区は元々投票率が高かった可能性 & 更に投票率を上げるための方法を導入
- 電子投票がなくても東山区は投票率が高い可能性
- \(\Rightarrow\) 単純群間比較には限界があり、比較対象が必要
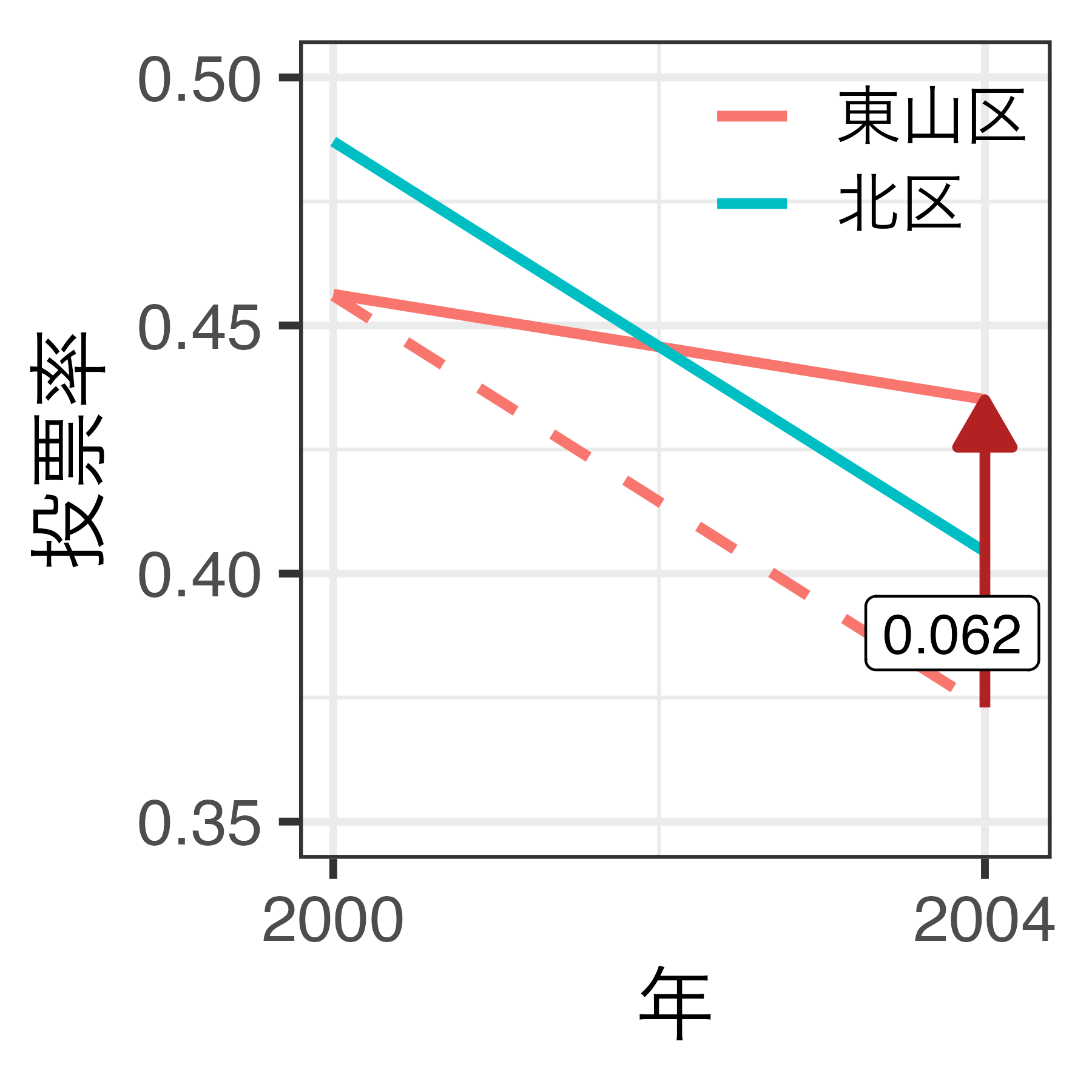
前後 + 群間比較
- 同時期における北区の投票率は約8.3%p減少(48.7% \(\rightarrow\) 40.4%)
- 電子投票は投票率を下げる? \(\rightarrow\) そうじゃないかも知れない。
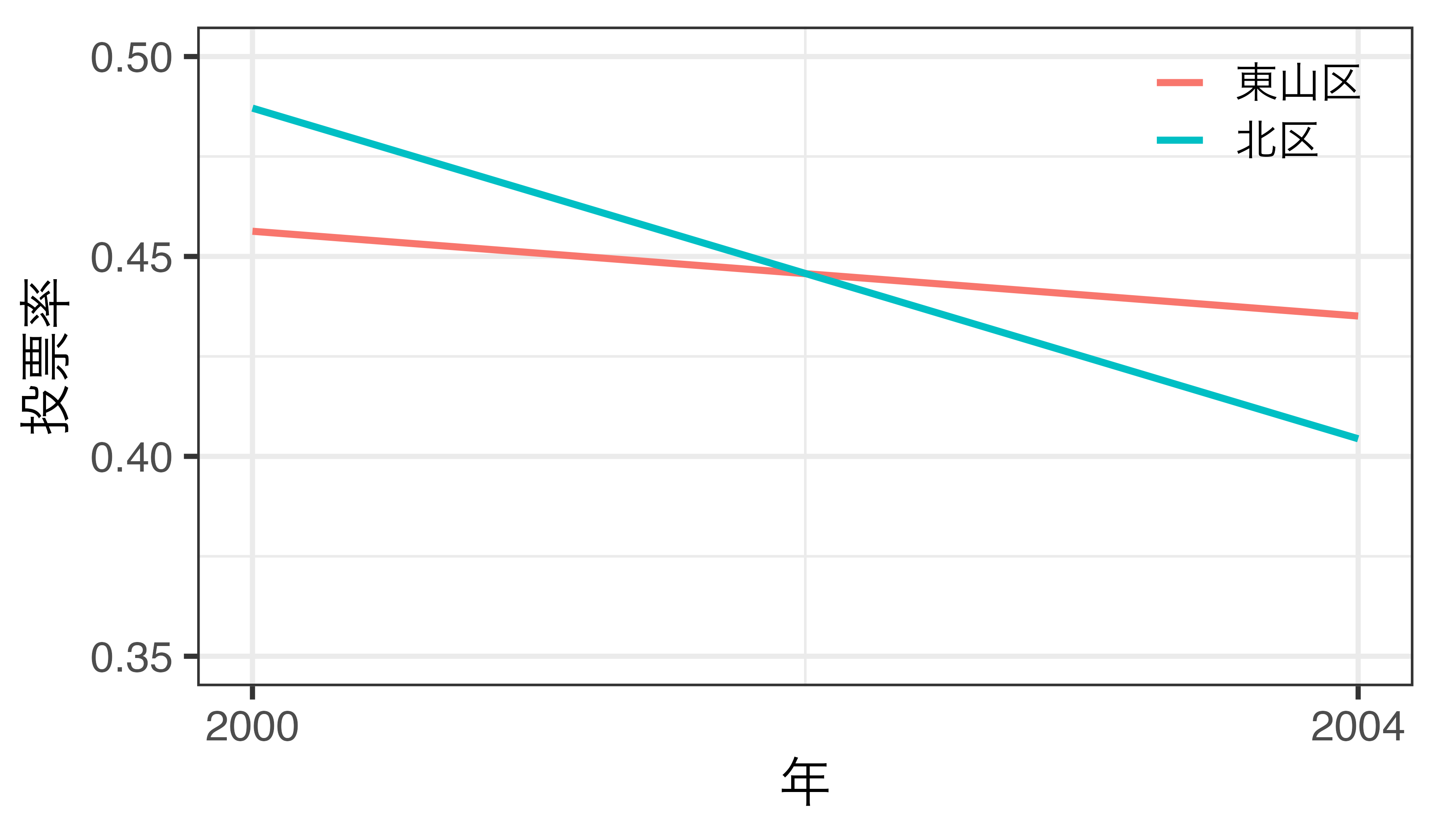
仮定が満たされる場合
- 処置を受けるまでは東山区と北区の投票率のトレンドが平行
- 北区が東山区の反実仮想として使える
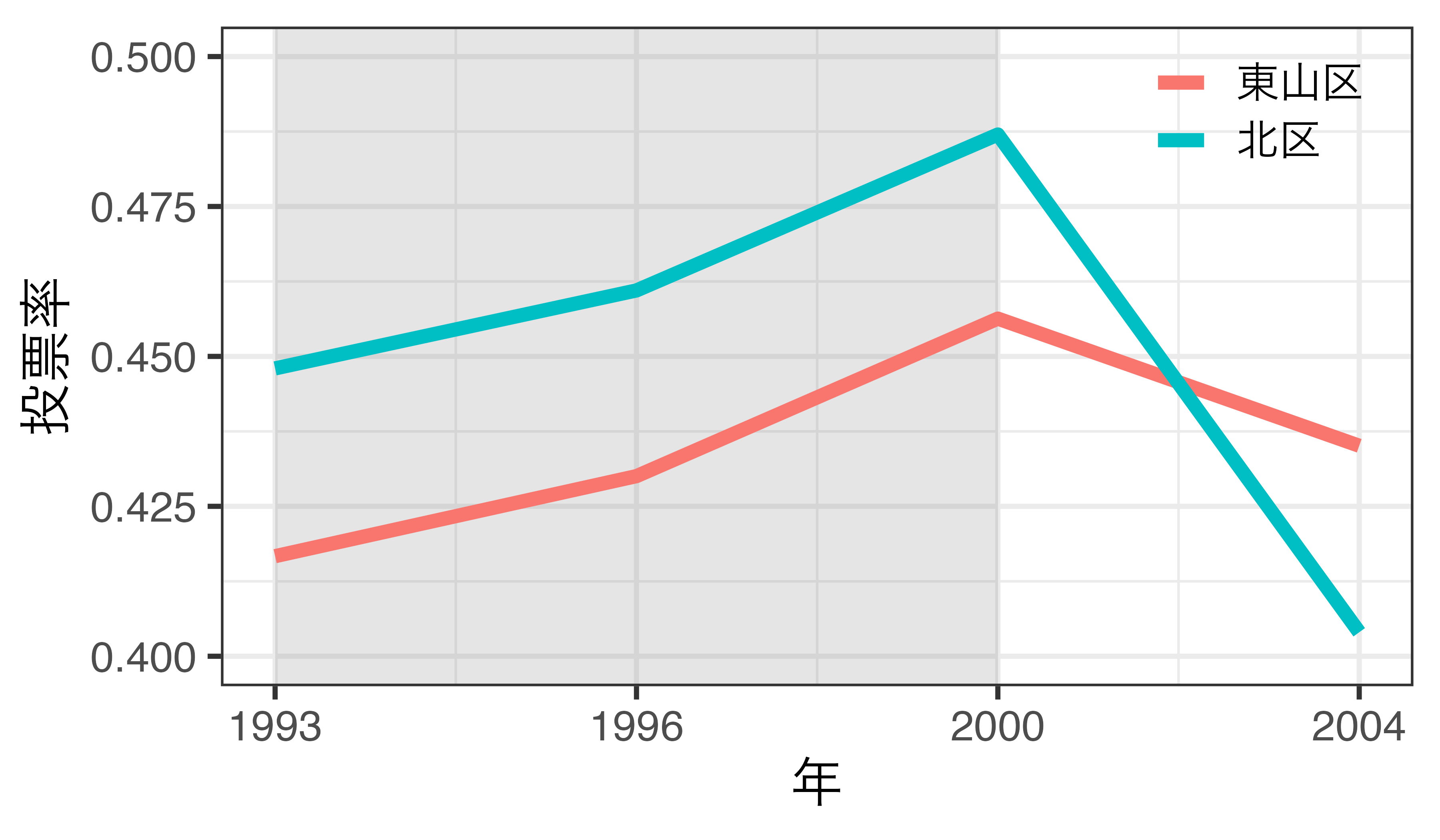
仮定が満たされない場合
- 処置を受けるまで東山区と北区の投票率のトレンドが平行でない
- 北区を東山区の反実仮想として使うことは不適切
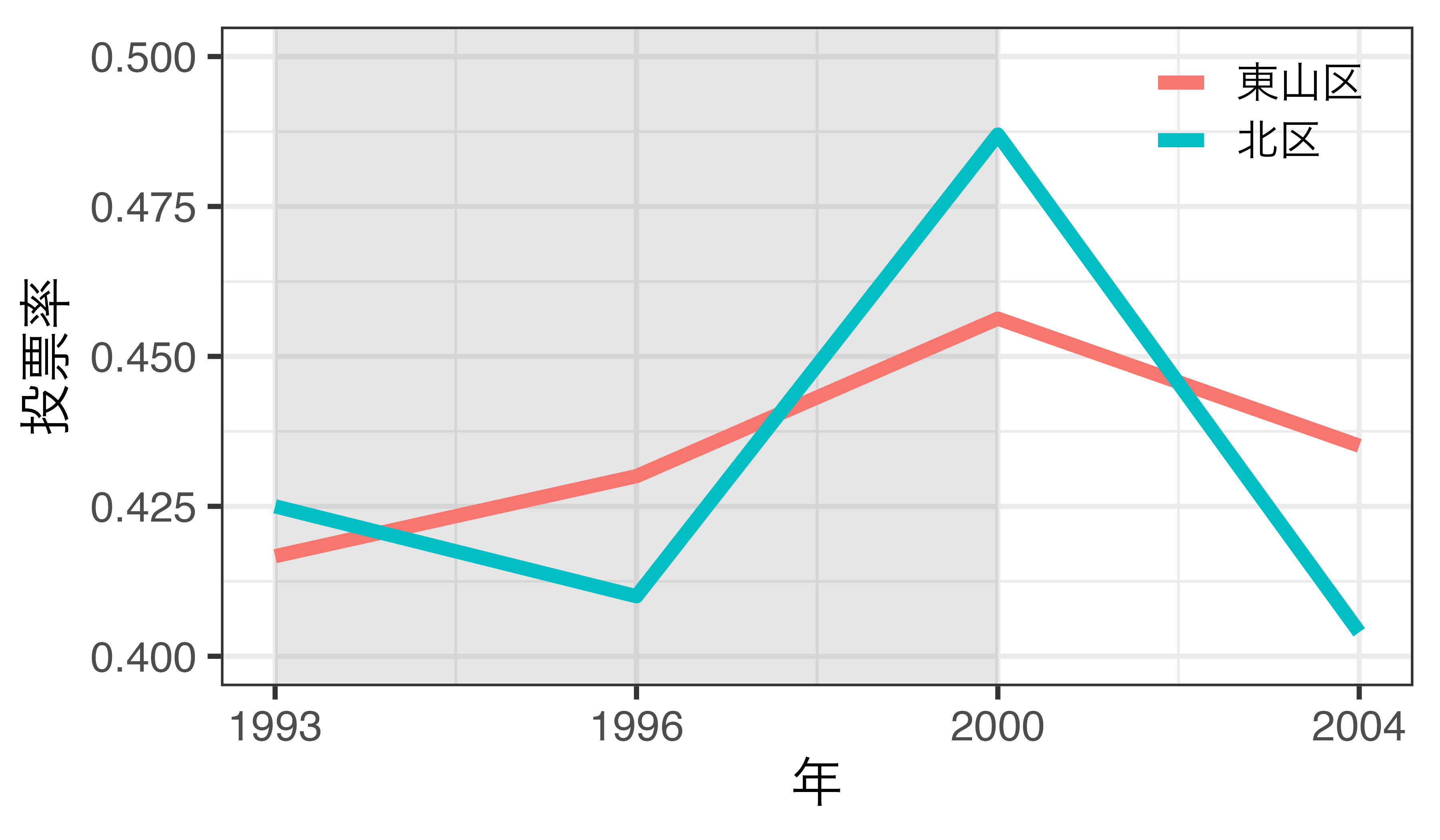
可視化による確認
- 長期間であるほど、統制群の個体が多いほど確認しやすい
- 人為的な解釈が必要であり、並行トレンドの仮定に対する示唆的根拠(suggestive evidence)に過ぎない
- プラセボテストで並行トレンドの仮定が満たされていないことは検知可能(後述)

系列相関の例
トレンド変数の必要性
- 左:トレンド変数がなくてもOK
- 右:トレンド変数を投入することである程度バイアスが小さくなる
- \(\Rightarrow\) 並行トレンドの仮定の緩和

トレンド変数と反実仮想
- 左:トレンド変数を投入していないモデル
- 右:トレンド変数を投入したモデル

共変量が必要な時
- 3期以上のパネルデータを使用したDIDの場合、未観察の交絡要因が時間不変(no time-varying confounders)であることが前提
- この仮定が満たされない場合、共変量を投入することが推奨される
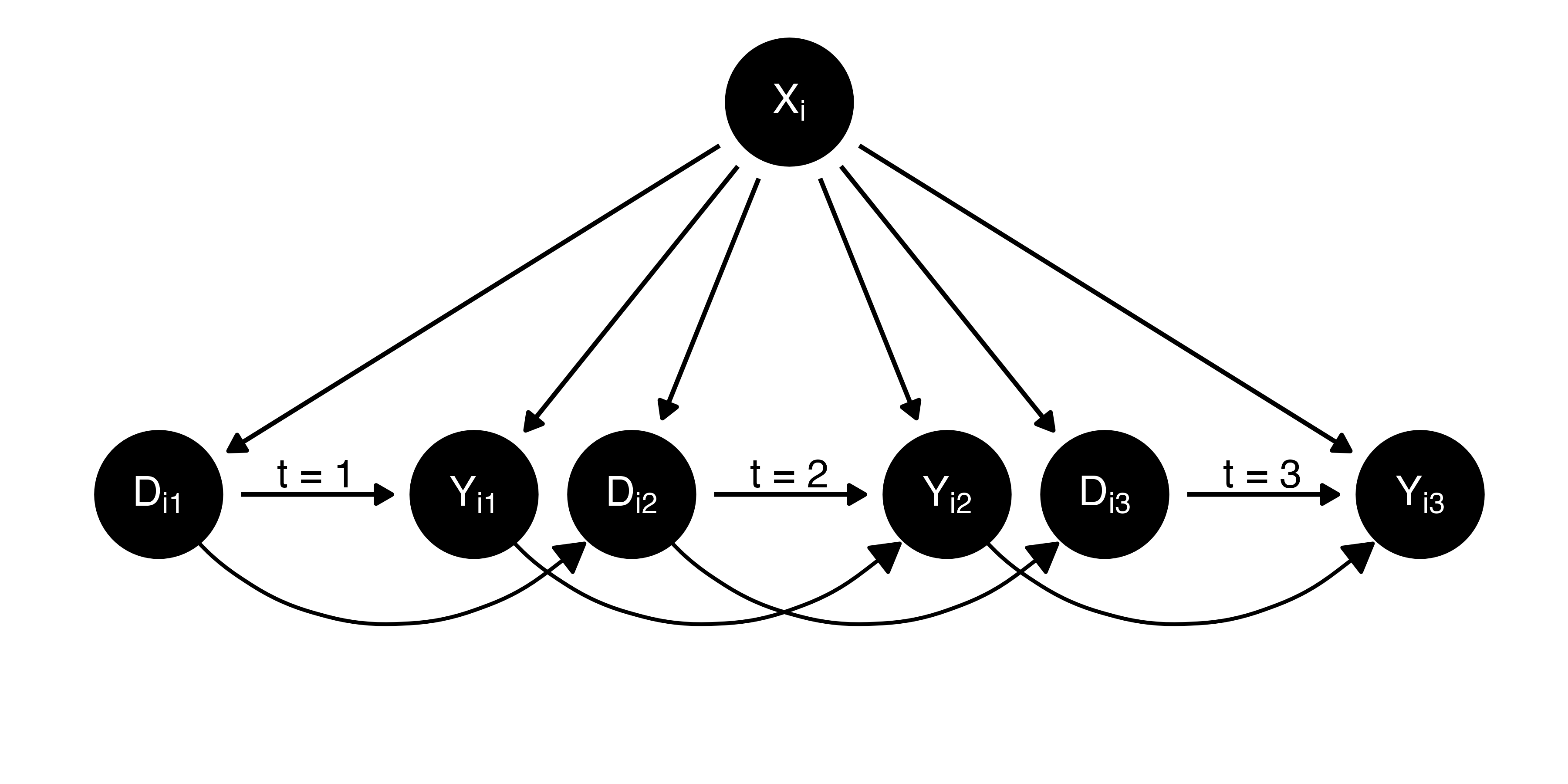
共変量の投入
- 時間と共に変化する交絡要因(time-varying confounder)の投入
- 適切な共変量を投入すると条件付き並行トレンドの仮定が成立
- トレンド変数と共変量、両方投入しても良い

パネルデータの確認
- 個体 \(\times\) 時間 \(\times\) 処置有無の可視化(以下は{panelView}パッケージを使用した例)
García-Montoya et al. (2022)
- 3種類の処置変数 \(\times\) 4つのモデル
並行トレンドは?
- どうみても平行トレンドの仮定が満たされているとは言い難い。
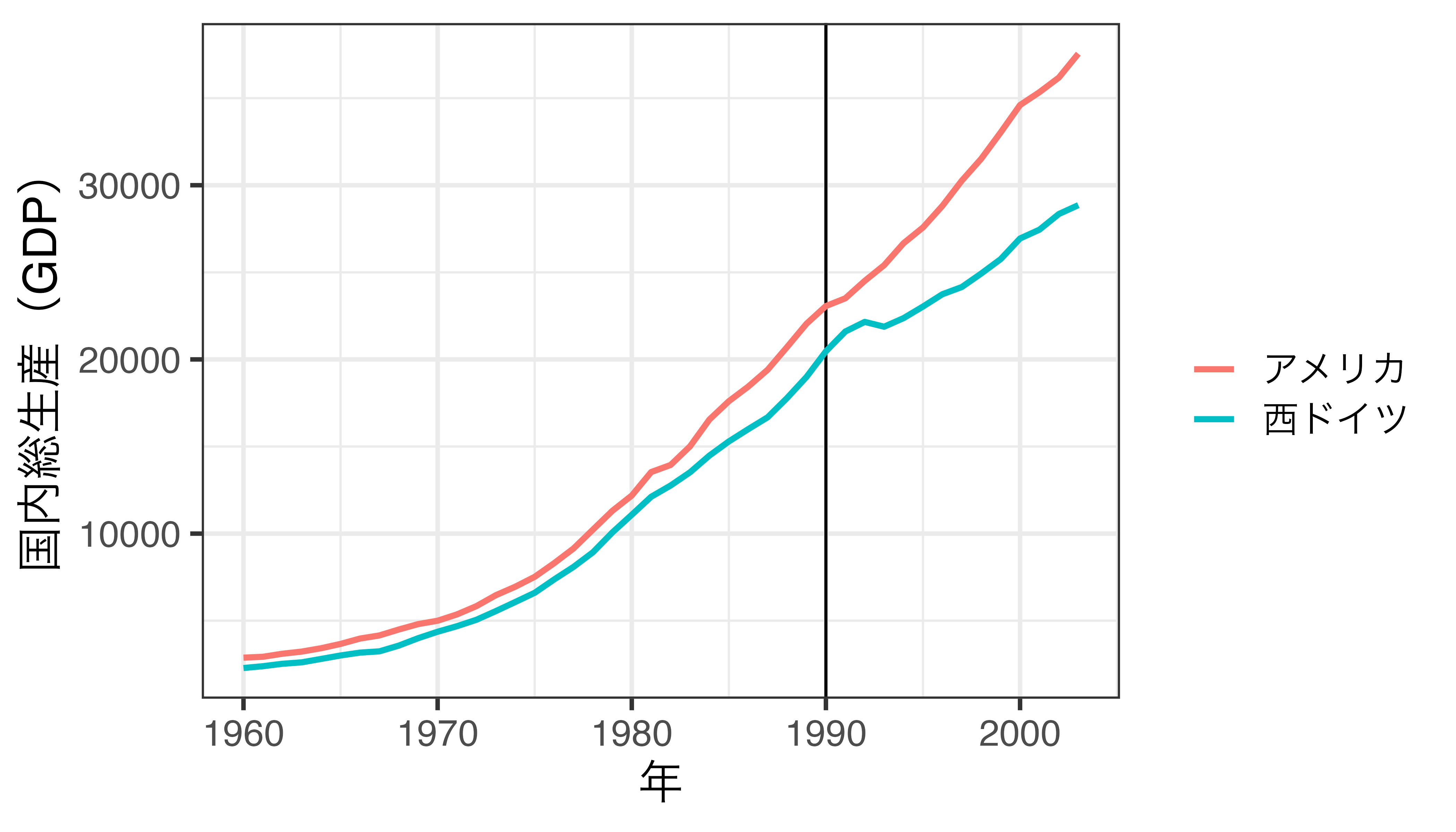
たくさんの統制群を用意する
- 一つ一つの線は西ドイツと平行でないかも知れないが、重み付けで合成すれば西ドイツのトレンドを追従するトレンドが作れそう。
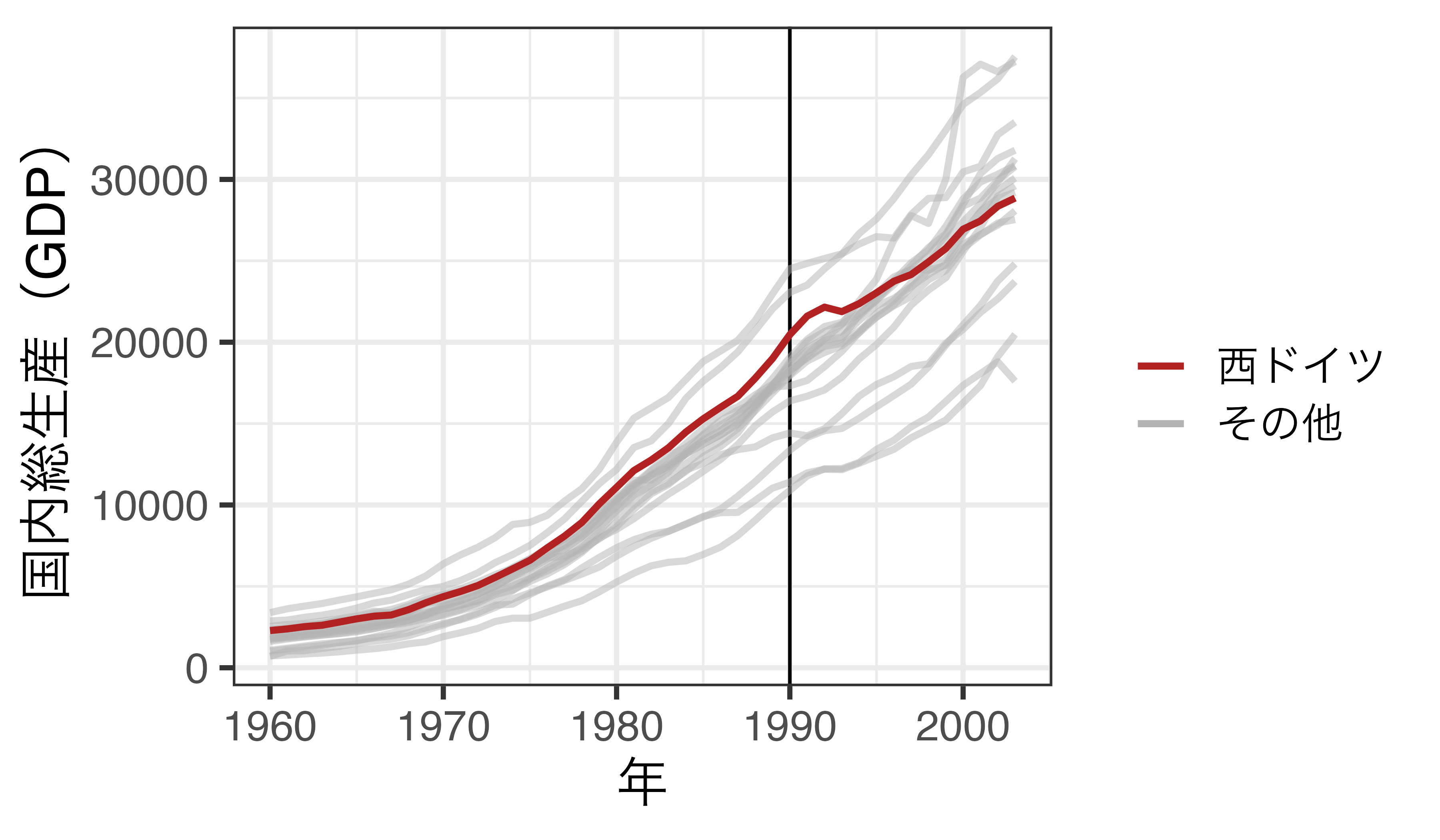
統制群の合成
統制群に重みを付けて合成する
- 通常のSCMの場合、重みは必ず正であるが、一般化SCM(Xu 2017)の場合、負もあり得る。
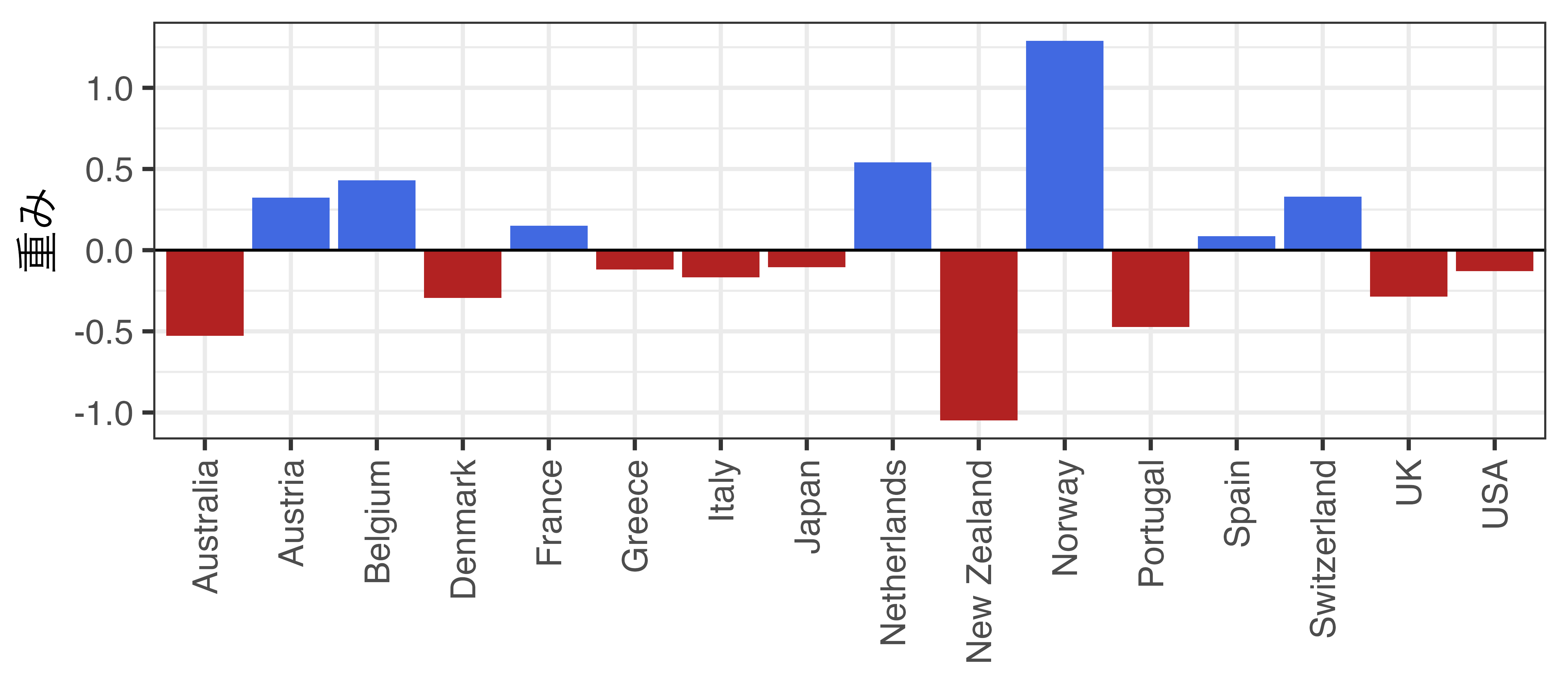
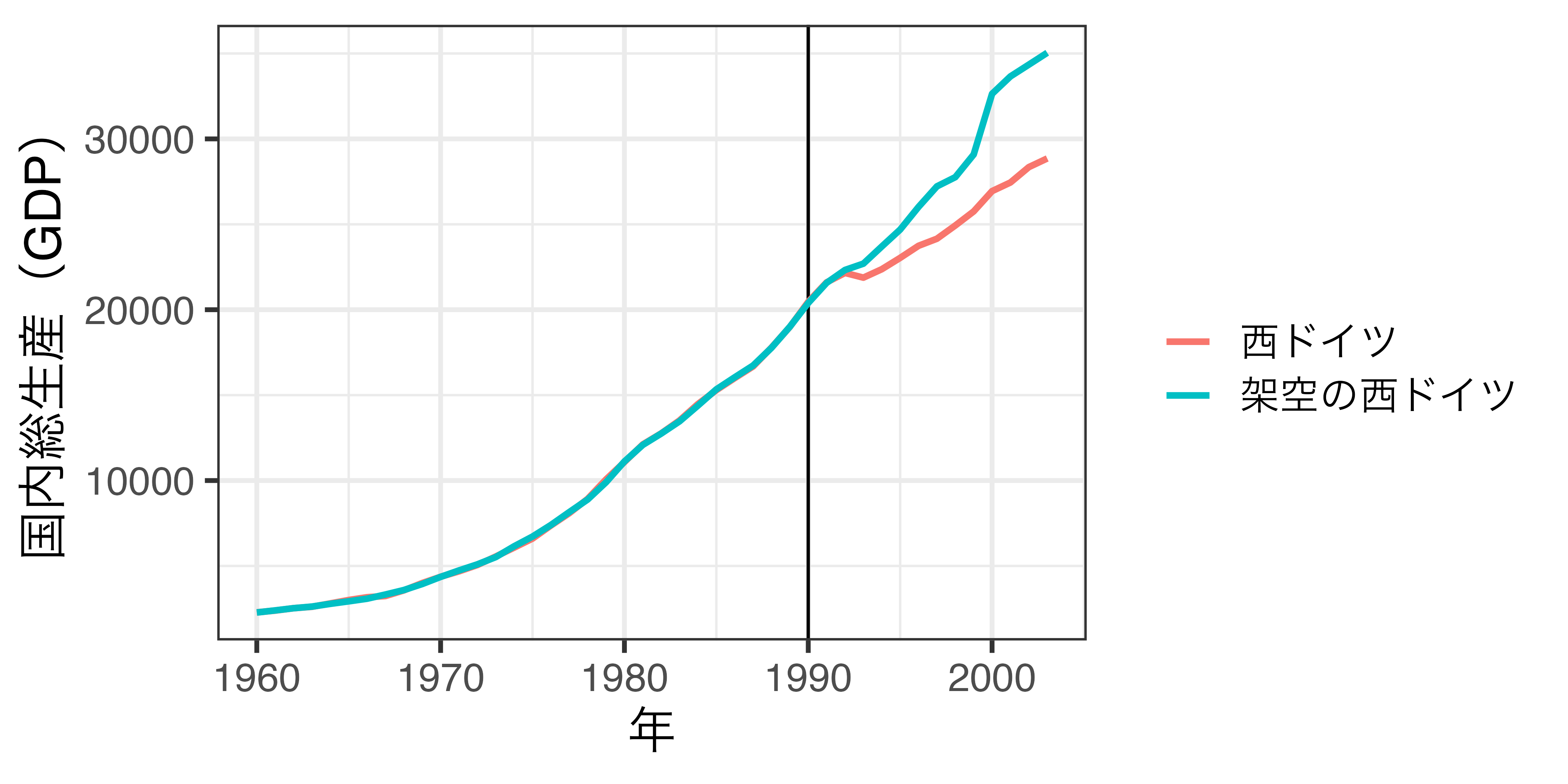
合成された架空の西ドイツ
統一(1990年)までのトレンドが類似(しているように見える)
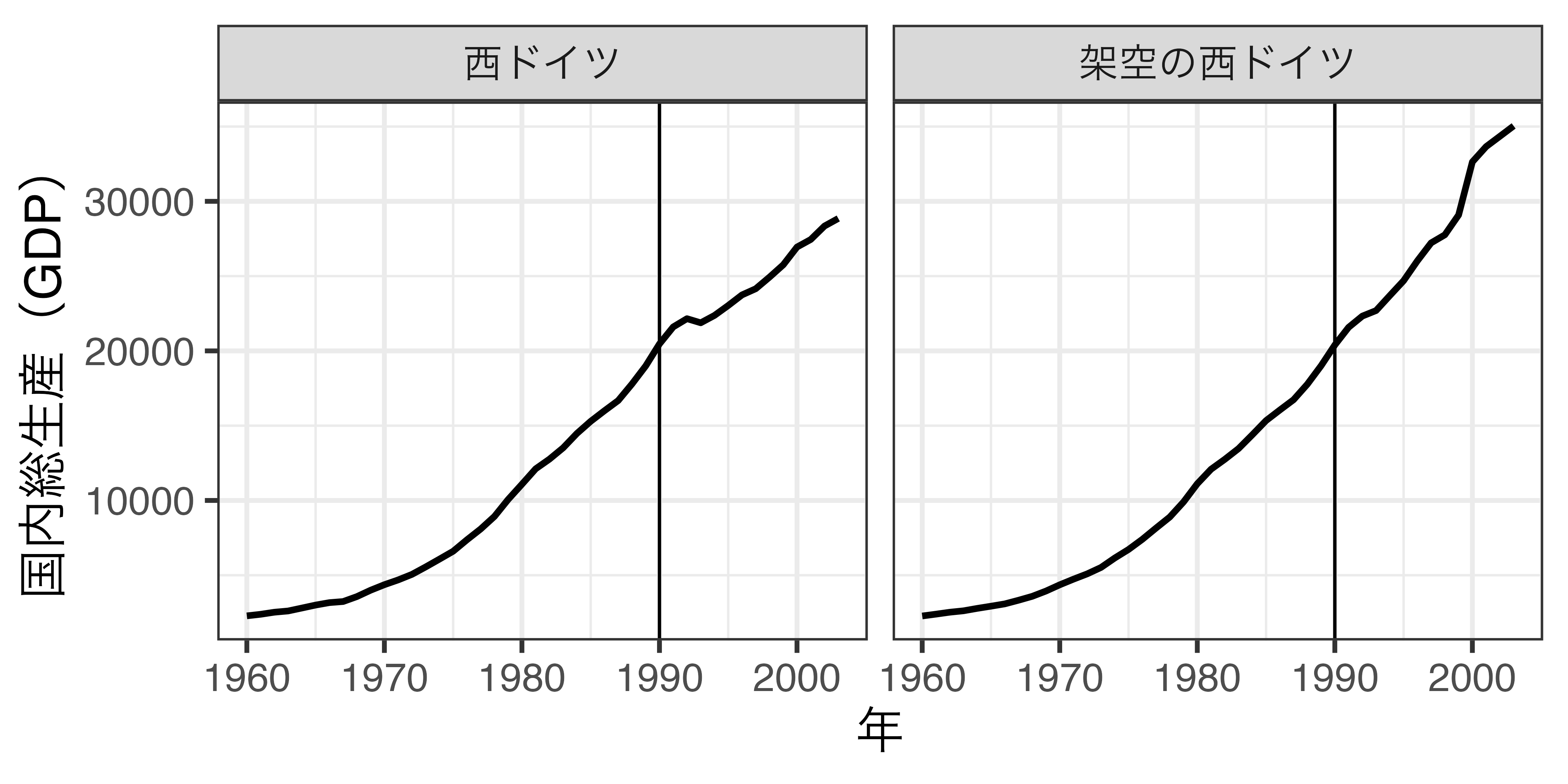
比較
統一するまでのトレンドがほぼ一致
- 架空の西ドイツは西ドイツの反実仮想(統一しなかった西ドイツ)として適切
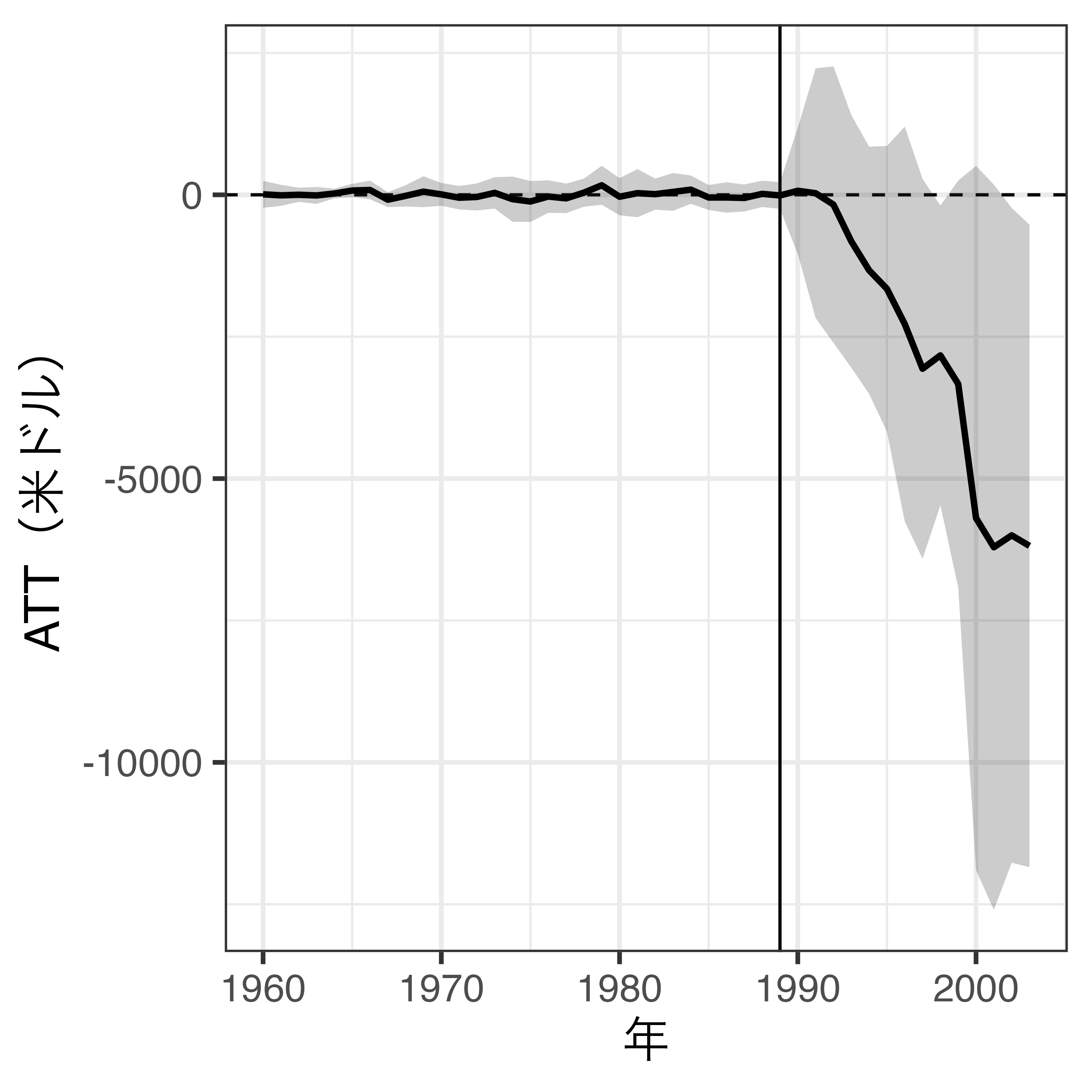
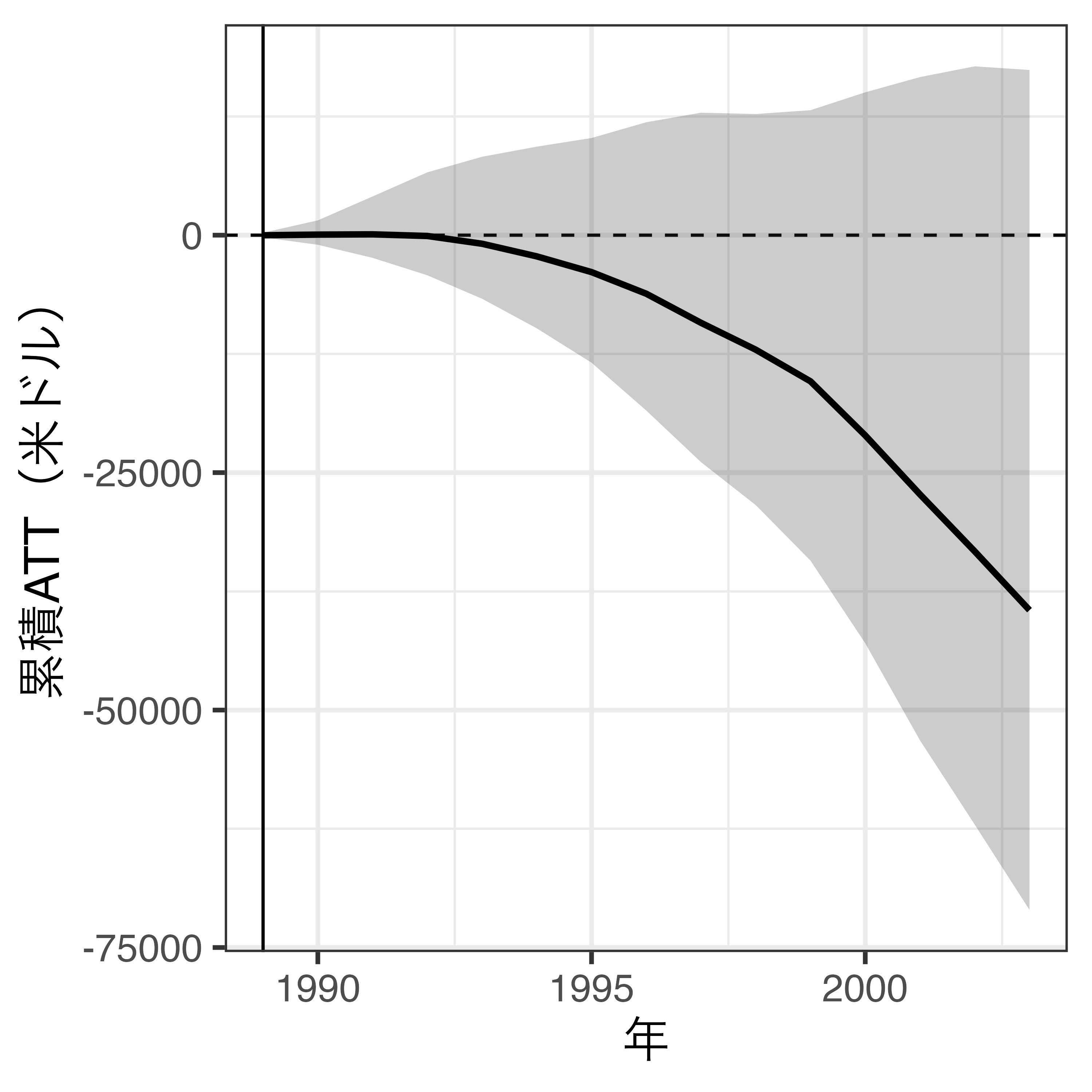
ATTの可視化
- 左:各時点ごとのATT
- 右:各時点における累積ATT(処置後のみ)